 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTry-On-Adapter: A Simple and Flexible Try-On Paradigm
Nov 15, 2024
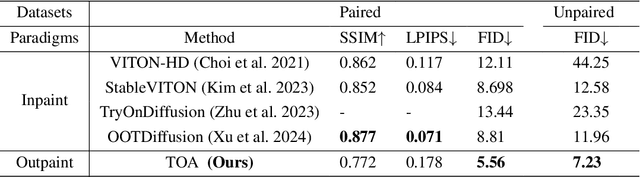
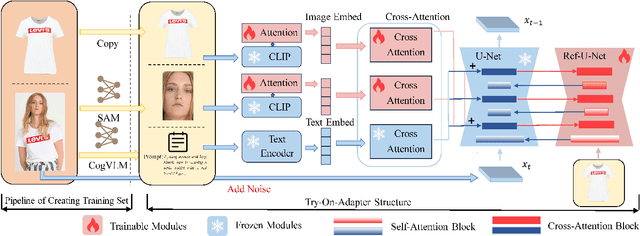

Image-based virtual try-on, widely used in online shopping, aims to generate images of a naturally dressed person conditioned on certain garments, providing significant research and commercial potential. A key challenge of try-on is to generate realistic images of the model wearing the garments while preserving the details of the garments. Previous methods focus on masking certain parts of the original model's standing image, and then inpainting on masked areas to generate realistic images of the model wearing corresponding reference garments, which treat the try-on task as an inpainting task. However, such implements require the user to provide a complete, high-quality standing image, which is user-unfriendly in practical applications. In this paper, we propose Try-On-Adapter (TOA), an outpainting paradigm that differs from the existing inpainting paradigm. Our TOA can preserve the given face and garment, naturally imagine the rest parts of the image, and provide flexible control ability with various conditions, e.g., garment properties and human pose. In the experiments, TOA shows excellent performance on the virtual try-on task even given relatively low-quality face and garment images in qualitative comparisons. Additionally, TOA achieves the state-of-the-art performance of FID scores 5.56 and 7.23 for paired and unpaired on the VITON-HD dataset in quantitative comparisons.
SEIHAI: A Sample-efficient Hierarchical AI for the MineRL Competition
Nov 17, 2021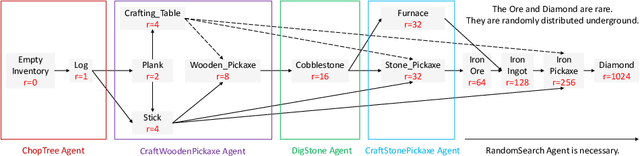
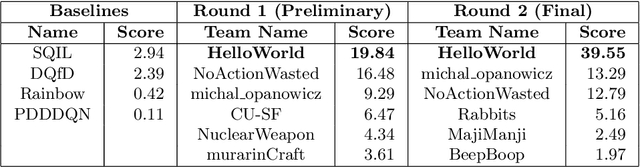

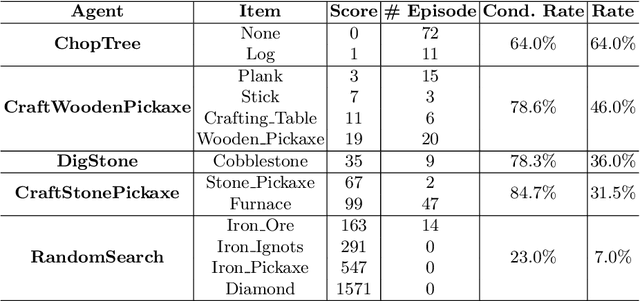
The MineRL competition is designed for the development of reinforcement learning and imitation learning algorithms that can efficiently leverage human demonstrations to drastically reduce the number of environment interactions needed to solve the complex \emph{ObtainDiamond} task with sparse rewards. To address the challenge, in this paper, we present \textbf{SEIHAI}, a \textbf{S}ample-\textbf{e}ff\textbf{i}cient \textbf{H}ierarchical \textbf{AI}, that fully takes advantage of the human demonstrations and the task structure. Specifically, we split the task into several sequentially dependent subtasks, and train a suitable agent for each subtask using reinforcement learning and imitation learning. We further design a scheduler to select different agents for different subtasks automatically. SEIHAI takes the first place in the preliminary and final of the NeurIPS-2020 MineRL competition.
