 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep-Learning-Based Control of a Decoupled Two-Segment Continuum Robot for Endoscopic Submucosal Dissection
Feb 03, 2026Manual endoscopic submucosal dissection (ESD) is technically demanding, and existing single-segment robotic tools offer limited dexterity. These limitations motivate the development of more advanced solutions. To address this, DESectBot, a novel dual segment continuum robot with a decoupled structure and integrated surgical forceps, enabling 6 degrees of freedom (DoFs) tip dexterity for improved lesion targeting in ESD, was developed in this work. Deep learning controllers based on gated recurrent units (GRUs) for simultaneous tip position and orientation control, effectively handling the nonlinear coupling between continuum segments, were proposed. The GRU controller was benchmarked against Jacobian based inverse kinematics, model predictive control (MPC), a feedforward neural network (FNN), and a long short-term memory (LSTM) network. In nested-rectangle and Lissajous trajectory tracking tasks, the GRU achieved the lowest position/orientation RMSEs: 1.11 mm/ 4.62° and 0.81 mm/ 2.59°, respectively. For orientation control at a fixed position (four target poses), the GRU attained a mean RMSE of 0.14 mm and 0.72°, outperforming all alternatives. In a peg transfer task, the GRU achieved a 100% success rate (120 success/120 attempts) with an average transfer time of 11.8s, the STD significantly outperforms novice-controlled systems. Additionally, an ex vivo ESD demonstration grasping, elevating, and resecting tissue as the scalpel completed the cut confirmed that DESectBot provides sufficient stiffness to divide thick gastric mucosa and an operative workspace adequate for large lesions.These results confirm that GRU-based control significantly enhances precision, reliability, and usability in ESD surgical training scenarios.
D-Models and E-Models: Diversity-Stability Trade-offs in the Sampling Behavior of Large Language Models
Jan 25, 2026The predictive probability of the next token (P_token) in large language models (LLMs) is inextricably linked to the probability of relevance for the next piece of information, the purchase probability of the next product, and the execution probability of the next action-all of which fall under the scope of the task-level target distribution (P_task). While LLMs are known to generate samples that approximate real-world distributions, whether their fine-grained sampling probabilities faithfully align with task requirements remains an open question. Through controlled distribution-sampling simulations, we uncover a striking dichotomy in LLM behavior, distinguishing two model types: D-models (e.g. Qwen-2.5), whose P_token exhibits large step-to-step variability and poor alignment with P_task; and E-models (e.g. Mistral-Small), whose P_token is more stable and better aligned with P_task. We further evaluate these two model types in downstream tasks such as code generation and recommendation, revealing systematic trade-offs between diversity and stability that shape task outcomes. Finally, we analyze the internal properties of both model families to probe their underlying mechanisms. These findings offer foundational insights into the probabilistic sampling behavior of LLMs and provide practical guidance on when to favor D- versus E-models. For web-scale applications, including recommendation, search, and conversational agents, our results inform model selection and configuration to balance diversity with reliability under real-world uncertainty, providing a better level of interpretation.
Rethinking Bias in Generative Data Augmentation for Medical AI: a Frequency Recalibration Method
Nov 15, 2025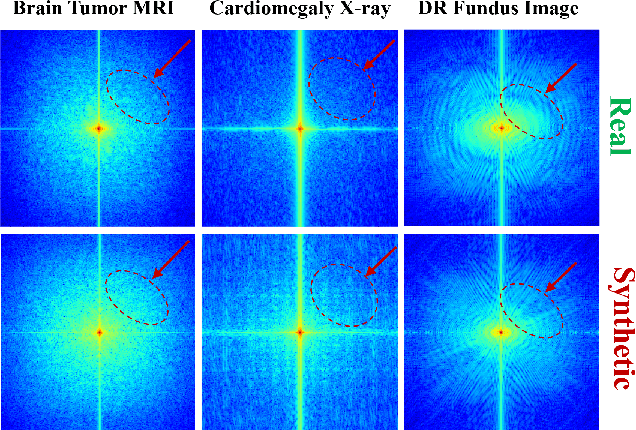

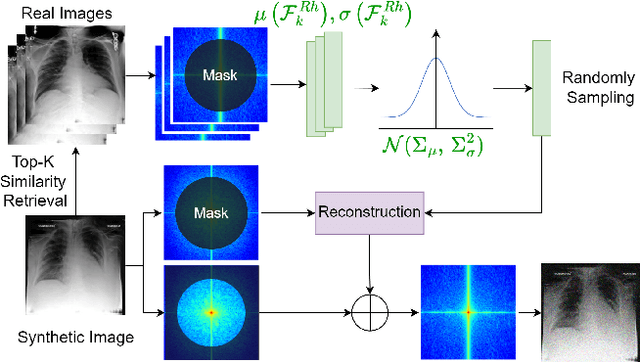
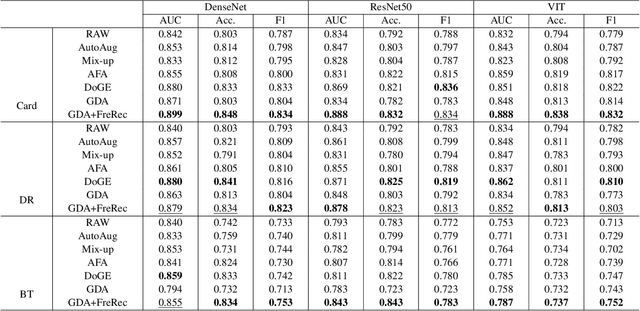
Developing Medical AI relies on large datasets and easily suffers from data scarcity. Generative data augmentation (GDA) using AI generative models offers a solution to synthesize realistic medical images. However, the bias in GDA is often underestimated in medical domains, with concerns about the risk of introducing detrimental features generated by AI and harming downstream tasks. This paper identifies the frequency misalignment between real and synthesized images as one of the key factors underlying unreliable GDA and proposes the Frequency Recalibration (FreRec) method to reduce the frequency distributional discrepancy and thus improve GDA. FreRec involves (1) Statistical High-frequency Replacement (SHR) to roughly align high-frequency components and (2) Reconstructive High-frequency Mapping (RHM) to enhance image quality and reconstruct high-frequency details. Extensive experiments were conducted in various medical datasets, including brain MRIs, chest X-rays, and fundus images. The results show that FreRec significantly improves downstream medical image classification performance compared to uncalibrated AI-synthesized samples. FreRec is a standalone post-processing step that is compatible with any generative model and can integrate seamlessly with common medical GDA pipelines.
