 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosition: Prioritize Identifying Structure, Not Complex Models, for Scientific Discovery
May 30, 2026Modern Machine Learning (ML) and Artificial Intelligence (AI) models, especially large language models (LLMs), are increasingly used to generate scientific hypotheses and mechanistic explanations from observational data. This position paper argues that in the high-dimensional proxy regimes where modern ML excels, mechanistic learning is generically underdetermined: many incompatible mechanisms induce essentially the same observational relationships on the support of the data, so predictive success and coherent explanations are insufficient evidence of mechanism discovery. This underdetermination becomes uniquely hazardous with large language models (LLMs), which tend to collapse large equivalence classes of explanations into a single fluent narrative. This paper proposes concrete standards for ``mechanistic ML,'' and argues these norms are necessary if LLM-centered workflows are to support science rather than merely simulate it.
REALITrees: Rashomon Ensemble Active Learning for Interpretable Trees
Mar 24, 2026Active learning reduces labeling costs by selecting samples that maximize information gain. A dominant framework, Query-by-Committee (QBC), typically relies on perturbation-based diversity by inducing model disagreement through random feature subsetting or data blinding. While this approximates one notion of epistemic uncertainty, it sacrifices direct characterization of the plausible hypothesis space. We propose the complementary approach: Rashomon Ensembled Active Learning (REAL) which constructs a committee by exhaustively enumerating the Rashomon Set of all near-optimal models. To address functional redundancy within this set, we adopt a PAC-Bayesian framework using a Gibbs posterior to weight committee members by their empirical risk. Leveraging recent algorithmic advances, we exactly enumerate this set for the class of sparse decision trees. Across synthetic and established active learning baselines, REAL outperforms randomized ensembles, particularly in moderately noisy environments where it strategically leverages expanded model multiplicity to achieve faster convergence.
Adaptive Active Learning for Regression via Reinforcement Learning
Mar 11, 2026Active learning for regression reduces labeling costs by selecting the most informative samples. Improved Greedy Sampling is a prominent method that balances feature-space diversity and output-space uncertainty using a static, multiplicative rule. We propose Weighted improved Greedy Sampling (WiGS), which replaces this framework with a dynamic, additive criterion. We formulate weight selection as a reinforcement learning problem, enabling an agent to adapt the exploration-investigation balance throughout learning. Experiments on 18 benchmark datasets and a synthetic environment show WiGS outperforms iGS and other baseline methods in both accuracy and labeling efficiency, particularly in domains with irregular data density where the baseline's multiplicative rule ignores high-error samples in dense regions.
LAVA: Language Model Assisted Verbal Autopsy for Cause-of-Death Determination
Sep 11, 2025Verbal autopsy (VA) is a critical tool for estimating causes of death in resource-limited settings where medical certification is unavailable. This study presents LA-VA, a proof-of-concept pipeline that combines Large Language Models (LLMs) with traditional algorithmic approaches and embedding-based classification for improved cause-of-death prediction. Using the Population Health Metrics Research Consortium (PHMRC) dataset across three age categories (Adult: 7,580; Child: 1,960; Neonate: 2,438), we evaluate multiple approaches: GPT-5 predictions, LCVA baseline, text embeddings, and meta-learner ensembles. Our results demonstrate that GPT-5 achieves the highest individual performance with average test site accuracies of 48.6% (Adult), 50.5% (Child), and 53.5% (Neonate), outperforming traditional statistical machine learning baselines by 5-10%. Our findings suggest that simple off-the-shelf LLM-assisted approaches could substantially improve verbal autopsy accuracy, with important implications for global health surveillance in low-resource settings.
Model-Based Inference and Experimental Design for Interference Using Partial Network Data
Jun 17, 2024



The stable unit treatment value assumption states that the outcome of an individual is not affected by the treatment statuses of others, however in many real world applications, treatments can have an effect on many others beyond the immediately treated. Interference can generically be thought of as mediated through some network structure. In many empirically relevant situations however, complete network data (required to adjust for these spillover effects) are too costly or logistically infeasible to collect. Partially or indirectly observed network data (e.g., subsamples, aggregated relational data (ARD), egocentric sampling, or respondent-driven sampling) reduce the logistical and financial burden of collecting network data, but the statistical properties of treatment effect adjustments from these design strategies are only beginning to be explored. In this paper, we present a framework for the estimation and inference of treatment effect adjustments using partial network data through the lens of structural causal models. We also illustrate procedures to assign treatments using only partial network data, with the goal of either minimizing estimator variance or optimally seeding. We derive single network asymptotic results applicable to a variety of choices for an underlying graph model. We validate our approach using simulated experiments on observed graphs with applications to information diffusion in India and Malawi.
