 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMTCNET: Multi-task Learning Paradigm for Crowd Count Estimation
Aug 23, 2019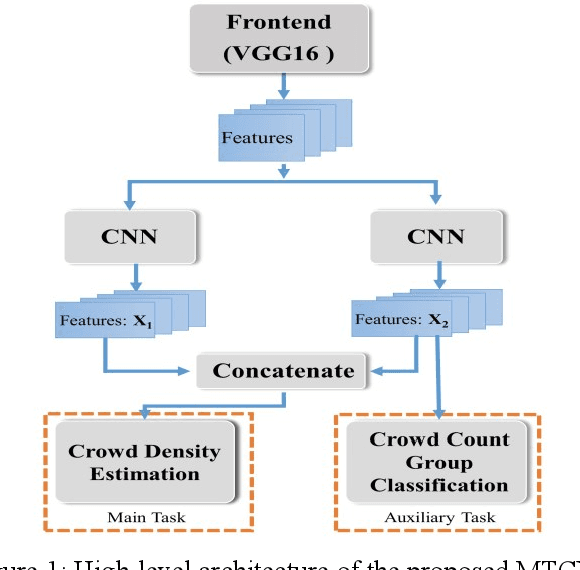
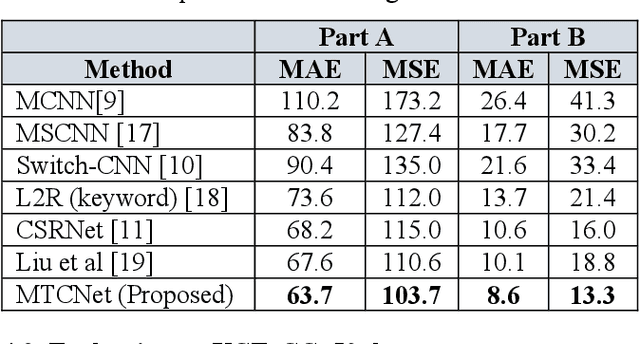

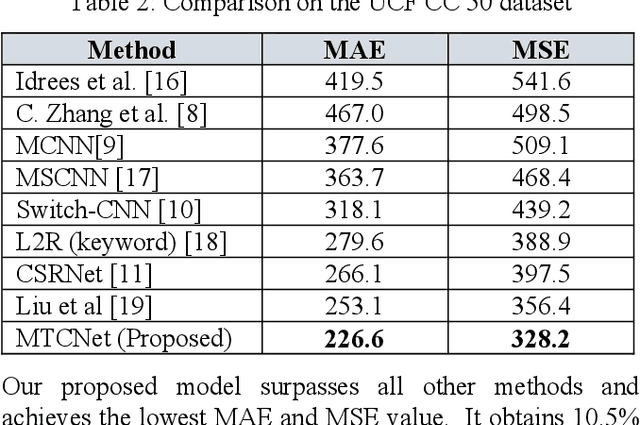
We propose a Multi-Task Learning (MTL) paradigm based deep neural network architecture, called MTCNet (Multi-Task Crowd Network) for crowd density and count estimation. Crowd count estimation is challenging due to the non-uniform scale variations and the arbitrary perspective of an individual image. The proposed model has two related tasks, with Crowd Density Estimation as the main task and Crowd-Count Group Classification as the auxiliary task. The auxiliary task helps in capturing the relevant scale-related information to improve the performance of the main task. The main task model comprises two blocks: VGG-16 front-end for feature extraction and a dilated Convolutional Neural Network for density map generation. The auxiliary task model shares the same front-end as the main task, followed by a CNN classifier. Our proposed network achieves 5.8% and 14.9% lower Mean Absolute Error (MAE) than the state-of-the-art methods on ShanghaiTech dataset without using any data augmentation. Our model also outperforms with 10.5% lower MAE on UCF_CC_50 dataset.
