 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Efficient Reinforcement Learning for Full-length Game of StarCraft II
Sep 23, 2022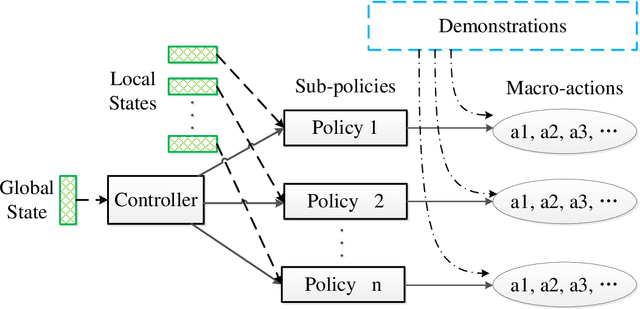


StarCraft II (SC2) poses a grand challenge for reinforcement learning (RL), of which the main difficulties include huge state space, varying action space, and a long time horizon. In this work, we investigate a set of RL techniques for the full-length game of StarCraft II. We investigate a hierarchical RL approach involving extracted macro-actions and a hierarchical architecture of neural networks. We investigate a curriculum transfer training procedure and train the agent on a single machine with 4 GPUs and 48 CPU threads. On a 64x64 map and using restrictive units, we achieve a win rate of 99% against the level-1 built-in AI. Through the curriculum transfer learning algorithm and a mixture of combat models, we achieve a 93% win rate against the most difficult non-cheating level built-in AI (level-7). In this extended version of the paper, we improve our architecture to train the agent against the cheating level AIs and achieve the win rate against the level-8, level-9, and level-10 AIs as 96%, 97%, and 94%, respectively. Our codes are at https://github.com/liuruoze/HierNet-SC2. To provide a baseline referring the AlphaStar for our work as well as the research and open-source community, we reproduce a scaled-down version of it, mini-AlphaStar (mAS). The latest version of mAS is 1.07, which can be trained on the raw action space which has 564 actions. It is designed to run training on a single common machine, by making the hyper-parameters adjustable. We then compare our work with mAS using the same resources and show that our method is more effective. The codes of mini-AlphaStar are at https://github.com/liuruoze/mini-AlphaStar. We hope our study could shed some light on the future research of efficient reinforcement learning on SC2 and other large-scale games.
Rethinking of AlphaStar
Sep 03, 2021


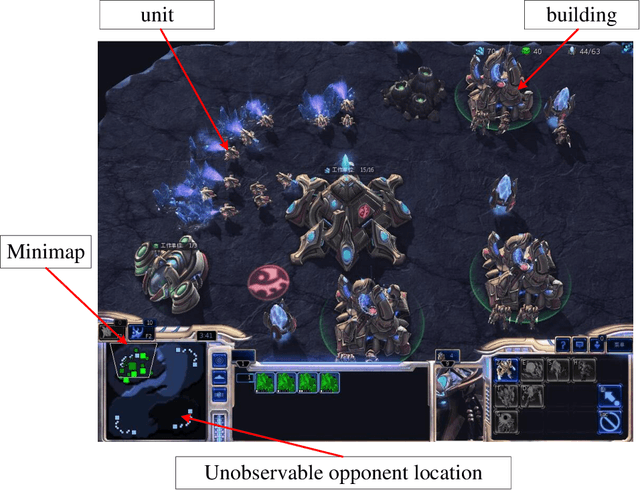
We present a different view for AlphaStar (AS), the program achieving Grand-Master level in the game StarCraft II. It is considered big progress for AI research. However, in this paper, we present problems with the AS, some of which are the defects of it, and some of which are important details that are neglected in its article. These problems arise two questions. One is that what can we get from the built of AS? The other is that does the battle between it with humans fair? After the discussion, we present the future research directions for these problems. Our study is based on a reproduction code of the AS, and the codes are available online.
