 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling the Implicit Multi-Branch Structure in LLMs' Reasoning via Reinforcement Learning
May 22, 2025Distilling reasoning paths from teacher to student models via supervised fine-tuning (SFT) provides a shortcut for improving the reasoning ability of smaller Large Language Models (LLMs). However, the reasoning paths generated by teacher models often reflect only surface-level traces of their underlying authentic reasoning. Insights from cognitive neuroscience suggest that authentic reasoning involves a complex interweaving between meta-reasoning (which selects appropriate sub-problems from multiple candidates) and solving (which addresses the sub-problem). This implies authentic reasoning has an implicit multi-branch structure. Supervised fine-tuning collapses this rich structure into a flat sequence of token prediction in the teacher's reasoning path, preventing effective distillation of this structure to students. To address this limitation, we propose RLKD, a reinforcement learning (RL)-based distillation framework guided by a novel Generative Structure Reward Model (GSRM). Our GSRM converts reasoning paths into multiple meta-reasoning-solving steps and computes rewards to measure structural alignment between student and teacher reasoning. RLKD combines this reward with RL, enabling student LLMs to internalize the teacher's implicit multi-branch reasoning structure rather than merely mimicking fixed output paths. Experiments show RLKD surpasses standard SFT-RL pipelines even when trained on 0.1% of data under an RL-only regime, unlocking greater student reasoning potential than SFT-based distillation.
Cross-Modal Safety Mechanism Transfer in Large Vision-Language Models
Oct 16, 2024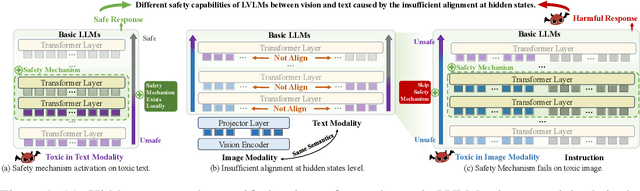
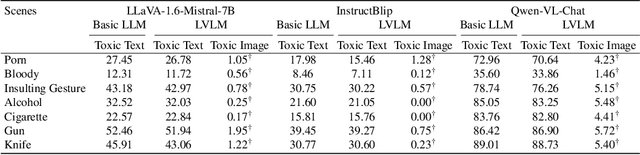
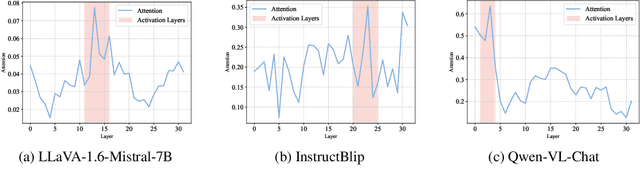
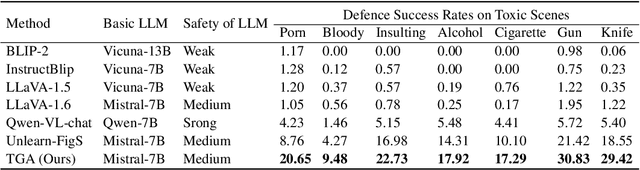
Vision-language alignment in Large Vision-Language Models (LVLMs) successfully enables LLMs to understand visual input. However, we find that existing vision-language alignment methods fail to transfer the existing safety mechanism for text in LLMs to vision, which leads to vulnerabilities in toxic image. To explore the cause of this problem, we give the insightful explanation of where and how the safety mechanism of LVLMs operates and conduct comparative analysis between text and vision. We find that the hidden states at the specific transformer layers play a crucial role in the successful activation of safety mechanism, while the vision-language alignment at hidden states level in current methods is insufficient. This results in a semantic shift for input images compared to text in hidden states, therefore misleads the safety mechanism. To address this, we propose a novel Text-Guided vision-language Alignment method (TGA) for LVLMs. TGA retrieves the texts related to input vision and uses them to guide the projection of vision into the hidden states space in LLMs. Experiments show that TGA not only successfully transfers the safety mechanism for text in basic LLMs to vision in vision-language alignment for LVLMs without any safety fine-tuning on the visual modality but also maintains the general performance on various vision tasks (Safe and Good).
