 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Efficient Reinforcement Learning for Full-length Game of StarCraft II
Sep 23, 2022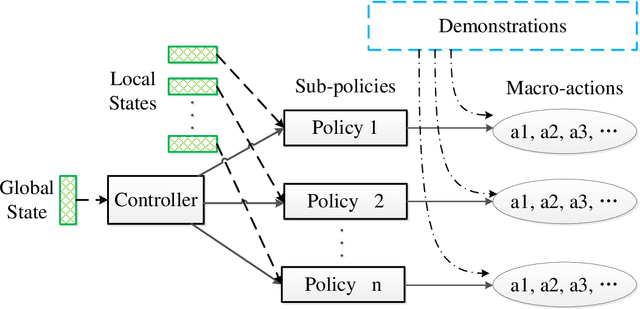

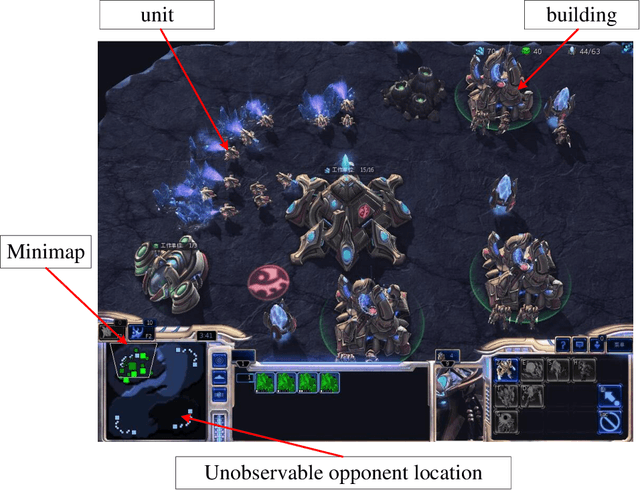

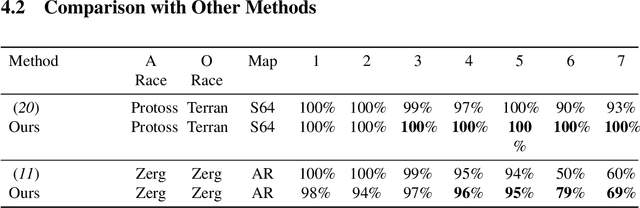
StarCraft II (SC2) poses a grand challenge for reinforcement learning (RL), of which the main difficulties include huge state space, varying action space, and a long time horizon. In this work, we investigate a set of RL techniques for the full-length game of StarCraft II. We investigate a hierarchical RL approach involving extracted macro-actions and a hierarchical architecture of neural networks. We investigate a curriculum transfer training procedure and train the agent on a single machine with 4 GPUs and 48 CPU threads. On a 64x64 map and using restrictive units, we achieve a win rate of 99% against the level-1 built-in AI. Through the curriculum transfer learning algorithm and a mixture of combat models, we achieve a 93% win rate against the most difficult non-cheating level built-in AI (level-7). In this extended version of the paper, we improve our architecture to train the agent against the cheating level AIs and achieve the win rate against the level-8, level-9, and level-10 AIs as 96%, 97%, and 94%, respectively. Our codes are at https://github.com/liuruoze/HierNet-SC2. To provide a baseline referring the AlphaStar for our work as well as the research and open-source community, we reproduce a scaled-down version of it, mini-AlphaStar (mAS). The latest version of mAS is 1.07, which can be trained on the raw action space which has 564 actions. It is designed to run training on a single common machine, by making the hyper-parameters adjustable. We then compare our work with mAS using the same resources and show that our method is more effective. The codes of mini-AlphaStar are at https://github.com/liuruoze/mini-AlphaStar. We hope our study could shed some light on the future research of efficient reinforcement learning on SC2 and other large-scale games.
