 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting SIFT Descriptor for Rotation Invariant Convolutional Neural Network
Paper and Code
Mar 30, 2019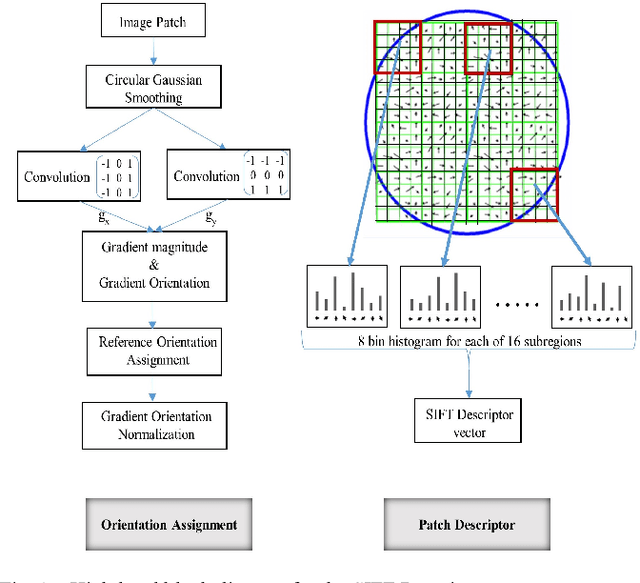
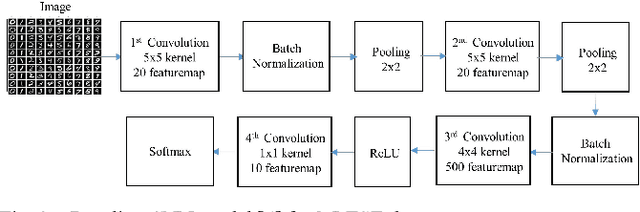
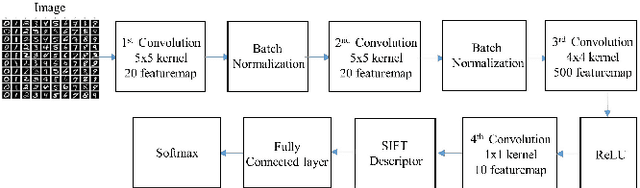
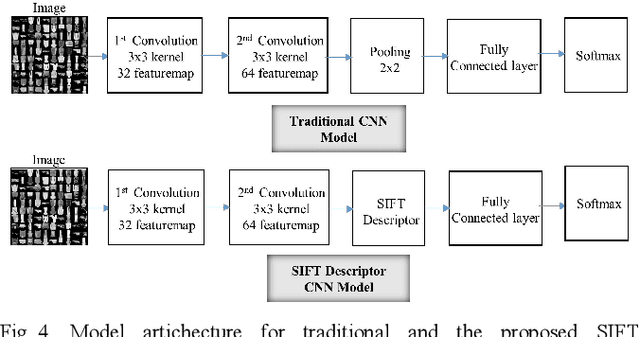
This paper presents a novel approach to exploit the distinctive invariant features in convolutional neural network. The proposed CNN model uses Scale Invariant Feature Transform (SIFT) descriptor instead of the max-pooling layer. Max-pooling layer discards the pose, i.e., translational and rotational relationship between the low-level features, and hence unable to capture the spatial hierarchies between low and high level features. The SIFT descriptor layer captures the orientation and the spatial relationship of the features extracted by convolutional layer. The proposed SIFT Descriptor CNN therefore combines the feature extraction capabilities of CNN model and rotation invariance of SIFT descriptor. Experimental results on the MNIST and fashionMNIST datasets indicates reasonable improvements over conventional methods available in literature.