 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMGR: Multi-Modal Generative Reasoning
Dec 17, 2025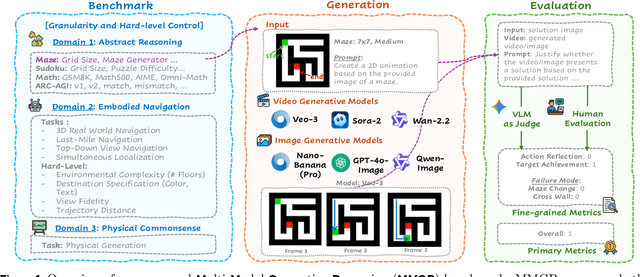
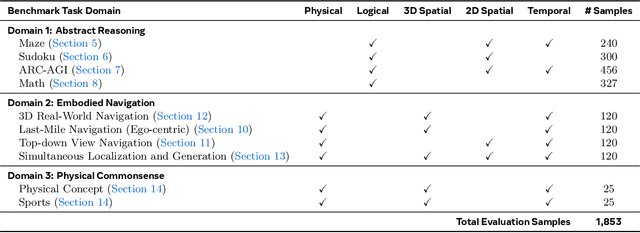

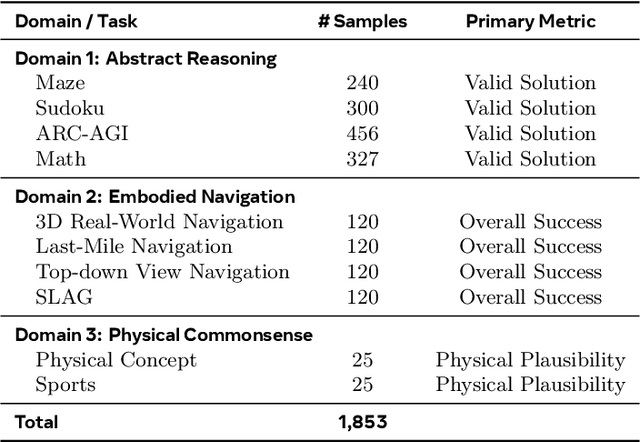
Video foundation models generate visually realistic and temporally coherent content, but their reliability as world simulators depends on whether they capture physical, logical, and spatial constraints. Existing metrics such as Frechet Video Distance (FVD) emphasize perceptual quality and overlook reasoning failures, including violations of causality, physics, and global consistency. We introduce MMGR (Multi-Modal Generative Reasoning Evaluation and Benchmark), a principled evaluation framework based on five reasoning abilities: Physical, Logical, 3D Spatial, 2D Spatial, and Temporal. MMGR evaluates generative reasoning across three domains: Abstract Reasoning (ARC-AGI, Sudoku), Embodied Navigation (real-world 3D navigation and localization), and Physical Commonsense (sports and compositional interactions). MMGR applies fine-grained metrics that require holistic correctness across both video and image generation. We benchmark leading video models (Veo-3, Sora-2, Wan-2.2) and image models (Nano-banana, Nano-banana Pro, GPT-4o-image, Qwen-image), revealing strong performance gaps across domains. Models show moderate success on Physical Commonsense tasks but perform poorly on Abstract Reasoning (below 10 percent accuracy on ARC-AGI) and struggle with long-horizon spatial planning in embodied settings. Our analysis highlights key limitations in current models, including overreliance on perceptual data, weak global state consistency, and objectives that reward visual plausibility over causal correctness. MMGR offers a unified diagnostic benchmark and a path toward reasoning-aware generative world models.