Cross-Model Comparative Loss for Enhancing Neuronal Utility in Language Understanding
Jan 10, 2023



Current natural language understanding (NLU) models have been continuously scaling up, both in terms of model size and input context, introducing more hidden and input neurons. While this generally improves performance on average, the extra neurons do not yield a consistent improvement for all instances. This is because some hidden neurons are redundant, and the noise mixed in input neurons tends to distract the model. Previous work mainly focuses on extrinsically reducing low-utility neurons by additional post- or pre-processing, such as network pruning and context selection, to avoid this problem. Beyond that, can we make the model reduce redundant parameters and suppress input noise by intrinsically enhancing the utility of each neuron? If a model can efficiently utilize neurons, no matter which neurons are ablated (disabled), the ablated submodel should perform no better than the original full model. Based on such a comparison principle between models, we propose a cross-model comparative loss for a broad range of tasks. Comparative loss is essentially a ranking loss on top of the task-specific losses of the full and ablated models, with the expectation that the task-specific loss of the full model is minimal. We demonstrate the universal effectiveness of comparative loss through extensive experiments on 14 datasets from 3 distinct NLU tasks based on 4 widely used pretrained language models, and find it particularly superior for models with few parameters or long input.
LoL: A Comparative Regularization Loss over Query Reformulation Losses for Pseudo-Relevance Feedback
Apr 25, 2022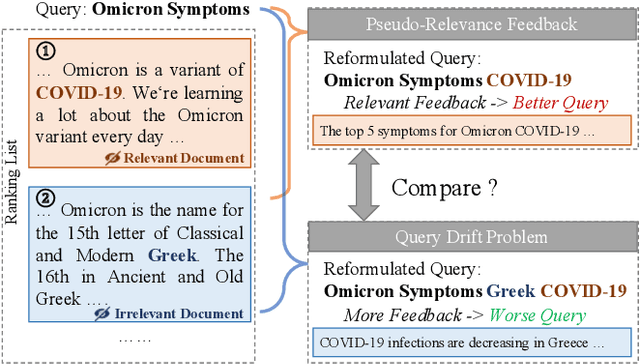
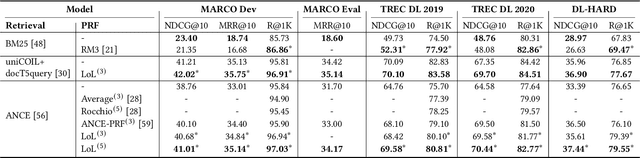
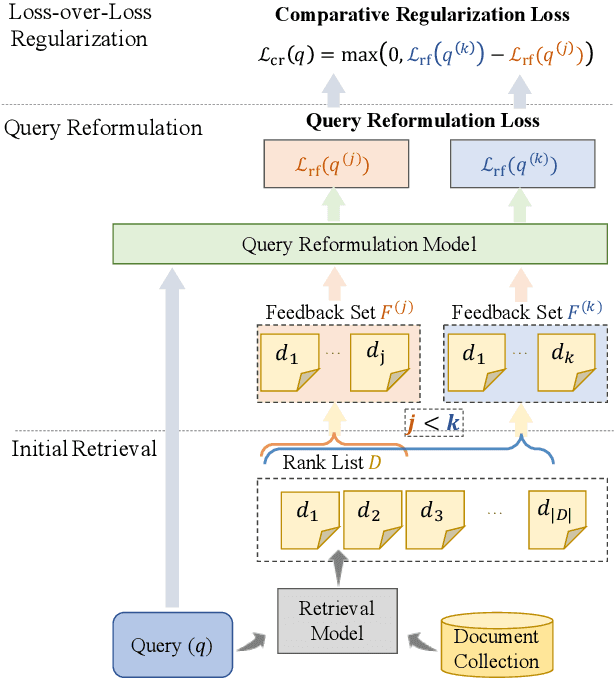
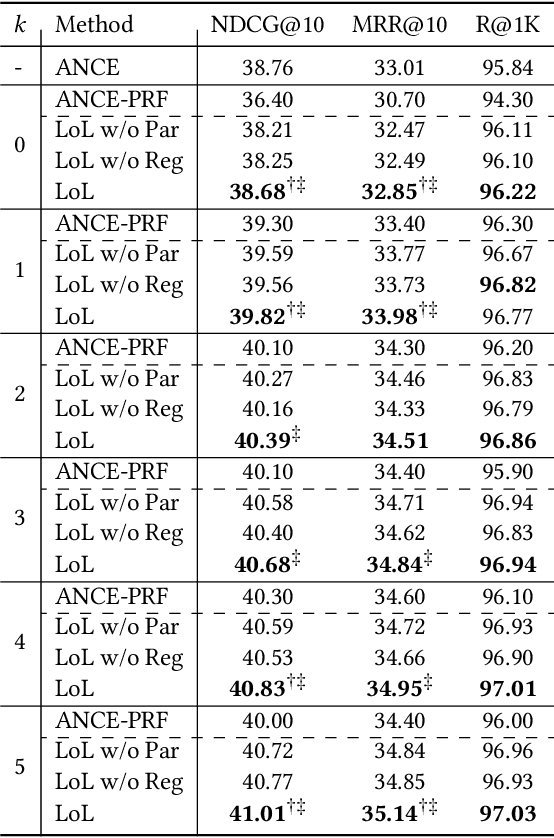
Pseudo-relevance feedback (PRF) has proven to be an effective query reformulation technique to improve retrieval accuracy. It aims to alleviate the mismatch of linguistic expressions between a query and its potential relevant documents. Existing PRF methods independently treat revised queries originating from the same query but using different numbers of feedback documents, resulting in