Validation Set Evaluation can be Wrong: An Evaluator-Generator Approach for Maximizing Online Performance of Ranking in E-commerce
Mar 27, 2020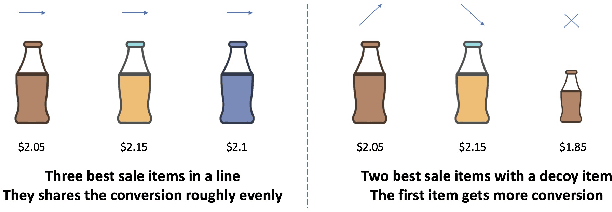
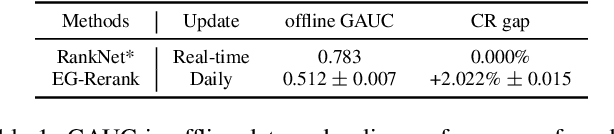
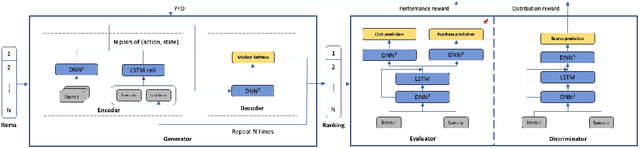
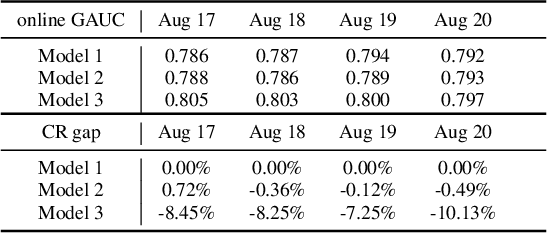
Learning-to-rank (LTR) has become a key technology in E-commerce applications. Previous LTR approaches followed the supervised learning paradigm so that learned models should match the labeled data point-wisely or pair-wisely. However, we have noticed that global context information, including the total order of items in the displayed webpage, can play an important role in interactions with the customers. Therefore, to approach the best global ordering, the exploration in a large combinatorial space of items is necessary, which requires evaluating orders that may not appear in the labeled data. In this scenario, we first show that the classical data-based metrics can be inconsistent with online performance, or even misleading. We then propose to learn an evaluator and search the best model guided by the evaluator, which forms the evaluator-generator framework for training the group-wise LTR model. The evaluator is learned from the labeled data, and is enhanced by incorporating the order context information. The generator is trained with the supervision of the evaluator by reinforcement learning to generate the best order in the combinatorial space. Our experiments in one of the world's largest retail platforms disclose that the learned evaluator is a much better indicator than classical data-based metrics. Moreover, our LTR model achieves a significant improvement ($\textgreater2\%$) from the current industrial-level pair-wise models in terms of both Conversion Rate (CR) and Gross Merchandise Volume (GMV) in online A/B tests.
Efficient Reinforcement Learning with a Mind-Game for Full-Length StarCraft II
Mar 02, 2019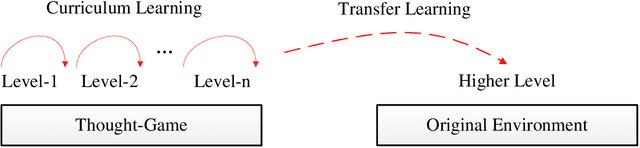
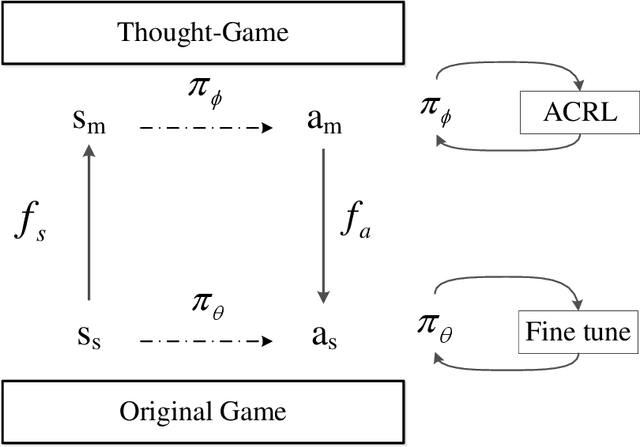

StarCraft II provides an extremely challenging platform for reinforcement learning due to its huge state-space and game length. The previous fastest method requires days to train a full-length game policy in a single commercial machine. In this paper, we introduce the mind-game to facilitate the reinforcement learning, which is an abstract task model. With the mind-game, the policy is firstly trained in the mind-game fastly and is then mapped to the real game for the second phase training. In our experiments, the trained agent can achieve a 100% win-rate on the map Simple64 against the most difficult non-cheating built-in bot (level-7), and the training is 100 times faster than the previous ones under the same computational resource. To test the generalization performance of the agent, a Golden level of StarCraft II Ladder human player has competed with the agent. With restricted strategy, the agent wins the human player by 4 out of 5 games. The mind-game approach might shed some light for further studies of efficient reinforcement learning. The codes are publicly available (https://github.com/mindgameSC2/mind-SC2).
