 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStudying the Consistency and Composability of Lottery Ticket Pruning Masks
Paper and Code
Apr 30, 2021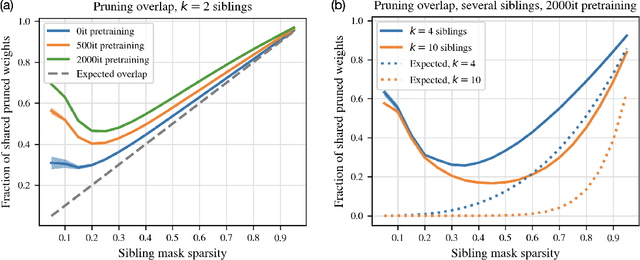

Magnitude pruning is a common, effective technique to identify sparse subnetworks at little cost to accuracy. In this work, we ask whether a particular architecture's accuracy-sparsity tradeoff can be improved by combining pruning information across multiple runs of training. From a shared ResNet-20 initialization, we train several network copies (\emph{siblings}) to completion using different SGD data orders on CIFAR-10. While the siblings' pruning masks are naively not much more similar than chance, starting sibling training after a few epochs of shared pretraining significantly increases pruning overlap. We then choose a subnetwork by either (1) taking all weights that survive pruning in any sibling (mask union), or (2) taking only the weights that survive pruning across all siblings (mask intersection). The resulting subnetwork is retrained. Strikingly, we find that union and intersection masks perform very similarly. Both methods match the accuracy-sparsity tradeoffs of the one-shot magnitude pruning baseline, even when we combine masks from up to $k = 10$ siblings.