 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Intent to Evidence: A Categorical Approach for Structural Evaluation of Deep Research Agents
Mar 26, 2026Although deep research agents (DRAs) have emerged as a promising paradigm for complex information synthesis, their evaluation remains constrained by ad hoc empirical benchmarks. These heuristic approaches do not rigorously model agent behavior or adequately stress-test long-horizon synthesis and ambiguity resolution. To bridge this gap, we formalize DRA behavior through the lens of category theory, modeling deep research workflow as a composition of structure-preserving maps (functors). Grounded in this theoretical framework, we introduce a novel mechanism-aware benchmark with 296 questions designed to stress-test agents along four interpretable axes: traversing sequential connectivity chains, verifying intersections within V-structure pullbacks, imposing topological ordering on retrieved substructures, and performing ontological falsification via the Yoneda Probe. Our rigorous evaluation of 11 leading models establishes a persistently low baseline, with the state-of-the-art achieving only a 19.9\% average accuracy, exposing the difficulty of formal structural stress-testing. Furthermore, our findings reveal a stark dichotomy in the current AI capabilities. While advanced deep research pipelines successfully redefine dynamic topological re-ordering and exhibit robust ontological verification -- matching pure reasoning models in falsifying hallucinated premises -- they almost universally collapse on multi-hop structural synthesis. Crucially, massive performance variance across tasks exposes a lingering reliance on brittle heuristics rather than a systemic understanding. Ultimately, this work demonstrates that while top-tier autonomous agents can now organically unify search and reasoning, achieving a generalized mastery over complex structural information remains a formidable open challenge.\footnote{Our implementation will be available at https://github.com/tzq1999/CDR.
The Label Horizon Paradox: Rethinking Supervision Targets in Financial Forecasting
Feb 03, 2026While deep learning has revolutionized financial forecasting through sophisticated architectures, the design of the supervision signal itself is rarely scrutinized. We challenge the canonical assumption that training labels must strictly mirror inference targets, uncovering the Label Horizon Paradox: the optimal supervision signal often deviates from the prediction goal, shifting across intermediate horizons governed by market dynamics. We theoretically ground this phenomenon in a dynamic signal-noise trade-off, demonstrating that generalization hinges on the competition between marginal signal realization and noise accumulation. To operationalize this insight, we propose a bi-level optimization framework that autonomously identifies the optimal proxy label within a single training run. Extensive experiments on large-scale financial datasets demonstrate consistent improvements over conventional baselines, thereby opening new avenues for label-centric research in financial forecasting.
Can ChatGPT Overcome Behavioral Biases in the Financial Sector? Classify-and-Rethink: Multi-Step Zero-Shot Reasoning in the Gold Investment
Nov 19, 2024



Large Language Models (LLMs) have achieved remarkable success recently, displaying exceptional capabilities in creating understandable and organized text. These LLMs have been utilized in diverse fields, such as clinical research, where domain-specific models like Med-Palm have achieved human-level performance. Recently, researchers have employed advanced prompt engineering to enhance the general reasoning ability of LLMs. Despite the remarkable success of zero-shot Chain-of-Thoughts (CoT) in solving general reasoning tasks, the potential of these methods still remains paid limited attention in the financial reasoning task.To address this issue, we explore multiple prompt strategies and incorporated semantic news information to improve LLMs' performance on financial reasoning tasks.To the best of our knowledge, we are the first to explore this important issue by applying ChatGPT to the gold investment.In this work, our aim is to investigate the financial reasoning capabilities of LLMs and their capacity to generate logical and persuasive investment opinions. We will use ChatGPT, one of the most powerful LLMs recently, and prompt engineering to achieve this goal. Our research will focus on understanding the ability of LLMs in sophisticated analysis and reasoning within the context of investment decision-making. Our study finds that ChatGPT with CoT prompt can provide more explainable predictions and overcome behavioral biases, which is crucial in finance-related tasks and can achieve higher investment returns.
Learn Continuously, Act Discretely: Hybrid Action-Space Reinforcement Learning For Optimal Execution
Jul 22, 2022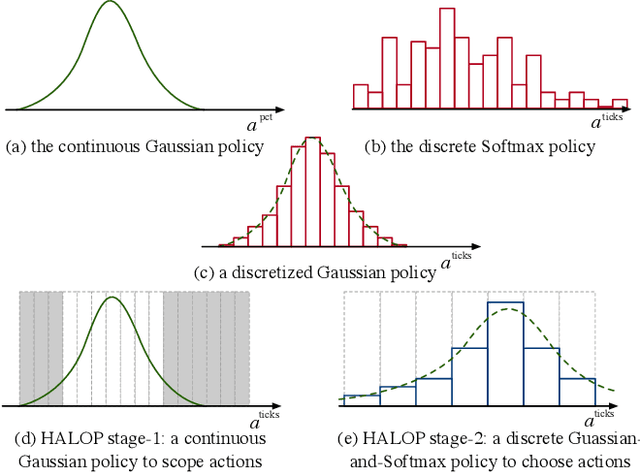
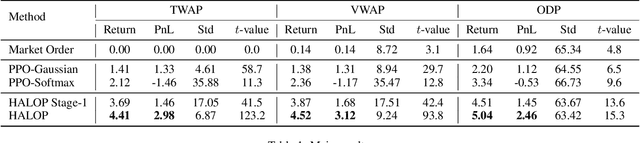
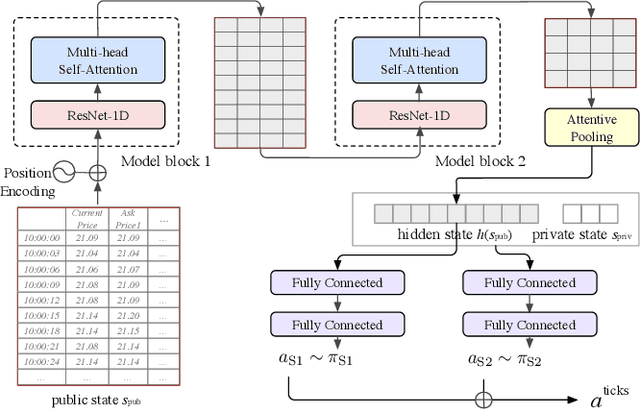

Optimal execution is a sequential decision-making problem for cost-saving in algorithmic trading. Studies have found that reinforcement learning (RL) can help decide the order-splitting sizes. However, a problem remains unsolved: how to place limit orders at appropriate limit prices? The key challenge lies in the "continuous-discrete duality" of the action space. On the one hand, the continuous action space using percentage changes in prices is preferred for generalization. On the other hand, the trader eventually needs to choose limit prices discretely due to the existence of the tick size, which requires specialization for every single stock with different characteristics (e.g., the liquidity and the price range). So we need continuous control for generalization and discrete control for specialization. To this end, we propose a hybrid RL method to combine the advantages of both of them. We first use a continuous control agent to scope an action subset, then deploy a fine-grained agent to choose a specific limit price. Extensive experiments show that our method has higher sample efficiency and better training stability than existing RL algorithms and significantly outperforms previous learning-based methods for order execution.