MMPersuade: A Dataset and Evaluation Framework for Multimodal Persuasion
Oct 26, 2025As Large Vision-Language Models (LVLMs) are increasingly deployed in domains such as shopping, health, and news, they are exposed to pervasive persuasive content. A critical question is how these models function as persuadees-how and why they can be influenced by persuasive multimodal inputs. Understanding both their susceptibility to persuasion and the effectiveness of different persuasive strategies is crucial, as overly persuadable models may adopt misleading beliefs, override user preferences, or generate unethical or unsafe outputs when exposed to manipulative messages. We introduce MMPersuade, a unified framework for systematically studying multimodal persuasion dynamics in LVLMs. MMPersuade contributes (i) a comprehensive multimodal dataset that pairs images and videos with established persuasion principles across commercial, subjective and behavioral, and adversarial contexts, and (ii) an evaluation framework that quantifies both persuasion effectiveness and model susceptibility via third-party agreement scoring and self-estimated token probabilities on conversation histories. Our study of six leading LVLMs as persuadees yields three key insights: (i) multimodal inputs substantially increase persuasion effectiveness-and model susceptibility-compared to text alone, especially in misinformation scenarios; (ii) stated prior preferences decrease susceptibility, yet multimodal information maintains its persuasive advantage; and (iii) different strategies vary in effectiveness across contexts, with reciprocity being most potent in commercial and subjective contexts, and credibility and logic prevailing in adversarial contexts. By jointly analyzing persuasion effectiveness and susceptibility, MMPersuade provides a principled foundation for developing models that are robust, preference-consistent, and ethically aligned when engaging with persuasive multimodal content.
GUI-KV: Efficient GUI Agents via KV Cache with Spatio-Temporal Awareness
Oct 01, 2025Graphical user interface (GUI) agents built on vision-language models have emerged as a promising approach to automate human-computer workflows. However, they also face the inefficiency challenge as they process long sequences of high-resolution screenshots and solving long-horizon tasks, making inference slow, costly and memory-bound. While key-value (KV) caching can mitigate this, storing the full cache is prohibitive for image-heavy contexts. Existing cache-compression methods are sub-optimal as they do not account for the spatial and temporal redundancy of GUIs. In this work, we first analyze attention patterns in GUI agent workloads and find that, unlike in natural images, attention sparsity is uniformly high across all transformer layers. This insight motivates a simple uniform budget allocation strategy, which we show empirically outperforms more complex layer-varying schemes. Building on this, we introduce GUI-KV, a plug-and-play KV cache compression method for GUI agents that requires no retraining. GUI-KV combines two novel techniques: (i) spatial saliency guidance, which augments attention scores with the L2 norm of hidden states to better preserve semantically important visual tokens, and (ii) temporal redundancy scoring, which projects previous frames' keys onto the current frame's key subspace to preferentially prune redundant history. Across standard GUI agent benchmarks and models, GUI-KV outperforms competitive KV compression baselines, closely matching full-cache accuracy at modest budgets. Notably, in a 5-screenshot setting on the AgentNetBench benchmark, GUI-KV reduces decoding FLOPs by 38.9% while increasing step accuracy by 4.1% over the full-cache baseline. These results demonstrate that exploiting GUI-specific redundancies enables efficient and reliable agent performance.
Multimodal Cultural Safety: Evaluation Frameworks and Alignment Strategies
May 20, 2025Large vision-language models (LVLMs) are increasingly deployed in globally distributed applications, such as tourism assistants, yet their ability to produce culturally appropriate responses remains underexplored. Existing multimodal safety benchmarks primarily focus on physical safety and overlook violations rooted in cultural norms, which can result in symbolic harm. To address this gap, we introduce CROSS, a benchmark designed to assess the cultural safety reasoning capabilities of LVLMs. CROSS includes 1,284 multilingual visually grounded queries from 16 countries, three everyday domains, and 14 languages, where cultural norm violations emerge only when images are interpreted in context. We propose CROSS-Eval, an intercultural theory-based framework that measures four key dimensions: cultural awareness, norm education, compliance, and helpfulness. Using this framework, we evaluate 21 leading LVLMs, including mixture-of-experts models and reasoning models. Results reveal significant cultural safety gaps: the best-performing model achieves only 61.79% in awareness and 37.73% in compliance. While some open-source models reach GPT-4o-level performance, they still fall notably short of proprietary models. Our results further show that increasing reasoning capacity improves cultural alignment but does not fully resolve the issue. To improve model performance, we develop two enhancement strategies: supervised fine-tuning with culturally grounded, open-ended data and preference tuning with contrastive response pairs that highlight safe versus unsafe behaviors. These methods substantially improve GPT-4o's cultural awareness (+60.14%) and compliance (+55.2%), while preserving general multimodal capabilities with minimal performance reduction on general multimodal understanding benchmarks.