Learning Discriminative features using Center Loss and Reconstruction as Regularizer for Speech Emotion Recognition
Jun 19, 2019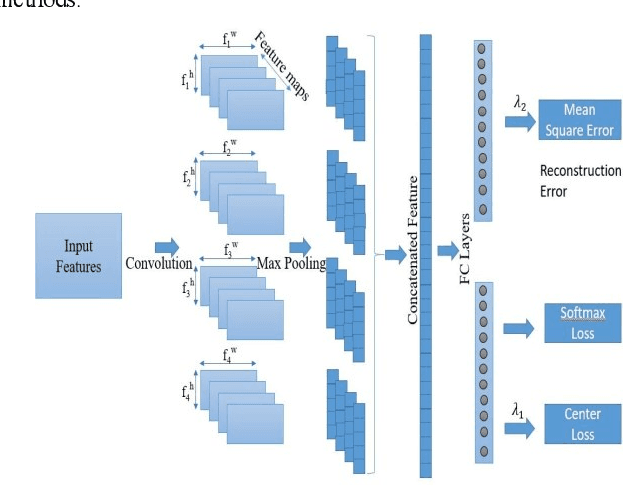
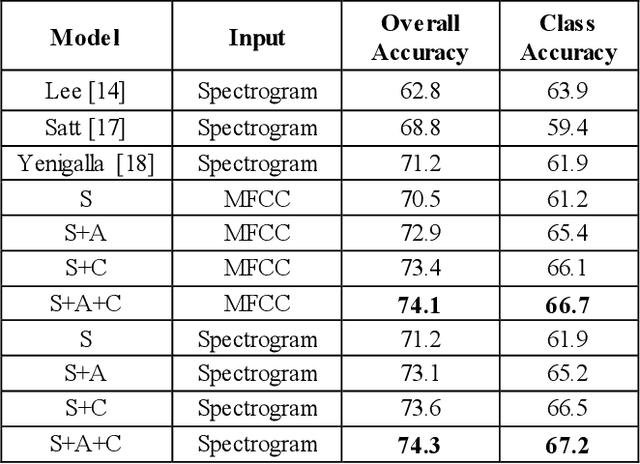
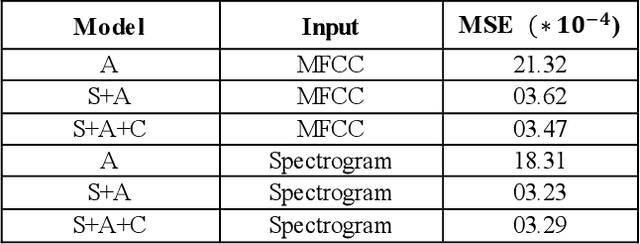
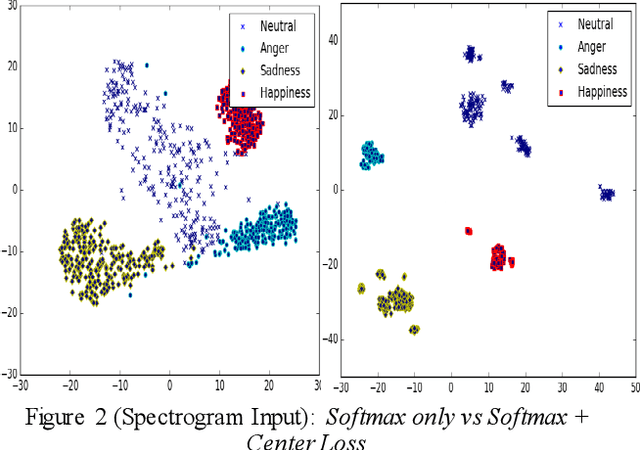
This paper proposes a Convolutional Neural Network (CNN) inspired by Multitask Learning (MTL) and based on speech features trained under the joint supervision of softmax loss and center loss, a powerful metric learning strategy, for the recognition of emotion in speech. Speech features such as Spectrograms and Mel-frequency Cepstral Coefficient s (MFCCs) help retain emotion-related low-level characteristics in speech. We experimented with several Deep Neural Network (DNN) architectures that take in speech features as input and trained them under both softmax and center loss, which resulted in highly discriminative features ideal for Speech Emotion Recognition (SER). Our networks also employ a regularizing effect by simultaneously performing the auxiliary task of reconstructing the input speech features. This sharing of representations among related tasks enables our network to better generalize the original task of SER. Some of our proposed networks contain far fewer parameters when compared to state-of-the-art architectures.
