 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDescription Logic EL++ Embeddings with Intersectional Closure
Feb 28, 2022



Many ontologies, in particular in the biomedical domain, are based on the Description Logic EL++. Several efforts have been made to interpret and exploit EL++ ontologies by distributed representation learning. Specifically, concepts within EL++ theories have been represented as n-balls within an n-dimensional embedding space. However, the intersectional closure is not satisfied when using n-balls to represent concepts because the intersection of two n-balls is not an n-ball. This leads to challenges when measuring the distance between concepts and inferring equivalence between concepts. To this end, we developed EL Box Embedding (ELBE) to learn Description Logic EL++ embeddings using axis-parallel boxes. We generate specially designed box-based geometric constraints from EL++ axioms for model training. Since the intersection of boxes remains as a box, the intersectional closure is satisfied. We report extensive experimental results on three datasets and present a case study to demonstrate the effectiveness of the proposed method.
EL Embeddings: Geometric construction of models for the Description Logic EL ++
Feb 27, 2019
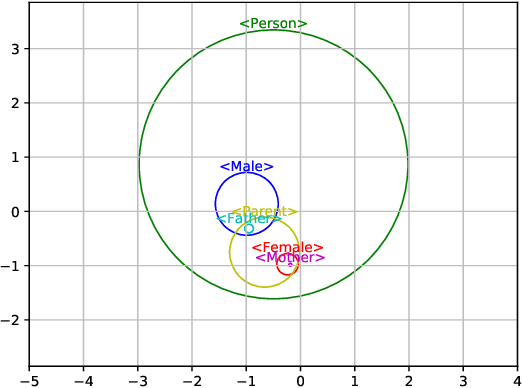


An embedding is a function that maps entities from one algebraic structure into another while preserving certain characteristics. Embeddings are being used successfully for mapping relational data or text into vector spaces where they can be used for machine learning, similarity search, or similar tasks. We address the problem of finding vector space embeddings for theories in the Description Logic $\mathcal{EL}^{++}$ that are also models of the TBox. To find such embeddings, we define an optimization problem that characterizes the model-theoretic semantics of the operators in $\mathcal{EL}^{++}$ within $\Re^n$, thereby solving the problem of finding an interpretation function for an $\mathcal{EL}^{++}$ theory given a particular domain $\Delta$. Our approach is mainly relevant to large $\mathcal{EL}^{++}$ theories and knowledge bases such as the ontologies and knowledge graphs used in the life sciences. We demonstrate that our method can be used for improved prediction of protein--protein interactions when compared to semantic similarity measures or knowledge graph embedding
DeepGO: Predicting protein functions from sequence and interactions using a deep ontology-aware classifier
May 15, 2017

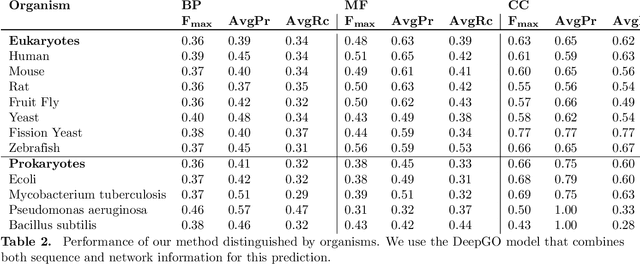

A large number of protein sequences are becoming available through the application of novel high-throughput sequencing technologies. Experimental functional characterization of these proteins is time-consuming and expensive, and is often only done rigorously for few selected model organisms. Computational function prediction approaches have been suggested to fill this gap. The functions of proteins are classified using the Gene Ontology (GO), which contains over 40,000 classes. Additionally, proteins have multiple functions, making function prediction a large-scale, multi-class, multi-label problem. We have developed a novel method to predict protein function from sequence. We use deep learning to learn features from protein sequences as well as a cross-species protein-protein interaction network. Our approach specifically outputs information in the structure of the GO and utilizes the dependencies between GO classes as background information to construct a deep learning model. We evaluate our method using the standards established by the Computational Assessment of Function Annotation (CAFA) and demonstrate a significant improvement over baseline methods such as BLAST, with significant improvement for predicting cellular locations.