 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Augmentation for Electrocardiograms
Paper and Code
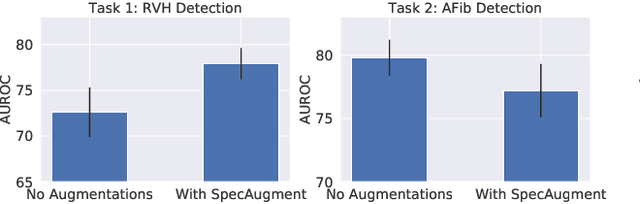
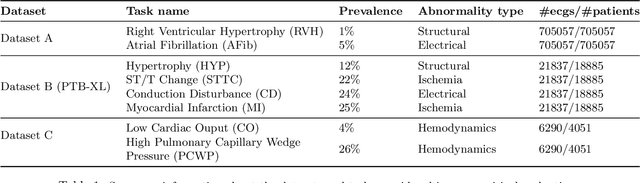
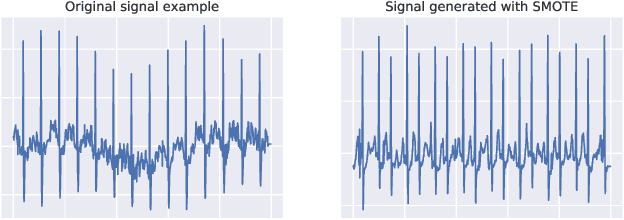
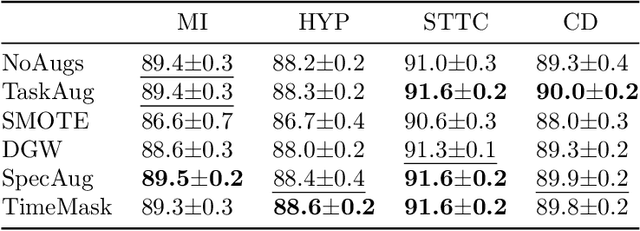
Neural network models have demonstrated impressive performance in predicting pathologies and outcomes from the 12-lead electrocardiogram (ECG). However, these models often need to be trained with large, labelled datasets, which are not available for many predictive tasks of interest. In this work, we perform an empirical study examining whether training time data augmentation methods can be used to improve performance on such data-scarce ECG prediction problems. We investigate how data augmentation strategies impact model performance when detecting cardiac abnormalities from the ECG. Motivated by our finding that the effectiveness of existing augmentation strategies is highly task-dependent, we introduce a new method, TaskAug, which defines a flexible augmentation policy that is optimized on a per-task basis. We outline an efficient learning algorithm to do so that leverages recent work in nested optimization and implicit differentiation. In experiments, considering three datasets and eight predictive tasks, we find that TaskAug is competitive with or improves on prior work, and the learned policies shed light on what transformations are most effective for different tasks. We distill key insights from our experimental evaluation, generating a set of best practices for applying data augmentation to ECG prediction problems.