DoubleEnsemble: A New Ensemble Method Based on Sample Reweighting and Feature Selection for Financial Data Analysis
Oct 03, 2020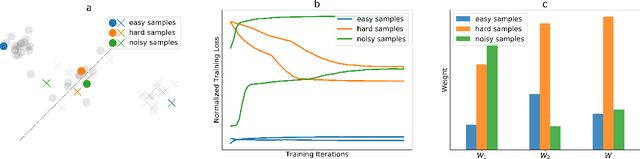
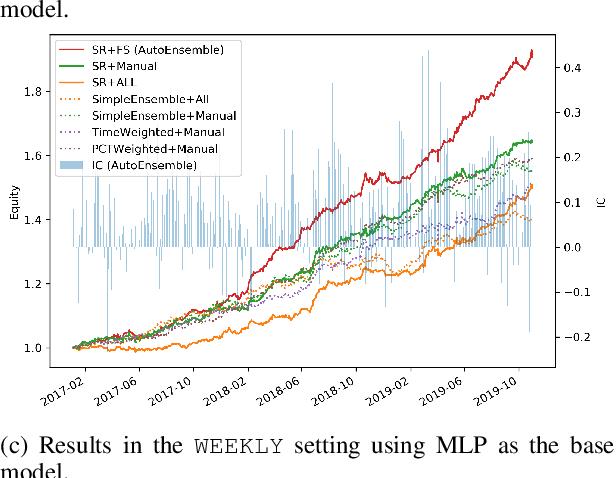
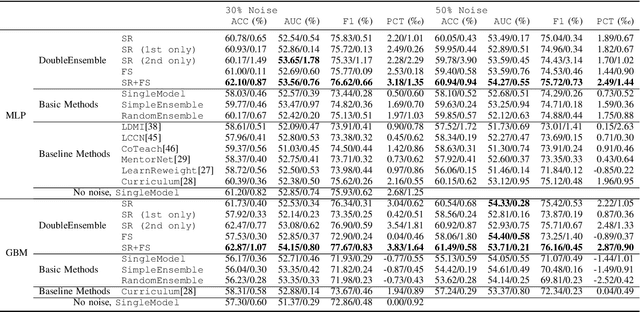
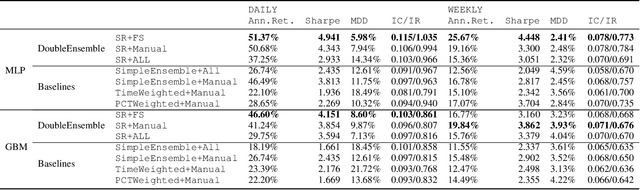
Modern machine learning models (such as deep neural networks and boosting decision tree models) have become increasingly popular in financial market prediction, due to their superior capacity to extract complex non-linear patterns. However, since financial datasets have very low signal-to-noise ratio and are non-stationary, complex models are often very prone to overfitting and suffer from instability issues. Moreover, as various machine learning and data mining tools become more widely used in quantitative trading, many trading firms have been producing an increasing number of features (aka factors). Therefore, how to automatically select effective features becomes an imminent problem. To address these issues, we propose DoubleEnsemble, an ensemble framework leveraging learning trajectory based sample reweighting and shuffling based feature selection. Specifically, we identify the key samples based on the training dynamics on each sample and elicit key features based on the ablation impact of each feature via shuffling. Our model is applicable to a wide range of base models, capable of extracting complex patterns, while mitigating the overfitting and instability issues for financial market prediction. We conduct extensive experiments, including price prediction for cryptocurrencies and stock trading, using both DNN and gradient boosting decision tree as base models. Our experiment results demonstrate that DoubleEnsemble achieves a superior performance compared with several baseline methods.
