 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Interpretable and Trustworthy are GAMs?
Paper and Code
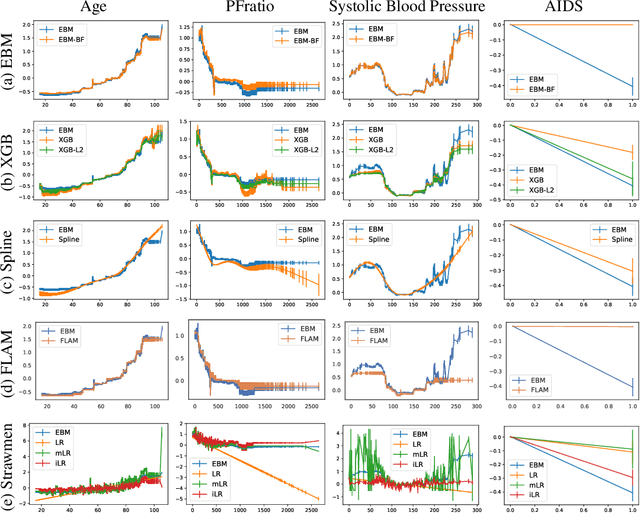
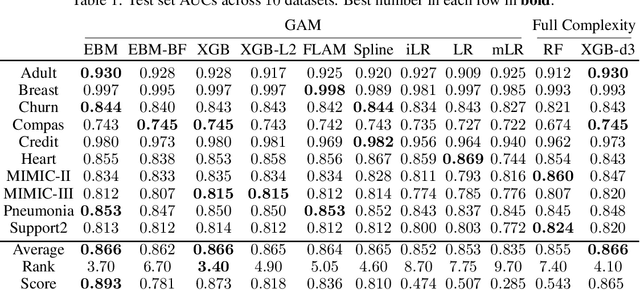

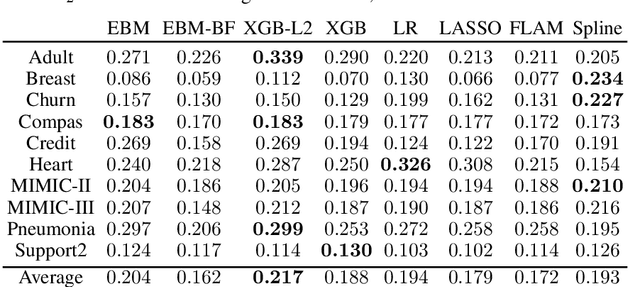
Generalized additive models (GAMs) have become a leading model class for data bias discovery and model auditing. However, there are a variety of algorithms for training GAMs, and these do not always learn the same things. Statisticians originally used splines to train GAMs, but more recently GAMs are being trained with boosted decision trees. It is unclear which GAM model(s) to believe, particularly when their explanations are contradictory. In this paper, we investigate a variety of different GAM algorithms both qualitatively and quantitatively on real and simulated datasets. Our results suggest that inductive bias plays a crucial role in model explanations and tree-based GAMs are to be recommended for the kinds of problems and dataset sizes we worked with.