Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Conversational Agents with Generative Conversational Networks
Paper and Code
Oct 15, 2021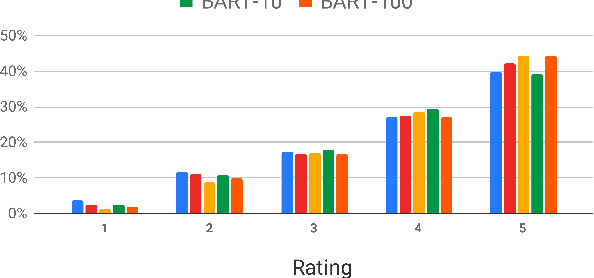

Rich, open-domain textual data available on the web resulted in great advancements for language processing. However, while that data may be suitable for language processing tasks, they are mostly non-conversational, lacking many phenomena that appear in human interactions and this is one of the reasons why we still have many unsolved challenges in conversational AI. In this work, we attempt to address this by using Generative Conversational Networks to automatically generate data and train social conversational agents. We evaluate our approach on TopicalChat with automatic metrics and human evaluators, showing that with 10% of seed data it performs close to the baseline that uses 100% of the data.
* Accepted at WeCNLP 2021
View paper on