Deterministic Value-Policy Gradients
Sep 09, 2019
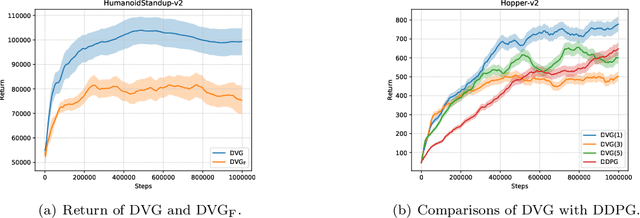
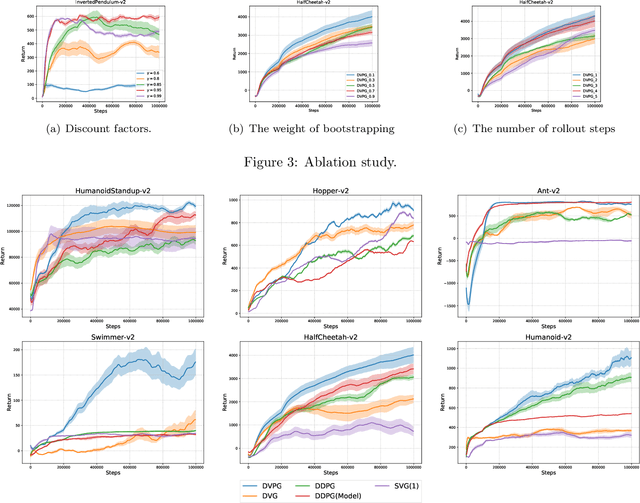
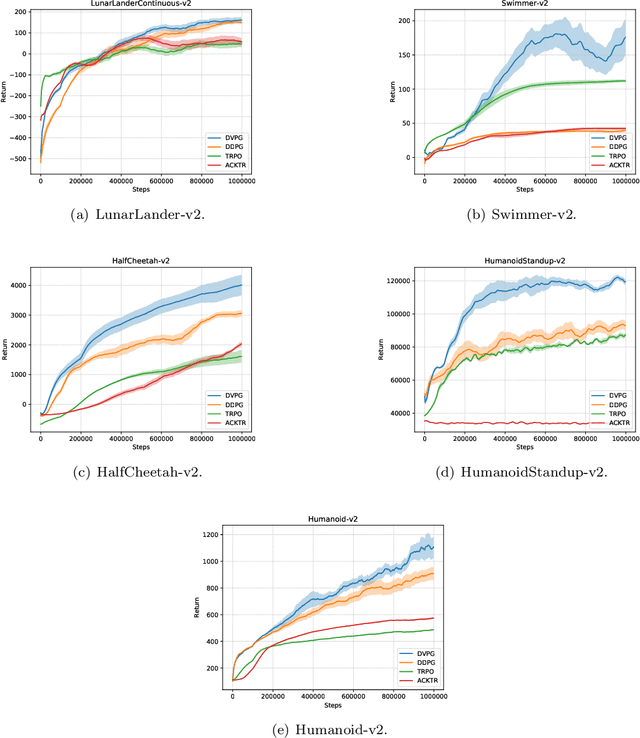
Reinforcement learning algorithms such as the deep deterministic policy gradient algorithm (DDPG) has been widely used in continuous control tasks. However, the model-free DDPG algorithm suffers from high sample complexity. In this paper we consider the deterministic value gradients to improve the sample efficiency of deep reinforcement learning algorithms. Previous works consider deterministic value gradients with the finite horizon, but it is too myopic compared with infinite horizon. We firstly give a theoretical guarantee of the existence of the value gradients in this infinite setting. Based on this theoretical guarantee, we propose a class of the deterministic value gradient algorithm (DVG) with infinite horizon, and different rollout steps of the analytical gradients by the learned model trade off between the variance of the value gradients and the model bias. Furthermore, to better combine the model-based deterministic value gradient estimators with the model-free deterministic policy gradient estimator, we propose the deterministic value-policy gradient (DVPG) algorithm. We finally conduct extensive experiments comparing DVPG with state-of-the-art methods on several standard continuous control benchmarks. Results demonstrate that DVPG substantially outperforms other baselines.
Towards reliable and fair probabilistic predictions: field-aware calibration with neural networks
May 28, 2019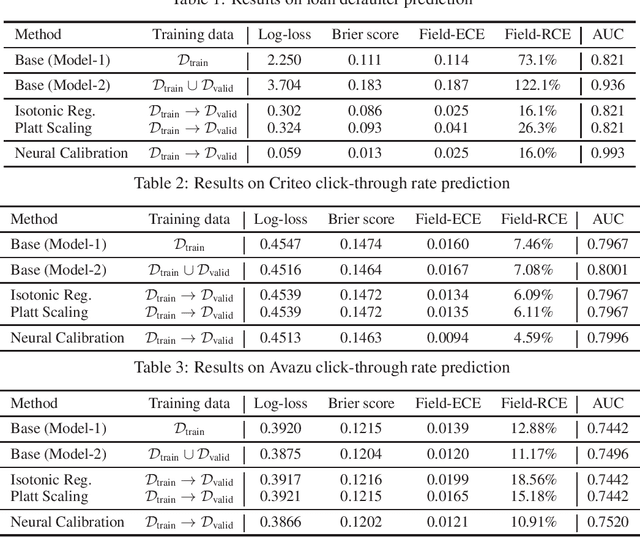
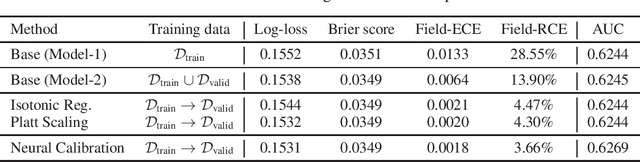
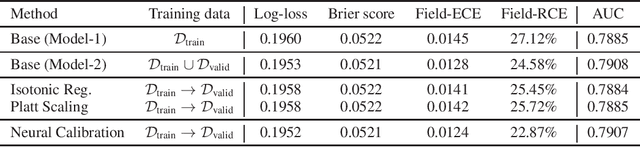
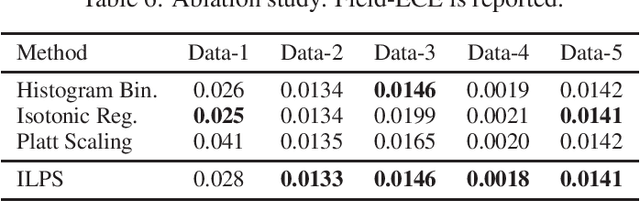
In machine learning, it is observed that probabilistic predictions sometimes disagree with averaged actual outcomes on certain subsets of data. This is also known as miscalibration that is responsible for unreliability and unfairness of practical machine learning systems. In this paper, we put forward an evaluation metric for calibration, coined field-level calibration error, that measures bias in predictions over the input fields that the decision maker concerns. We show that existing calibration methods perform poorly under our new metric. Specifically, after learning a calibration mapping over the validation dataset, existing methods