Visual Context-aware Convolution Filters for Transformation-invariant Neural Network
Jun 15, 2019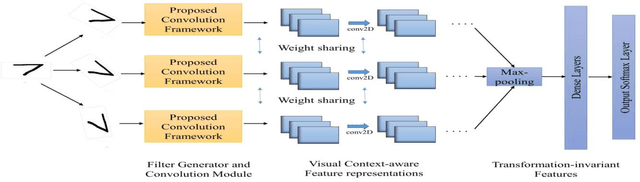
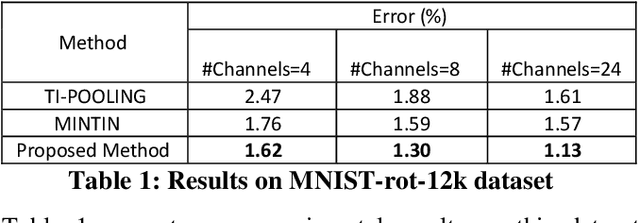
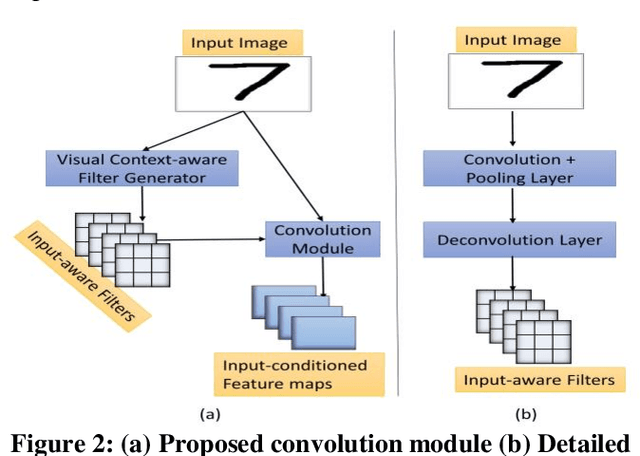

We propose a novel visual context-aware filter generation module which incorporates contextual information present in images into Convolutional Neural Networks (CNNs). In contrast to traditional CNNs, we do not employ the same set of learned convolution filters for all input image instances. Our proposed input-conditioned convolution filters when combined with techniques inspired by Multi-instance learning and max-pooling, results in a transformation-invariant neural network. We investigated the performance of our proposed framework on three MNIST variations, which covers both rotation and scaling variance, and achieved 1.13% error on MNIST-rot-12k, 1.12% error on Half-rotated MNIST and 0.68% error on Scaling MNIST, which is significantly better than the state-of-the-art results. We make use of visualization to further prove the effectiveness of our visual context-aware convolution filters. Our proposed visual context-aware convolution filter generation framework can also serve as a plugin for any CNN based architecture and enhance its modeling capacity.
From Fully Supervised to Zero Shot Settings for Twitter Hashtag Recommendation
Jun 11, 2019

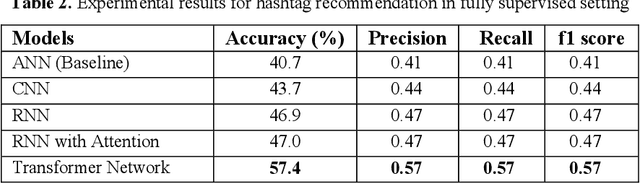
We propose a comprehensive end-to-end pipeline for Twitter hashtags recommendation system including data collection, supervised training setting and zero shot training setting. In the supervised training setting, we have proposed and compared the performance of various deep learning architectures, namely Convolutional Neural Network (CNN), Recurrent Neural Network (RNN) and Transformer Network. However, it is not feasible to collect data for all possible hashtag labels and train a classifier model on them. To overcome this limitation, we propose a Zero Shot Learning (ZSL) paradigm for predicting unseen hashtag labels by learning the relationship between the semantic space of tweets and the embedding space of hashtag labels. We evaluated various state-of-the-art ZSL methods like Convex combination of Semantic Embedding (ConSE), Embarrassingly Simple Zero-Shot Learning (ESZSL) and Deep Embedding Model for Zero-Shot Learning (DEM-ZSL) for the hashtag recommendation task. We demonstrate the effectiveness and scalability of ZSL methods for the recommendation of unseen hashtags. To the best of our knowledge, this is the first quantitative evaluation of ZSL methods to date for unseen hashtags recommendations from tweet text.