On Reinforcement Learning for Full-length Game of StarCraft
Sep 23, 2018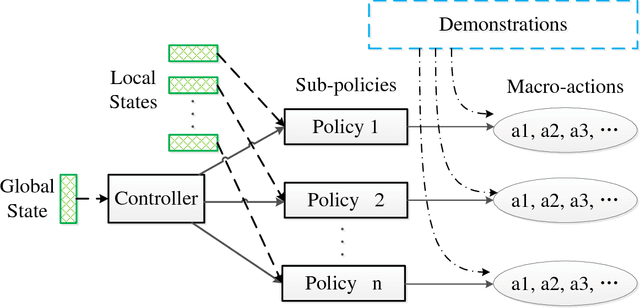


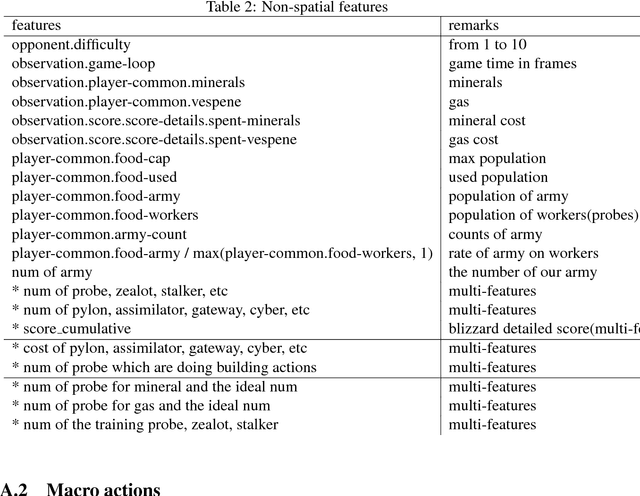
StarCraft II poses a grand challenge for reinforcement learning. The main difficulties of it include huge state and action space and a long-time horizon. In this paper, we investigate a hierarchical reinforcement learning approach for StarCraft II. The hierarchy involves two levels of abstraction. One is the macro-action automatically extracted from expert's trajectories, which reduces the action space in an order of magnitude yet remains effective. The other is a two-layer hierarchical architecture which is modular and easy to scale, enabling a curriculum transferring from simpler tasks to more complex tasks. The reinforcement training algorithm for this architecture is also investigated. On a 64x64 map and using restrictive units, we achieve a winning rate of more than 99\% against the difficulty level-1 built-in AI. Through the curriculum transfer learning algorithm and a mixture of combat model, we can achieve over 93\% winning rate of Protoss against the most difficult non-cheating built-in AI (level-7) of Terran, training within two days using a single machine with only 48 CPU cores and 8 K40 GPUs. It also shows strong generalization performance, when tested against never seen opponents including cheating levels built-in AI and all levels of Zerg and Protoss built-in AI. We hope this study could shed some light on the future research of large-scale reinforcement learning.