have limited improvements in our error metric and completely fail to improve other non-calibration metrics such as the AUC score. We propose Neural Calibration, a new calibration method, which learns to calibrate by making full use of all input information over the validation set. We test our method on five large-scale real-world datasets. The results show that Neural Calibration significantly improves against uncalibrated predictions in all well-known metrics such as the negative log-likelihood, the Brier score, the AUC score, as well as our proposed field-level calibration error.
Warm Up Cold-start Advertisements: Improving CTR Predictions via Learning to Learn ID Embeddings
Apr 25, 2019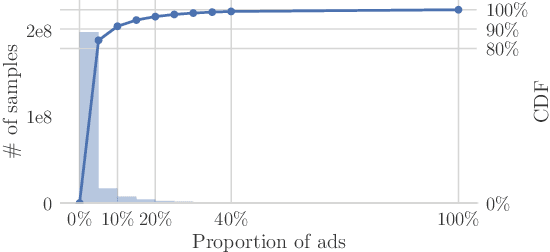
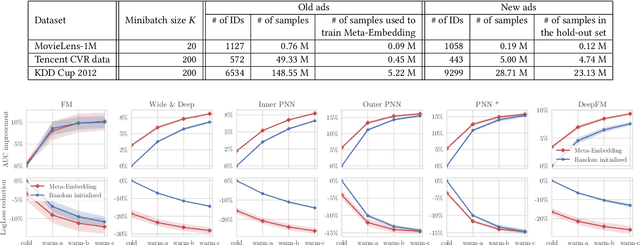
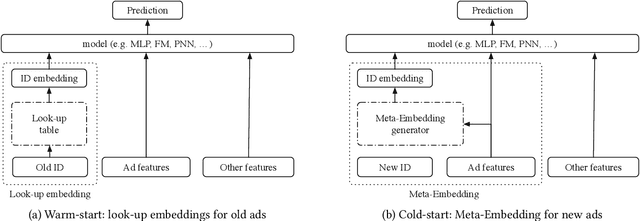
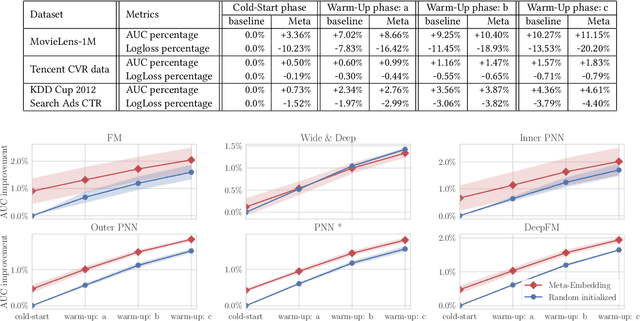
Click-through rate (CTR) prediction has been one of the most central problems in computational advertising. Lately, embedding techniques that produce low-dimensional representations of ad IDs drastically improve CTR prediction accuracies. However, such learning techniques are data demanding and work poorly on new ads with little logging data, which is known as the cold-start problem. In this paper, we aim to improve CTR predictions during both the cold-start phase and the warm-up phase when a new ad is added to the candidate pool. We propose Meta-Embedding, a meta-learning-based approach that learns to generate desirable initial embeddings for new ad IDs. The proposed method trains an embedding generator for new ad IDs by making use of previously learned ads through gradient-based meta-learning. In other words, our method learns how to learn better embeddings. When a new ad comes, the trained generator initializes the embedding of its ID by feeding its contents and attributes. Next, the generated embedding can speed up the model fitting during the warm-up phase when a few labeled examples are available, compared to the existing initialization methods. Experimental results on three real-world datasets showed that Meta-Embedding can significantly improve both the cold-start and warm-up performances for six existing CTR prediction models, ranging from lightweight models such as Factorization Machines to complicated deep models such as PNN and DeepFM. All of the above apply to conversion rate (CVR) predictions as well.