An Introduction of mini-AlphaStar
Apr 14, 2021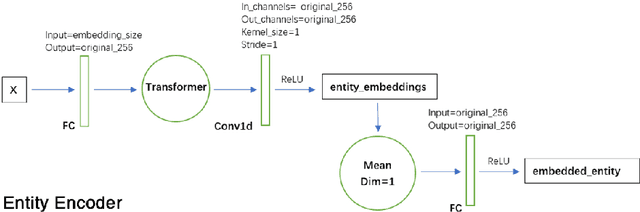
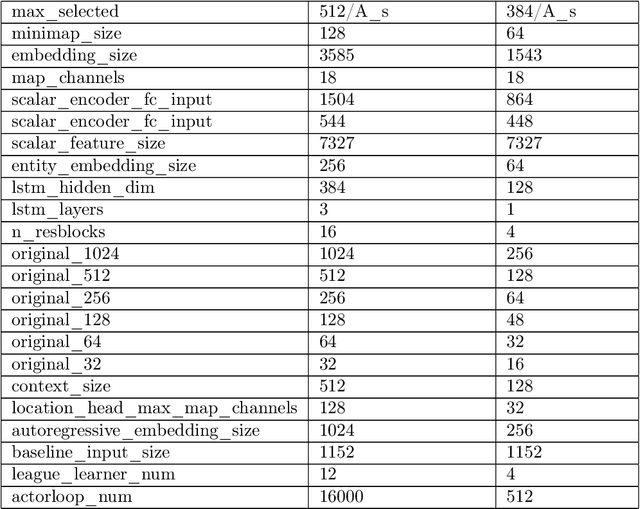
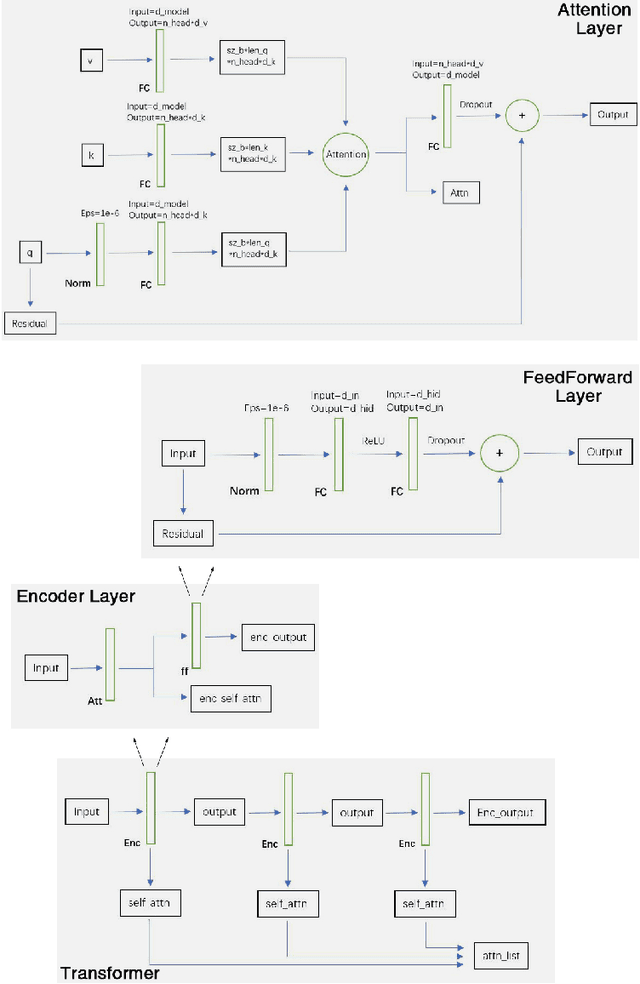
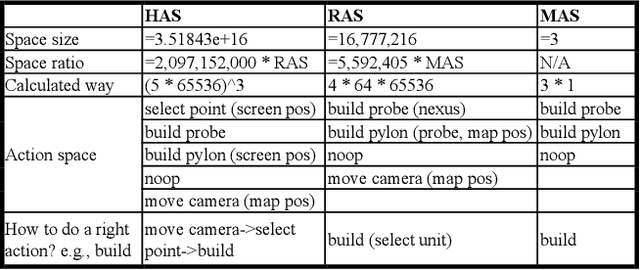
StarCraft II (SC2) is a real-time strategy game, in which players produce and control multiple units to win. Due to its difficulties, such as huge state space, various action space, a long time horizon, and imperfect information, SC2 has been a research highlight in reinforcement learning research. Recently, an SC2 agent called AlphaStar is proposed which shows excellent performance, obtaining a high win-rates of 99.8% against Grandmaster level human players. We implemented a mini-scaled version of it called mini-AlphaStar based on their paper and the pseudocode they provided. The usage and analysis of it are shown in this technical report. The difference between AlphaStar and mini-AlphaStar is that we substituted the hyper-parameters in the former version with much smaller ones for mini-scale training. The codes of mini-AlphaStar are all open-sourced. The objective of mini-AlphaStar is to provide a reproduction of the original AlphaStar and facilitate the future research of RL on large-scale problems.
