 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Discriminative features using Center Loss and Reconstruction as Regularizer for Speech Emotion Recognition
Jun 19, 2019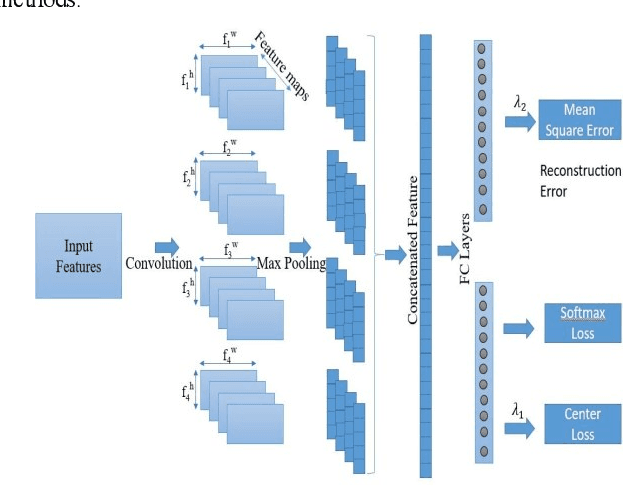
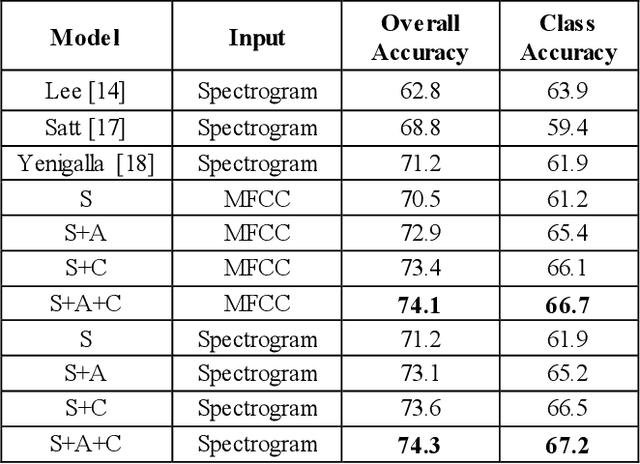
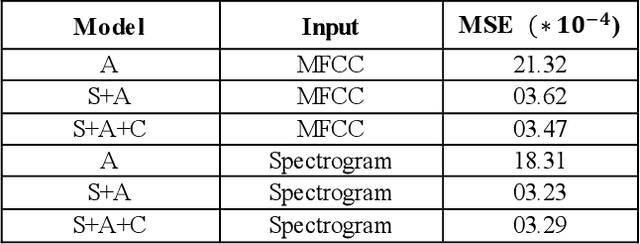
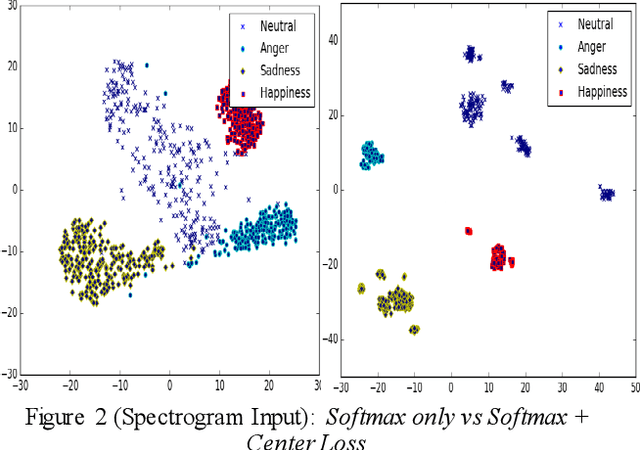
This paper proposes a Convolutional Neural Network (CNN) inspired by Multitask Learning (MTL) and based on speech features trained under the joint supervision of softmax loss and center loss, a powerful metric learning strategy, for the recognition of emotion in speech. Speech features such as Spectrograms and Mel-frequency Cepstral Coefficient s (MFCCs) help retain emotion-related low-level characteristics in speech. We experimented with several Deep Neural Network (DNN) architectures that take in speech features as input and trained them under both softmax and center loss, which resulted in highly discriminative features ideal for Speech Emotion Recognition (SER). Our networks also employ a regularizing effect by simultaneously performing the auxiliary task of reconstructing the input speech features. This sharing of representations among related tasks enables our network to better generalize the original task of SER. Some of our proposed networks contain far fewer parameters when compared to state-of-the-art architectures.