Policy Optimization with Model-based Explorations
Nov 18, 2018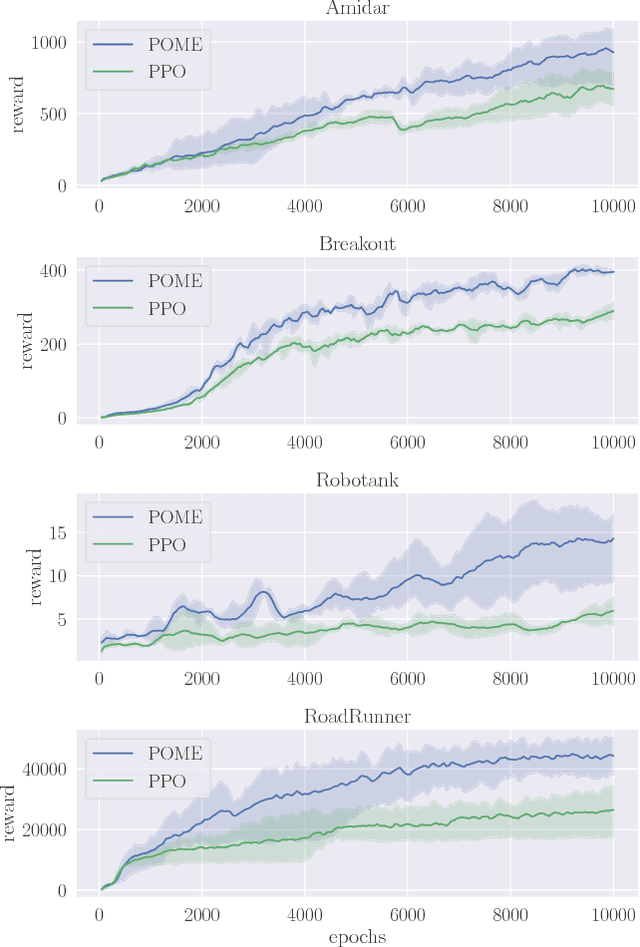
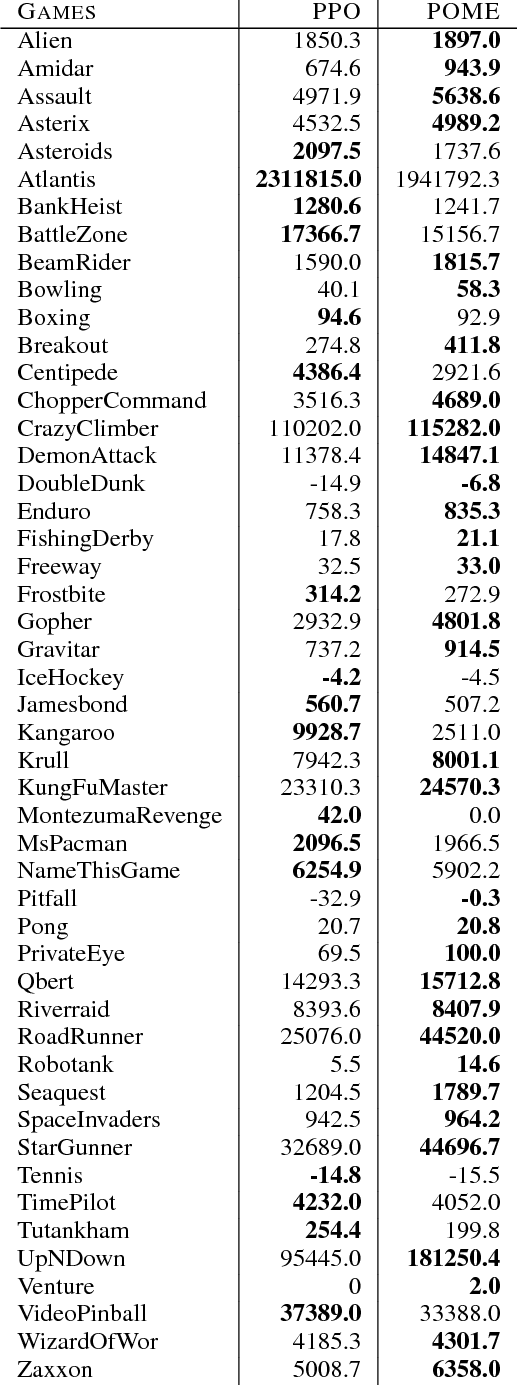
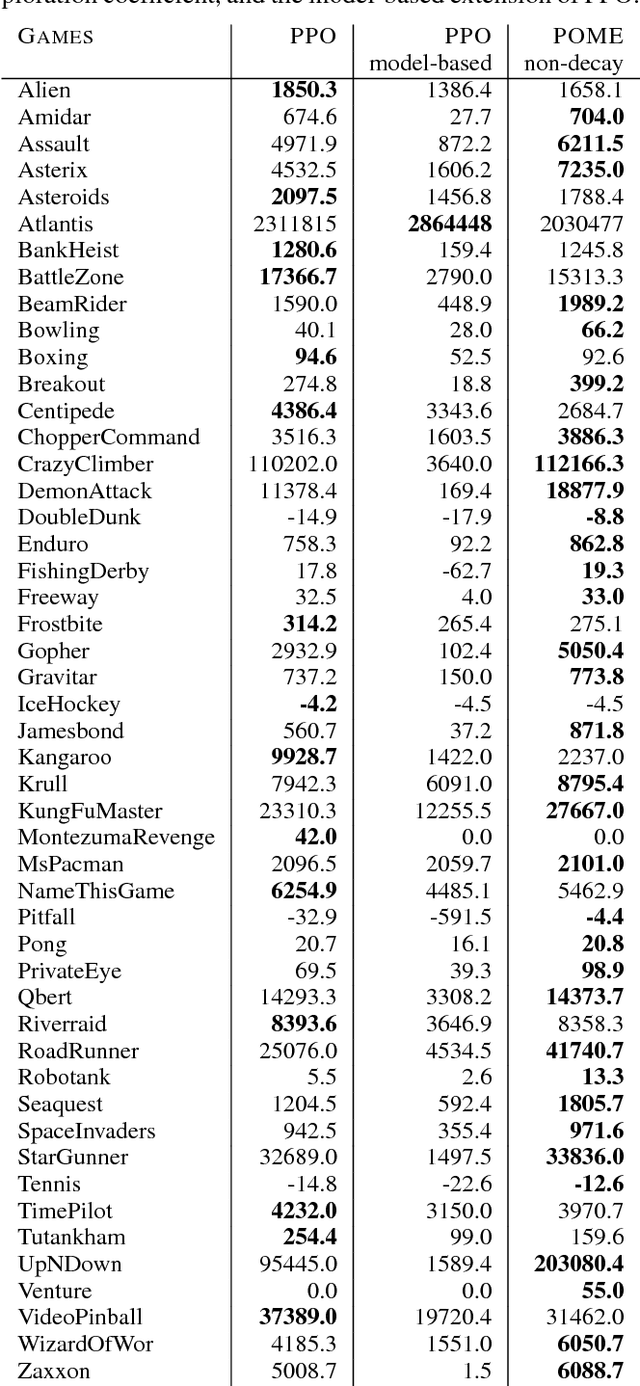
Model-free reinforcement learning methods such as the Proximal Policy Optimization algorithm (PPO) have successfully applied in complex decision-making problems such as Atari games. However, these methods suffer from high variances and high sample complexity. On the other hand, model-based reinforcement learning methods that learn the transition dynamics are more sample efficient, but they often suffer from the bias of the transition estimation. How to make use of both model-based and model-free learning is a central problem in reinforcement learning. In this paper, we present a new technique to address the trade-off between exploration and exploitation, which regards the difference between model-free and model-based estimations as a measure of exploration value. We apply this new technique to the PPO algorithm and arrive at a new policy optimization method, named Policy Optimization with Model-based Explorations (POME). POME uses two components to predict the actions' target values: a model-free one estimated by Monte-Carlo sampling and a model-based one which learns a transition model and predicts the value of the next state. POME adds the error of these two target estimations as the additional exploration value for each state-action pair, i.e, encourages the algorithm to explore the states with larger target errors which are hard to estimate. We compare POME with PPO on Atari 2600 games, and it shows that POME outperforms PPO on 33 games out of 49 games.