severe query drift. Without comparing the effects of two different revisions from the same query, a PRF model may incorrectly focus on the additional irrelevant information increased in the more feedback, and thus reformulate a query that is less effective than the revision using the less feedback. Ideally, if a PRF model can distinguish between irrelevant and relevant information in the feedback, the more feedback documents there are, the better the revised query will be. To bridge this gap, we propose the Loss-over-Loss (LoL) framework to compare the reformulation losses between different revisions of the same query during training. Concretely, we revise an original query multiple times in parallel using different amounts of feedback and compute their reformulation losses. Then, we introduce an additional regularization loss on these reformulation losses to penalize revisions that use more feedback but gain larger losses. With such comparative regularization, the PRF model is expected to learn to suppress the extra increased irrelevant information by comparing the effects of different revised queries. Further, we present a differentiable query reformulation method to implement this framework. This method revises queries in the vector space and directly optimizes the retrieval performance of query vectors, applicable for both sparse and dense retrieval models. Empirical evaluation demonstrates the effectiveness and robustness of our method for two typical sparse and dense retrieval models.
Adaptive Information Seeking for Open-Domain Question Answering
Sep 14, 2021
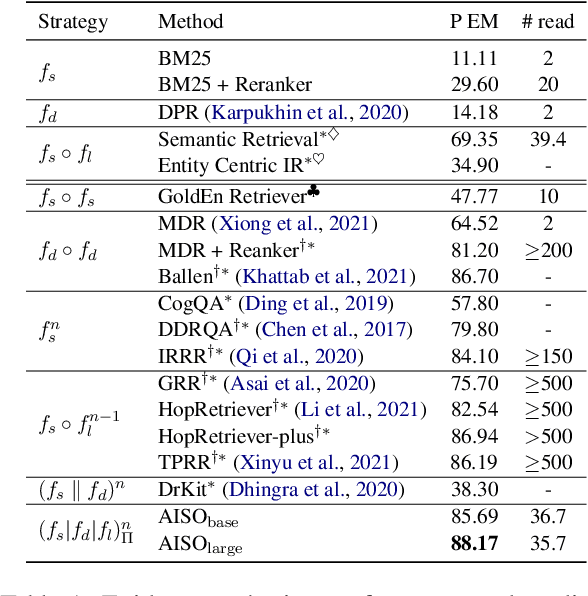
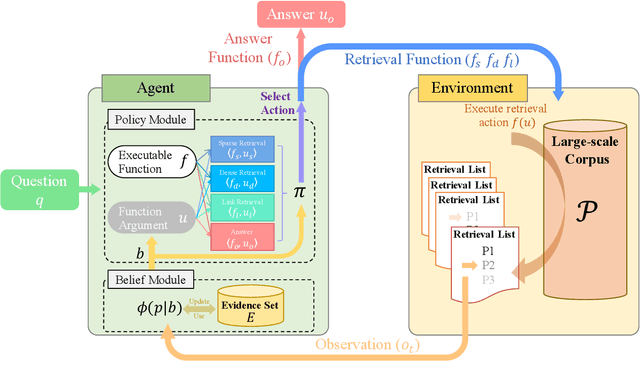
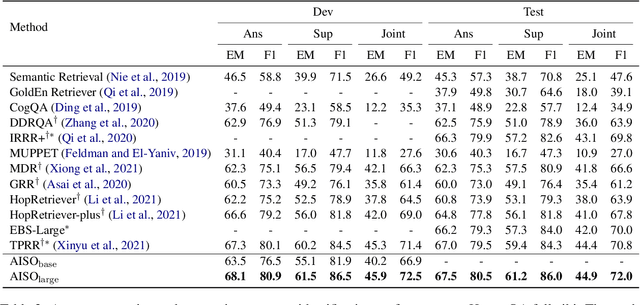
Information seeking is an essential step for open-domain question answering to efficiently gather evidence from a large corpus. Recently, iterative approaches have been proven to be effective for complex questions, by recursively retrieving new evidence at each step. However, almost all existing iterative approaches use predefined strategies, either applying the same retrieval function multiple times or fixing the order of different retrieval functions, which cannot fulfill the diverse requirements of various questions. In this paper, we propose