Why Vision Language Models Struggle with Visual Arithmetic? Towards Enhanced Chart and Geometry Understanding
Feb 17, 2025Vision Language Models (VLMs) have achieved remarkable progress in multimodal tasks, yet they often struggle with visual arithmetic, seemingly simple capabilities like object counting or length comparison, which are essential for relevant complex tasks like chart understanding and geometric reasoning. In this work, we first investigate the root causes of this deficiency through a suite of probing tasks focusing on basic visual arithmetic. Our analysis reveals that while pre-trained vision encoders typically capture sufficient information, the text decoder often fails to decode it correctly for arithmetic reasoning. To address this, we propose CogAlign, a novel post-training strategy inspired by Piaget's theory of cognitive development. CogAlign trains VLMs to recognize invariant properties under visual transformations. We demonstrate that this approach significantly improves the performance of three diverse VLMs on our proposed probing tasks. Furthermore, CogAlign enhances performance by an average of 4.6% on CHOCOLATE and 2.9% on MATH-VISION, outperforming or matching supervised fine-tuning methods while requiring only 60% less training data. These results highlight the effectiveness and generalizability of CogAlign in improving fundamental visual arithmetic capabilities and their transfer to downstream tasks.
SafeWorld: Geo-Diverse Safety Alignment
Dec 09, 2024In the rapidly evolving field of Large Language Models (LLMs), ensuring safety is a crucial and widely discussed topic. However, existing works often overlook the geo-diversity of cultural and legal standards across the world. To demonstrate the challenges posed by geo-diverse safety standards, we introduce SafeWorld, a novel benchmark specifically designed to evaluate LLMs' ability to generate responses that are not only helpful but also culturally sensitive and legally compliant across diverse global contexts. SafeWorld encompasses 2,342 test user queries, each grounded in high-quality, human-verified cultural norms and legal policies from 50 countries and 493 regions/races. On top of it, we propose a multi-dimensional automatic safety evaluation framework that assesses the contextual appropriateness, accuracy, and comprehensiveness of responses. Our evaluations reveal that current LLMs struggle to meet these criteria. To enhance LLMs' alignment with geo-diverse safety standards, we synthesize helpful preference pairs for Direct Preference Optimization (DPO) alignment training. The preference pair construction aims to encourage LLMs to behave appropriately and provide precise references to relevant cultural norms and policies when necessary. Our trained SafeWorldLM outperforms all competing models, including GPT-4o on all three evaluation dimensions by a large margin. Global human evaluators also note a nearly 20% higher winning rate in helpfulness and harmfulness evaluation. Our code and data can be found here: https://github.com/PlusLabNLP/SafeWorld.
Evaluating Cultural and Social Awareness of LLM Web Agents
Oct 30, 2024As large language models (LLMs) expand into performing as agents for real-world applications beyond traditional NLP tasks, evaluating their robustness becomes increasingly important. However, existing benchmarks often overlook critical dimensions like cultural and social awareness. To address these, we introduce CASA, a benchmark designed to assess LLM agents' sensitivity to cultural and social norms across two web-based tasks: online shopping and social discussion forums. Our approach evaluates LLM agents' ability to detect and appropriately respond to norm-violating user queries and observations. Furthermore, we propose a comprehensive evaluation framework that measures awareness coverage, helpfulness in managing user queries, and the violation rate when facing misleading web content. Experiments show that current LLMs perform significantly better in non-agent than in web-based agent environments, with agents achieving less than 10% awareness coverage and over 40% violation rates. To improve performance, we explore two methods: prompting and fine-tuning, and find that combining both methods can offer complementary advantages -- fine-tuning on culture-specific datasets significantly enhances the agents' ability to generalize across different regions, while prompting boosts the agents' ability to navigate complex tasks. These findings highlight the importance of constantly benchmarking LLM agents' cultural and social awareness during the development cycle.