Deterministic Policy Gradients With General State Transitions
Oct 02, 2018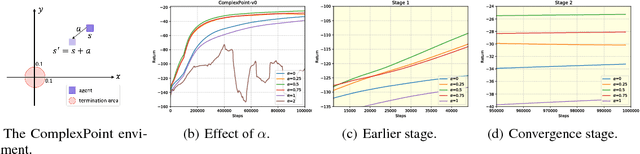
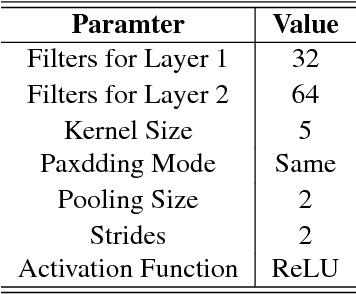
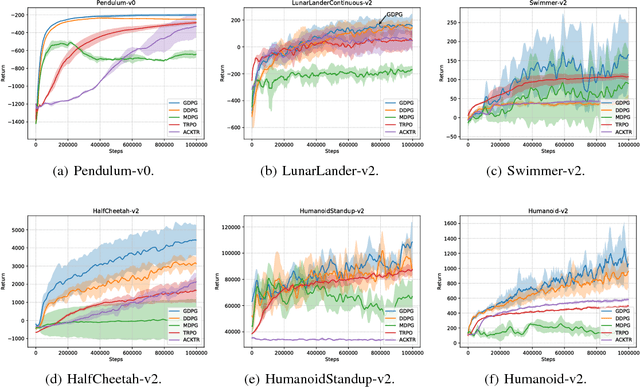
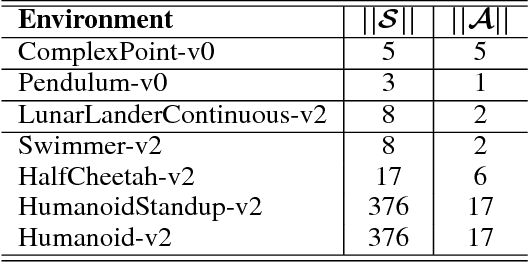
We study a reinforcement learning setting, where the state transition function is a convex combination of a stochastic continuous function and a deterministic function. Such a setting generalizes the widely-studied stochastic state transition setting, namely the setting of deterministic policy gradient (DPG). We firstly give a simple example to illustrate that the deterministic policy gradient may be infinite under deterministic state transitions, and introduce a theoretical technique to prove the existence of the policy gradient in this generalized setting. Using this technique, we prove that the deterministic policy gradient indeed exists for a certain set of discount factors, and further prove two conditions that guarantee the existence for all discount factors. We then derive a closed form of the policy gradient whenever exists. Furthermore, to overcome the challenge of high sample complexity of DPG in this setting, we propose the Generalized Deterministic Policy Gradient (GDPG) algorithm. The main innovation of the algorithm is a new method of applying model-based techniques to the model-free algorithm, the deep deterministic policy gradient algorithm (DDPG). GDPG optimize the long-term rewards of the model-based augmented MDP subject to a constraint that the long-rewards of the MDP is less than the original one. We finally conduct extensive experiments comparing GDPG with state-of-the-art methods and the direct model-based extension method of DDPG on several standard continuous control benchmarks. Results demonstrate that GDPG substantially outperforms DDPG, the model-based extension of DDPG and other baselines in terms of both convergence and long-term rewards in most environments.
Rebalancing Dockless Bike Sharing Systems
Sep 10, 2018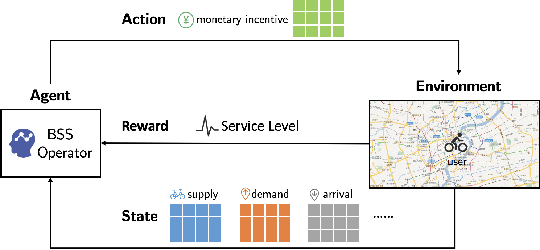


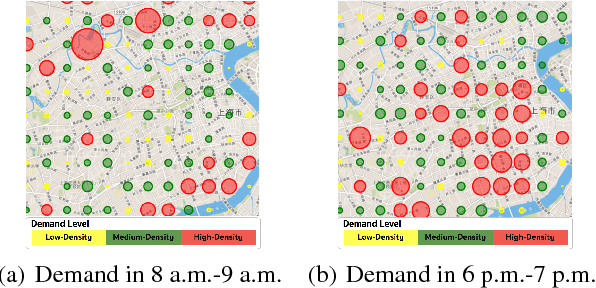
Bike sharing provides an environment-friendly way for traveling and is booming all over the world. Yet, due to the high similarity of user travel patterns, the bike imbalance problem constantly occurs, especially for dockless bike sharing systems, causing significant impact on service quality and company revenue. Thus, it has become a critical task for bike sharing systems to resolve such imbalance efficiently. In this paper, we propose a novel deep reinforcement learning framework for incentivizing users to rebalance such systems. We model the problem as a Markov decision process and take both spatial and temporal features into consideration. We develop a novel deep reinforcement learning algorithm called Hierarchical Reinforcement Pricing (HRP), which builds upon the Deep Deterministic Policy Gradient algorithm. Different from existing methods that often ignore spatial information and rely heavily on accurate prediction, HRP captures both spatial and temporal dependencies using a divide-and-conquer structure with an embedded localized module. We conduct extensive experiments to evaluate HRP, based on a dataset from Mobike, a major Chinese dockless bike sharing company. Results show that HRP performs close to the 24-timeslot look-ahead optimization, and outperforms state-of-the-art methods in both service level and bike distribution. It also transfers well when applied to unseen areas.