a novel adaptive information-seeking strategy for open-domain question answering, namely AISO. Specifically, the whole retrieval and answer process is modeled as a partially observed Markov decision process, where three types of retrieval operations (e.g., BM25, DPR, and hyperlink) and one answer operation are defined as actions. According to the learned policy, AISO could adaptively select a proper retrieval action to seek the missing evidence at each step, based on the collected evidence and the reformulated query, or directly output the answer when the evidence set is sufficient for the question. Experiments on SQuAD Open and HotpotQA fullwiki, which serve as single-hop and multi-hop open-domain QA benchmarks, show that AISO outperforms all baseline methods with predefined strategies in terms of both retrieval and answer evaluations.
L2R2: Leveraging Ranking for Abductive Reasoning
May 22, 2020
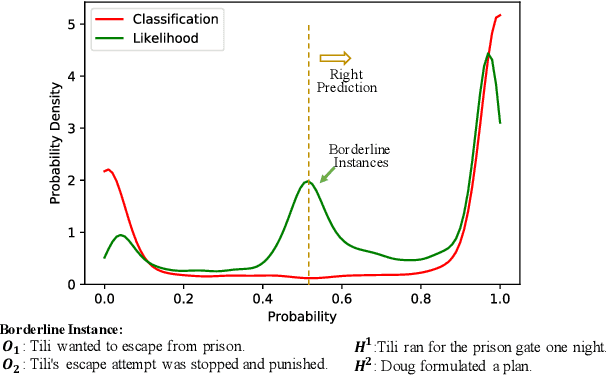
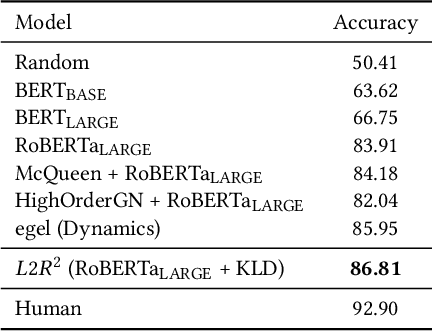
The abductive natural language inference task ($\alpha$NLI) is proposed to evaluate the abductive reasoning ability of a learning system. In the $\alpha$NLI task, two observations are given and the most plausible hypothesis is asked to pick out from the candidates. Existing methods simply formulate it as a classification problem, thus a cross-entropy log-loss objective is used during training. However, discriminating true from false does not measure the plausibility of a hypothesis, for all the hypotheses have a chance to happen, only the probabilities are different. To fill this gap, we switch to a ranking perspective that sorts the hypotheses in order of their plausibilities. With this new perspective, a novel $L2R^2$ approach is proposed under the learning-to-rank framework. Firstly, training samples are reorganized into a ranking form, where two observations and their hypotheses are treated as the query and a set of candidate documents respectively. Then, an ESIM model or pre-trained language model, e.g. BERT or RoBERTa, is obtained as the scoring function. Finally, the loss functions for the ranking task can be either pair-wise or list-wise for training. The experimental results on the ART dataset reach the state-of-the-art in the public leaderboard.