Deep Learning based Emotion Recognition System Using Speech Features and Transcriptions
Jun 11, 2019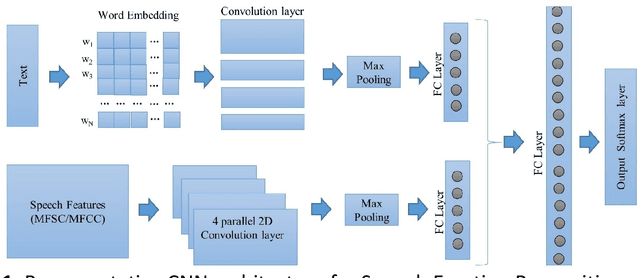
This paper proposes a speech emotion recognition method based on speech features and speech transcriptions (text). Speech features such as Spectrogram and Mel-frequency Cepstral Coefficients (MFCC) help retain emotion-related low-level characteristics in speech whereas text helps capture semantic meaning, both of which help in different aspects of emotion detection. We experimented with several Deep Neural Network (DNN) architectures, which take in different combinations of speech features and text as inputs. The proposed network architectures achieve higher accuracies when compared to state-of-the-art methods on a benchmark dataset. The combined MFCC-Text Convolutional Neural Network (CNN) model proved to be the most accurate in recognizing emotions in IEMOCAP data.
Focal Loss based Residual Convolutional Neural Network for Speech Emotion Recognition
Jun 11, 2019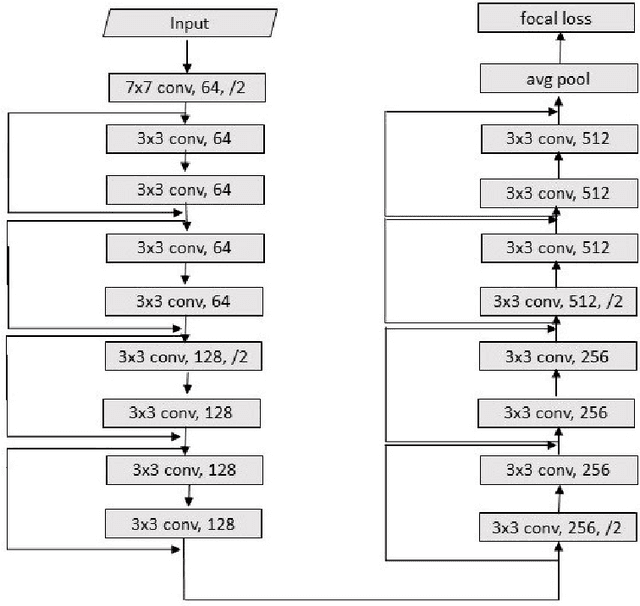
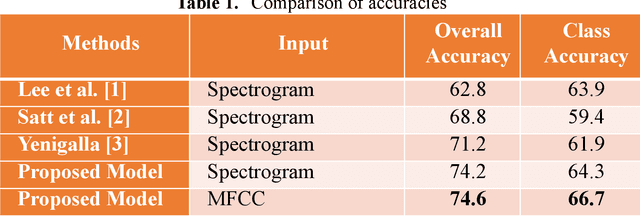
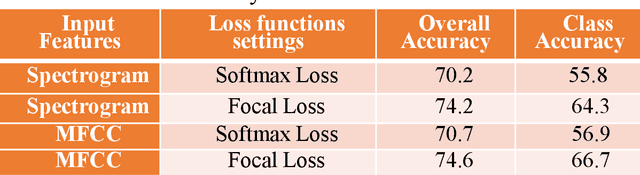
This paper proposes a Residual Convolutional Neural Network (ResNet) based on speech features and trained under Focal Loss to recognize emotion in speech. Speech features such as Spectrogram and Mel-frequency Cepstral Coefficients (MFCCs) have shown the ability to characterize emotion better than just plain text. Further Focal Loss, first used in One-Stage Object Detectors, has shown the ability to focus the training process more towards hard-examples and down-weight the loss assigned to well-classified examples, thus preventing the model from being overwhelmed by easily classifiable examples.
