 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Knowledge Distillation Based on Feature Variance Against Backdoored Teacher Model
Jun 01, 2024



Benefiting from well-trained deep neural networks (DNNs), model compression have captured special attention for computing resource limited equipment, especially edge devices. Knowledge distillation (KD) is one of the widely used compression techniques for edge deployment, by obtaining a lightweight student model from a well-trained teacher model released on public platforms. However, it has been empirically noticed that the backdoor in the teacher model will be transferred to the student model during the process of KD. Although numerous KD methods have been proposed, most of them focus on the distillation of a high-performing student model without robustness consideration. Besides, some research adopts KD techniques as effective backdoor mitigation tools, but they fail to perform model compression at the same time. Consequently, it is still an open problem to well achieve two objectives of robust KD, i.e., student model's performance and backdoor mitigation. To address these issues, we propose RobustKD, a robust knowledge distillation that compresses the model while mitigating backdoor based on feature variance. Specifically, RobustKD distinguishes the previous works in three key aspects: (1) effectiveness: by distilling the feature map of the teacher model after detoxification, the main task performance of the student model is comparable to that of the teacher model; (2) robustness: by reducing the characteristic variance between the teacher model and the student model, it mitigates the backdoor of the student model under backdoored teacher model scenario; (3) generic: RobustKD still has good performance in the face of multiple data models (e.g., WRN 28-4, Pyramid-200) and diverse DNNs (e.g., ResNet50, MobileNet).
Efficient Reinforcement Learning with a Mind-Game for Full-Length StarCraft II
Mar 02, 2019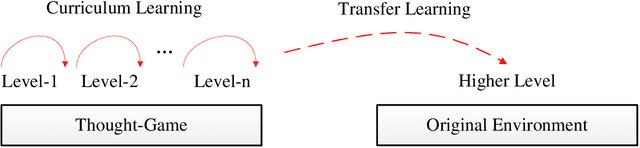
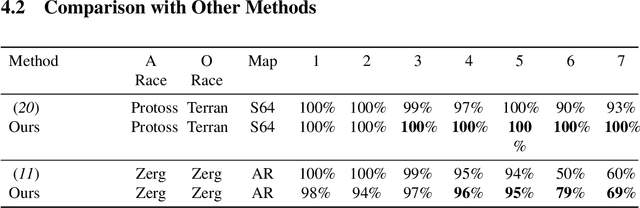
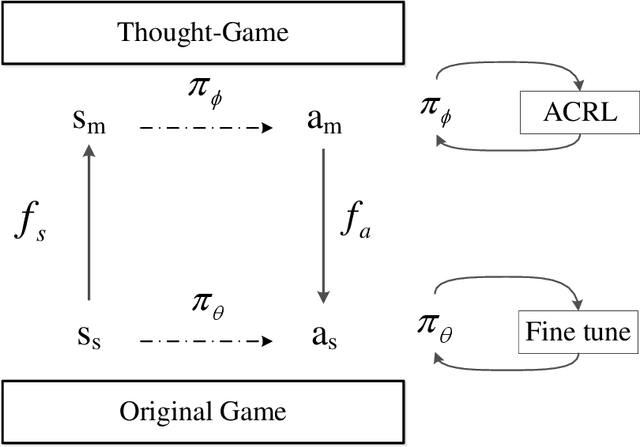

StarCraft II provides an extremely challenging platform for reinforcement learning due to its huge state-space and game length. The previous fastest method requires days to train a full-length game policy in a single commercial machine. In this paper, we introduce the mind-game to facilitate the reinforcement learning, which is an abstract task model. With the mind-game, the policy is firstly trained in the mind-game fastly and is then mapped to the real game for the second phase training. In our experiments, the trained agent can achieve a 100% win-rate on the map Simple64 against the most difficult non-cheating built-in bot (level-7), and the training is 100 times faster than the previous ones under the same computational resource. To test the generalization performance of the agent, a Golden level of StarCraft II Ladder human player has competed with the agent. With restricted strategy, the agent wins the human player by 4 out of 5 games. The mind-game approach might shed some light for further studies of efficient reinforcement learning. The codes are publicly available (https://github.com/mindgameSC2/mind-SC2).