Distilling the Implicit Multi-Branch Structure in LLMs' Reasoning via Reinforcement Learning
May 22, 2025Distilling reasoning paths from teacher to student models via supervised fine-tuning (SFT) provides a shortcut for improving the reasoning ability of smaller Large Language Models (LLMs). However, the reasoning paths generated by teacher models often reflect only surface-level traces of their underlying authentic reasoning. Insights from cognitive neuroscience suggest that authentic reasoning involves a complex interweaving between meta-reasoning (which selects appropriate sub-problems from multiple candidates) and solving (which addresses the sub-problem). This implies authentic reasoning has an implicit multi-branch structure. Supervised fine-tuning collapses this rich structure into a flat sequence of token prediction in the teacher's reasoning path, preventing effective distillation of this structure to students. To address this limitation, we propose RLKD, a reinforcement learning (RL)-based distillation framework guided by a novel Generative Structure Reward Model (GSRM). Our GSRM converts reasoning paths into multiple meta-reasoning-solving steps and computes rewards to measure structural alignment between student and teacher reasoning. RLKD combines this reward with RL, enabling student LLMs to internalize the teacher's implicit multi-branch reasoning structure rather than merely mimicking fixed output paths. Experiments show RLKD surpasses standard SFT-RL pipelines even when trained on 0.1% of data under an RL-only regime, unlocking greater student reasoning potential than SFT-based distillation.
Do LLMs Play Dice? Exploring Probability Distribution Sampling in Large Language Models for Behavioral Simulation
Apr 13, 2024With the rapid advancement of large language models (LLMs) and their remarkable capabilities in handling complex language tasks, an increasing number of studies are employing LLMs as agents to emulate the sequential decision-making processes of humans often represented as Markov decision-making processes (MDPs). The actions within this decision-making framework adhere to specific probability distributions and require iterative sampling. This arouses our curiosity regarding the capacity of LLM agents to comprehend probability distributions, thereby guiding the agent's behavioral decision-making through probabilistic sampling and generating behavioral sequences. To answer the above question, we divide the problem into two main aspects: simulation where the exact probability distribution is known, and generation of sequences where the probability distribution is ambiguous. In the first case, the agent is required to give the type and parameters of the probability distribution through the problem description, and then give the sampling sequence. However, our analysis shows that LLM agents perform poorly in this case, but the sampling success rate can be improved through programming tools. Real-world scenarios often entail unknown probability distributions. Thus, in the second case, we ask the agents to change the activity level in online social networks and analyze the frequency of actions. Ultimately, our analysis shows that LLM agents cannot sample probability distributions even using programming tools. Therefore, careful consideration is still required before directly applying LLM agents as agents to simulate human behavior.
Knowledge Boundary and Persona Dynamic Shape A Better Social Media Agent
Apr 02, 2024Constructing personalized and anthropomorphic agents holds significant importance in the simulation of social networks. However, there are still two key problems in existing works: the agent possesses world knowledge that does not belong to its personas, and it cannot eliminate the interference of diverse persona information on current actions, which reduces the personalization and anthropomorphism of the agent. To solve the above problems, we construct the social media agent based on personalized knowledge and dynamic persona information. For personalized knowledge, we add external knowledge sources and match them with the persona information of agents, thereby giving the agent personalized world knowledge. For dynamic persona information, we use current action information to internally retrieve the persona information of the agent, thereby reducing the interference of diverse persona information on the current action. To make the agent suitable for social media, we design five basic modules for it: persona, planning, action, memory and reflection. To provide an interaction and verification environment for the agent, we build a social media simulation sandbox. In the experimental verification, automatic and human evaluations demonstrated the effectiveness of the agent we constructed.