Exploiting SIFT Descriptor for Rotation Invariant Convolutional Neural Network
Mar 30, 2019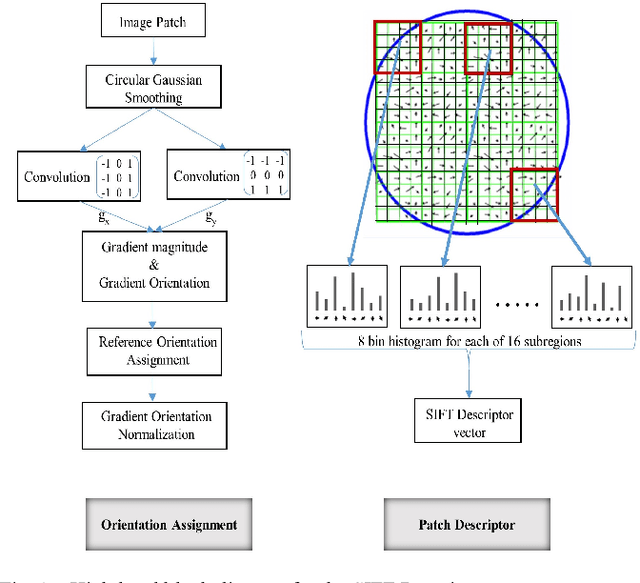
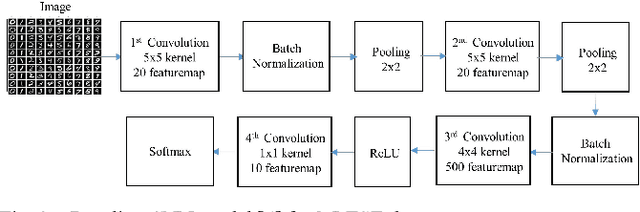
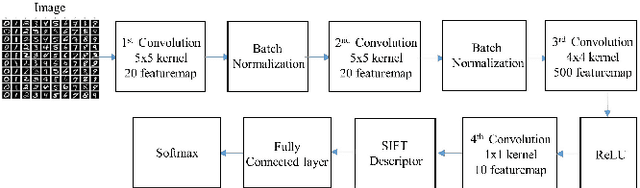
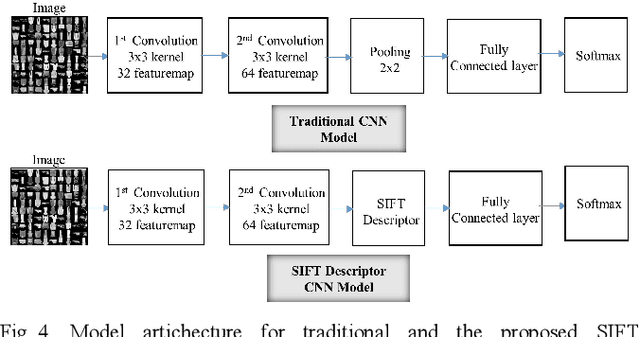
This paper presents a novel approach to exploit the distinctive invariant features in convolutional neural network. The proposed CNN model uses Scale Invariant Feature Transform (SIFT) descriptor instead of the max-pooling layer. Max-pooling layer discards the pose, i.e., translational and rotational relationship between the low-level features, and hence unable to capture the spatial hierarchies between low and high level features. The SIFT descriptor layer captures the orientation and the spatial relationship of the features extracted by convolutional layer. The proposed SIFT Descriptor CNN therefore combines the feature extraction capabilities of CNN model and rotation invariance of SIFT descriptor. Experimental results on the MNIST and fashionMNIST datasets indicates reasonable improvements over conventional methods available in literature.