From Narratives to Numbers: Valid Inference Using Language Model Predictions from Verbal Autopsy Narratives
Apr 03, 2024



In settings where most deaths occur outside the healthcare system, verbal autopsies (VAs) are a common tool to monitor trends in causes of death (COD). VAs are interviews with a surviving caregiver or relative that are used to predict the decedent's COD. Turning VAs into actionable insights for researchers and policymakers requires two steps (i) predicting likely COD using the VA interview and (ii) performing inference with predicted CODs (e.g. modeling the breakdown of causes by demographic factors using a sample of deaths). In this paper, we develop a method for valid inference using outcomes (in our case COD) predicted from free-form text using state-of-the-art NLP techniques. This method, which we call multiPPI++, extends recent work in "prediction-powered inference" to multinomial classification. We leverage a suite of NLP techniques for COD prediction and, through empirical analysis of VA data, demonstrate the effectiveness of our approach in handling transportability issues. multiPPI++ recovers ground truth estimates, regardless of which NLP model produced predictions and regardless of whether they were produced by a more accurate predictor like GPT-4-32k or a less accurate predictor like KNN. Our findings demonstrate the practical importance of inference correction for public health decision-making and suggests that if inference tasks are the end goal, having a small amount of contextually relevant, high quality labeled data is essential regardless of the NLP algorithm.
Robustly estimating heterogeneity in factorial data using Rashomon Partitions
Apr 02, 2024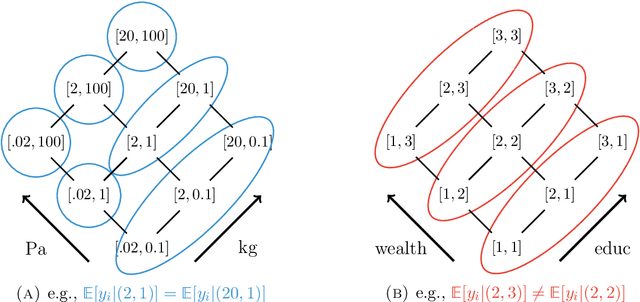



Many statistical analyses, in both observational data and randomized control trials, ask: how does the outcome of interest vary with combinations of observable covariates? How do various drug combinations affect health outcomes, or how does technology adoption depend on incentives and demographics? Our goal is to partition this factorial space into ``pools'' of covariate combinations where the outcome differs across the pools (but not within a pool). Existing approaches (i) search for a single ``optimal'' partition under assumptions about the association between covariates or (ii) sample from the entire set of possible partitions. Both these approaches ignore the reality that, especially with correlation structure in covariates, many ways to partition the covariate space may be statistically indistinguishable, despite very different implications for policy or science. We develop an alternative perspective, called Rashomon Partition Sets (RPSs). Each item in the RPS partitions the space of covariates using a tree-like geometry. RPSs incorporate all partitions that have posterior values near the maximum a posteriori partition, even if they offer substantively different explanations, and do so using a prior that makes no assumptions about associations between covariates. This prior is the $\ell_0$ prior, which we show is minimax optimal. Given the RPS we calculate the posterior of any measurable function of the feature effects vector on outcomes, conditional on being in the RPS. We also characterize approximation error relative to the entire posterior and provide bounds on the size of the RPS. Simulations demonstrate this framework allows for robust conclusions relative to conventional regularization techniques. We apply our method to three empirical settings: price effects on charitable giving, chromosomal structure (telomere length), and the introduction of microfinance.
Do We Really Even Need Data?
Feb 02, 2024As artificial intelligence and machine learning tools become more accessible, and scientists face new obstacles to data collection (e.g. rising costs, declining survey response rates), researchers increasingly use predictions from pre-trained algorithms as outcome variables. Though appealing for financial and logistical reasons, using standard tools for inference can misrepresent the association between independent variables and the outcome of interest when the true, unobserved outcome is replaced by a predicted value. In this paper, we characterize the statistical challenges inherent to this so-called ``inference with predicted data'' problem and elucidate three potential sources of error: (i) the relationship between predicted outcomes and their true, unobserved counterparts, (ii) robustness of the machine learning model to resampling or uncertainty about the training data, and (iii) appropriately propagating not just bias but also uncertainty from predictions into the ultimate inference procedure.