Deep Learning based Emotion Recognition System Using Speech Features and Transcriptions
Jun 11, 2019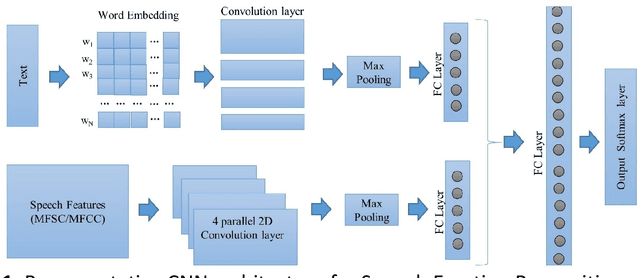
This paper proposes a speech emotion recognition method based on speech features and speech transcriptions (text). Speech features such as Spectrogram and Mel-frequency Cepstral Coefficients (MFCC) help retain emotion-related low-level characteristics in speech whereas text helps capture semantic meaning, both of which help in different aspects of emotion detection. We experimented with several Deep Neural Network (DNN) architectures, which take in different combinations of speech features and text as inputs. The proposed network architectures achieve higher accuracies when compared to state-of-the-art methods on a benchmark dataset. The combined MFCC-Text Convolutional Neural Network (CNN) model proved to be the most accurate in recognizing emotions in IEMOCAP data.
Focal Loss based Residual Convolutional Neural Network for Speech Emotion Recognition
Jun 11, 2019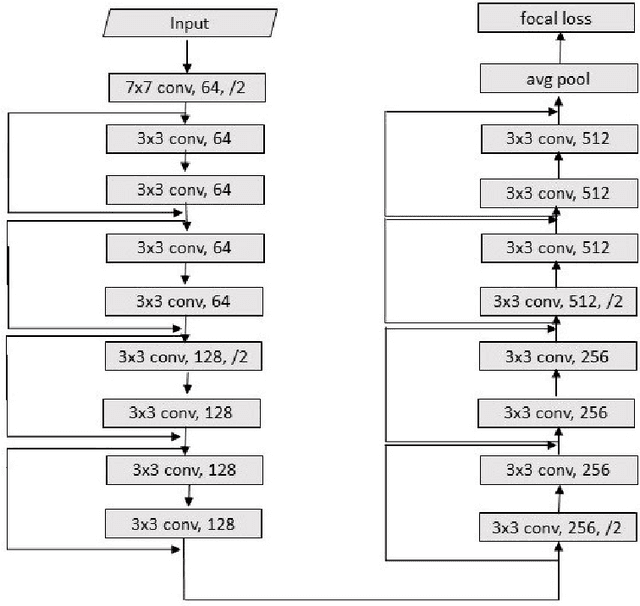
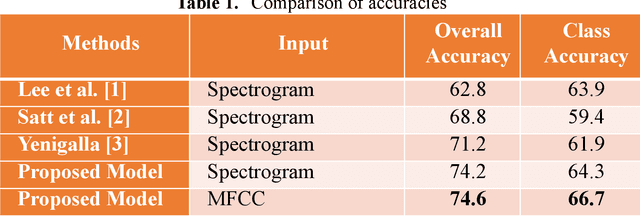
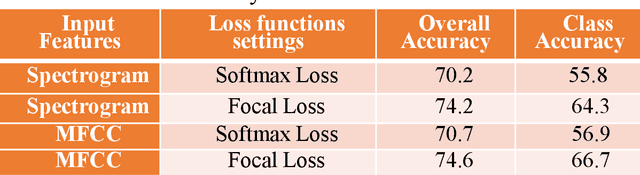
This paper proposes a Residual Convolutional Neural Network (ResNet) based on speech features and trained under Focal Loss to recognize emotion in speech. Speech features such as Spectrogram and Mel-frequency Cepstral Coefficients (MFCCs) have shown the ability to characterize emotion better than just plain text. Further Focal Loss, first used in One-Stage Object Detectors, has shown the ability to focus the training process more towards hard-examples and down-weight the loss assigned to well-classified examples, thus preventing the model from being overwhelmed by easily classifiable examples.