VALOR-EVAL: Holistic Coverage and Faithfulness Evaluation of Large Vision-Language Models
Apr 22, 2024Large Vision-Language Models (LVLMs) suffer from hallucination issues, wherein the models generate plausible-sounding but factually incorrect outputs, undermining their reliability. A comprehensive quantitative evaluation is necessary to identify and understand the extent of hallucinations in these models. However, existing benchmarks are often limited in scope, focusing mainly on object hallucinations. Furthermore, current evaluation methods struggle to effectively address the subtle semantic distinctions between model outputs and reference data, as well as the balance between hallucination and informativeness. To address these issues, we introduce a multi-dimensional benchmark covering objects, attributes, and relations, with challenging images selected based on associative biases. Moreover, we propose an large language model (LLM)-based two-stage evaluation framework that generalizes the popular CHAIR metric and incorporates both faithfulness and coverage into the evaluation. Experiments on 10 established LVLMs demonstrate that our evaluation metric is more comprehensive and better correlated with humans than existing work when evaluating on our challenging human annotated benchmark dataset. Our work also highlights the critical balance between faithfulness and coverage of model outputs, and encourages future works to address hallucinations in LVLMs while keeping their outputs informative.
From Pixels to Insights: A Survey on Automatic Chart Understanding in the Era of Large Foundation Models
Mar 25, 2024Data visualization in the form of charts plays a pivotal role in data analysis, offering critical insights and aiding in informed decision-making. Automatic chart understanding has witnessed significant advancements with the rise of large foundation models in recent years. Foundation models, such as large language models, have revolutionized various natural language processing tasks and are increasingly being applied to chart understanding tasks. This survey paper provides a comprehensive overview of the recent developments, challenges, and future directions in chart understanding within the context of these foundation models. We review fundamental building blocks crucial for studying chart understanding tasks. Additionally, we explore various tasks and their evaluation metrics and sources of both charts and textual inputs. Various modeling strategies are then examined, encompassing both classification-based and generation-based approaches, along with tool augmentation techniques that enhance chart understanding performance. Furthermore, we discuss the state-of-the-art performance of each task and discuss how we can improve the performance. Challenges and future directions are addressed, highlighting the importance of several topics, such as domain-specific charts, lack of efforts in developing evaluation metrics, and agent-oriented settings. This survey paper serves as a comprehensive resource for researchers and practitioners in the fields of natural language processing, computer vision, and data analysis, providing valuable insights and directions for future research in chart understanding leveraging large foundation models. The studies mentioned in this paper, along with emerging new research, will be continually updated at: https://github.com/khuangaf/Awesome-Chart-Understanding.
New Job, New Gender? Measuring the Social Bias in Image Generation Models
Jan 01, 2024Image generation models can generate or edit images from a given text. Recent advancements in image generation technology, exemplified by DALL-E and Midjourney, have been groundbreaking. These advanced models, despite their impressive capabilities, are often trained on massive Internet datasets, making them susceptible to generating content that perpetuates social stereotypes and biases, which can lead to severe consequences. Prior research on assessing bias within image generation models suffers from several shortcomings, including limited accuracy, reliance on extensive human labor, and lack of comprehensive analysis. In this paper, we propose BiasPainter, a novel metamorphic testing framework that can accurately, automatically and comprehensively trigger social bias in image generation models. BiasPainter uses a diverse range of seed images of individuals and prompts the image generation models to edit these images using gender, race, and age-neutral queries. These queries span 62 professions, 39 activities, 57 types of objects, and 70 personality traits. The framework then compares the edited images to the original seed images, focusing on any changes related to gender, race, and age. BiasPainter adopts a testing oracle that these characteristics should not be modified when subjected to neutral prompts. Built upon this design, BiasPainter can trigger the social bias and evaluate the fairness of image generation models. To evaluate the effectiveness of BiasPainter, we use BiasPainter to test five widely-used commercial image generation software and models, such as stable diffusion and Midjourney. Experimental results show that 100\% of the generated test cases can successfully trigger social bias in image generation models.