 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Context-aware Convolution Filters for Transformation-invariant Neural Network
Paper and Code
Jun 15, 2019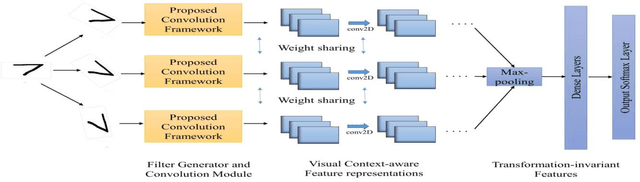
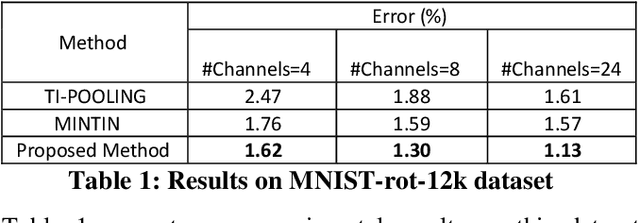
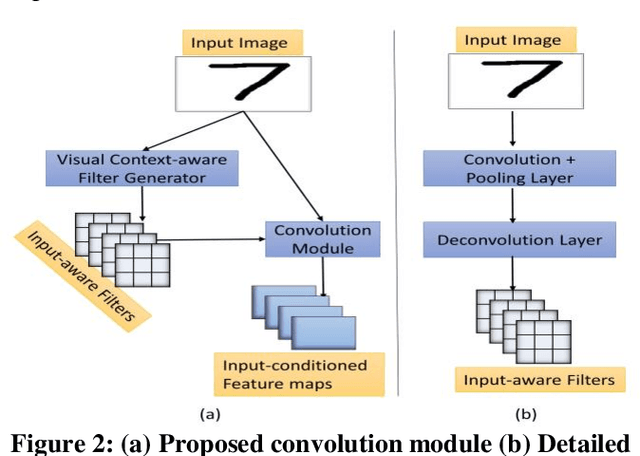

We propose a novel visual context-aware filter generation module which incorporates contextual information present in images into Convolutional Neural Networks (CNNs). In contrast to traditional CNNs, we do not employ the same set of learned convolution filters for all input image instances. Our proposed input-conditioned convolution filters when combined with techniques inspired by Multi-instance learning and max-pooling, results in a transformation-invariant neural network. We investigated the performance of our proposed framework on three MNIST variations, which covers both rotation and scaling variance, and achieved 1.13% error on MNIST-rot-12k, 1.12% error on Half-rotated MNIST and 0.68% error on Scaling MNIST, which is significantly better than the state-of-the-art results. We make use of visualization to further prove the effectiveness of our visual context-aware convolution filters. Our proposed visual context-aware convolution filter generation framework can also serve as a plugin for any CNN based architecture and enhance its modeling capacity.