Bayesian Hyperbolic Multidimensional Scaling
Nov 01, 2022Multidimensional scaling (MDS) is a widely used approach to representing high-dimensional, dependent data. MDS works by assigning each observation a location on a low-dimensional geometric manifold, with distance on the manifold representing similarity. We propose a Bayesian approach to multidimensional scaling when the low-dimensional manifold is hyperbolic. Using hyperbolic space facilitates representing tree-like structure common in many settings (e.g. text or genetic data with hierarchical structure). A Bayesian approach provides regularization that minimizes the impact of uncertainty or measurement error in the observed data. We also propose a case-control likelihood approximation that allows for efficient sampling from the posterior in larger data settings, reducing computational complexity from approximately $O(n^2)$ to $O(n)$. We evaluate the proposed method against state-of-the-art alternatives using simulations, canonical reference datasets, and human gene expression data.
Spectral goodness-of-fit tests for complete and partial network data
Jun 17, 2021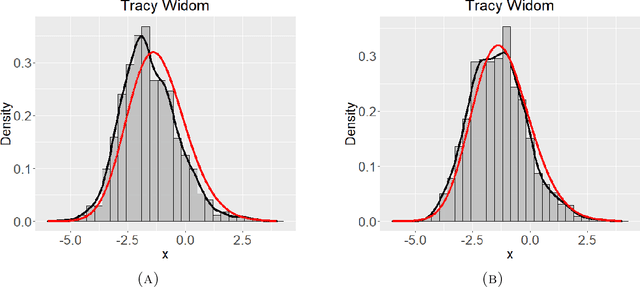
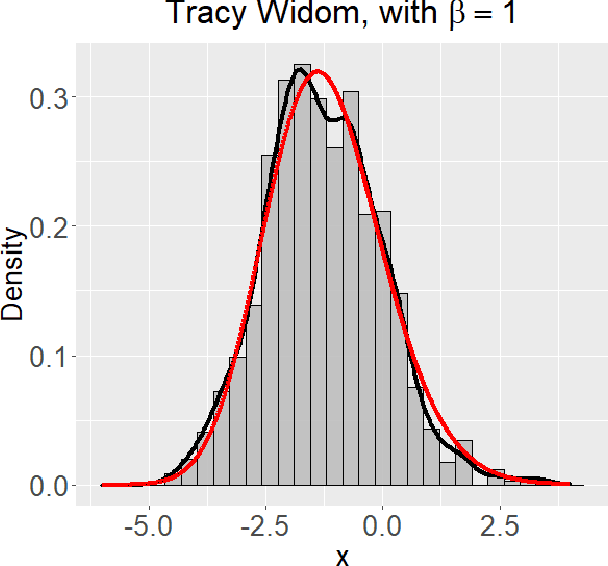

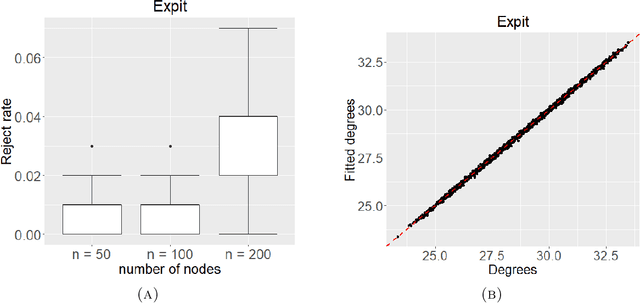
Networks describe the, often complex, relationships between individual actors. In this work, we address the question of how to determine whether a parametric model, such as a stochastic block model or latent space model, fits a dataset well and will extrapolate to similar data. We use recent results in random matrix theory to derive a general goodness-of-fit test for dyadic data. We show that our method, when applied to a specific model of interest, provides an straightforward, computationally fast way of selecting parameters in a number of commonly used network models. For example, we show how to select the dimension of the latent space in latent space models. Unlike other network goodness-of-fit methods, our general approach does not require simulating from a candidate parametric model, which can be cumbersome with large graphs, and eliminates the need to choose a particular set of statistics on the graph for comparison. It also allows us to perform goodness-of-fit tests on partial network data, such as Aggregated Relational Data. We show with simulations that our method performs well in many situations of interest. We analyze several empirically relevant networks and show that our method leads to improved community detection algorithms. R code to implement our method is available on Github.