Policy Gradients for General Contextual Bandits
May 22, 2018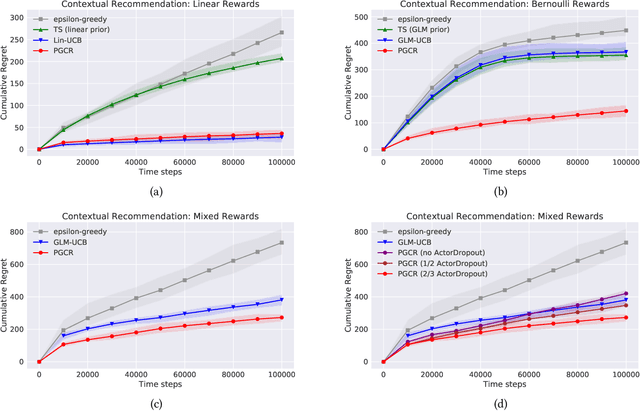
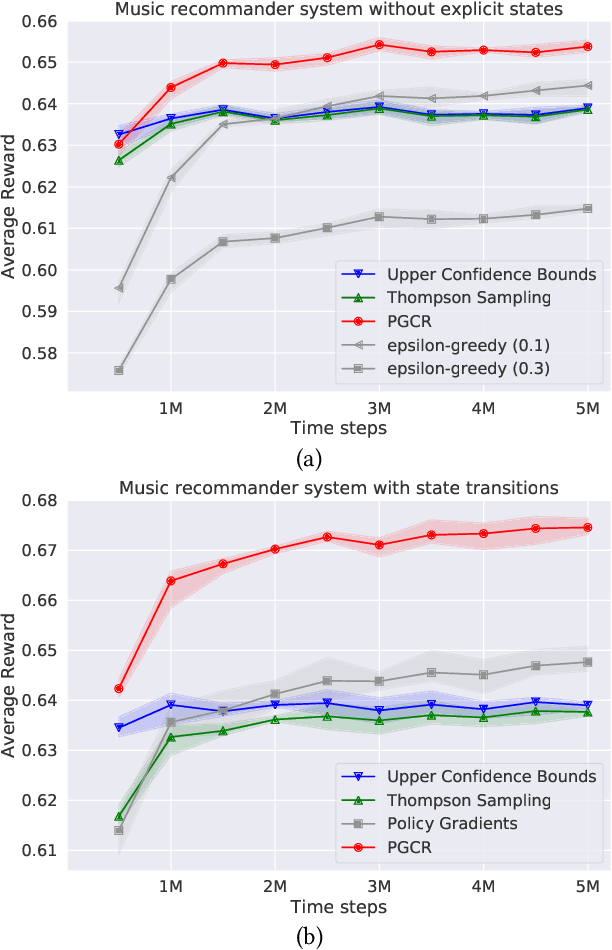
Contextual bandits algorithms have been successfully deployed to various industrial applications for the trade-off between exploration and exploitation and the state-of-art performance on minimizing online costs. However, the applicability is limited by the over-simplified assumptions on the problem, such as assuming the rewards linearly depend on the contexts, or assuming a static environment where the states are not affected by previous actions. In this work, we put forward an alternative method for general contextual bandits using actor-critic neural networks to directly optimize in the policy space, coined policy gradient for contextual bandits (PGCB). It optimizes over a class of policies in which the marginal probability of choosing an arm (in expectation of other arms) has a simple closed form so that the objective is differentiable. In particular, the gradient of this class of policies is in a succinct form. Moreover, we propose two useful heuristic techniques called Time-Dependent Greed and Actor-Dropout. The former ensures PGCB to be empirically greedy in the limit, while the later balances a trade-off between exploration and exploitation by using the actor-network with dropout as a Bayesian approximation. PGCB can solve contextual bandits in the standard case as well as the Markov Decision Process generalization where there is a state that decides the distribution of contexts of arms and affects the immediate reward when choosing an arm, therefore can be applied to a wide range of realistic settings such as personalized recommender systems and natural language generations. We evaluate PGCB on toy datasets as well as a music recommender dataset. Experiments show that PGCB has fast convergence and low regret and outperforms both classic contextual-bandits methods and vanilla policy gradient methods.