Novelty-Prepared Few-Shot Classification
Mar 01, 2020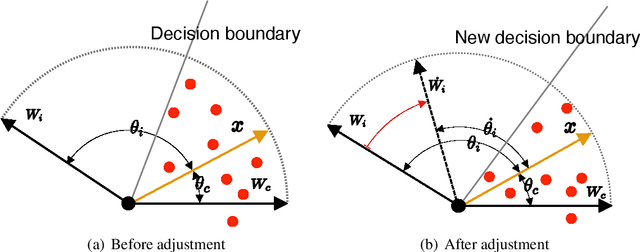
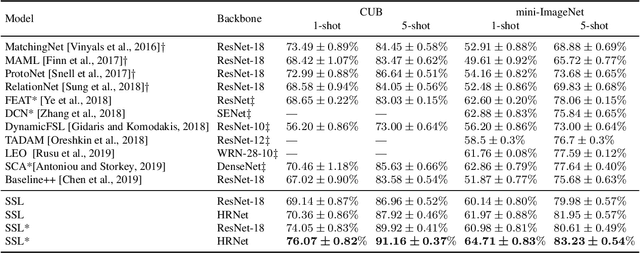
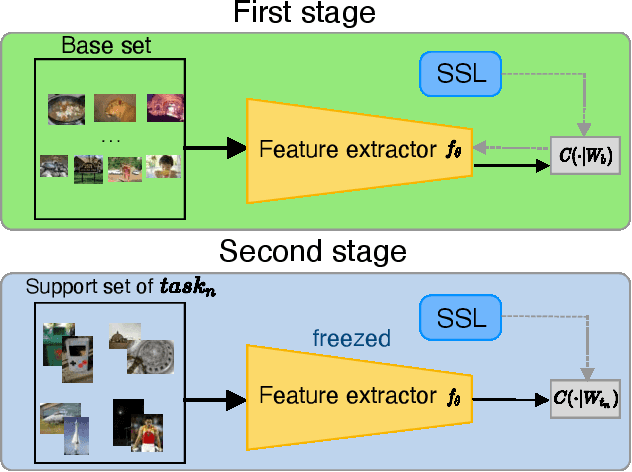
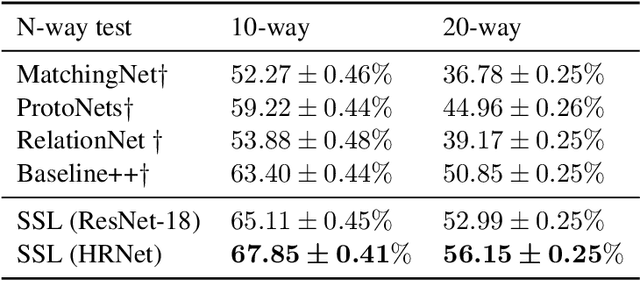
Few-shot classification algorithms can alleviate the data scarceness issue, which is vital in many real-world problems, by adopting models pre-trained from abundant data in other domains. However, the pre-training process was commonly unaware of the future adaptation to other concept classes. We disclose that a classically fully trained feature extractor can leave little embedding space for unseen classes, which keeps the model from well-fitting the new classes. In this work, we propose to use a novelty-prepared loss function, called self-compacting softmax loss (SSL), for few-shot classification. The SSL can prevent the full occupancy of the embedding space. Thus the model is more prepared to learn new classes. In experiments on CUB-200-2011 and mini-ImageNet datasets, we show that SSL leads to significant improvement of the state-of-the-art performance. This work may shed some light on considering the model capacity for few-shot classification tasks.
Efficient Reinforcement Learning with a Mind-Game for Full-Length StarCraft II
Mar 02, 2019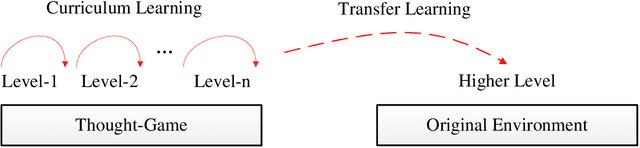
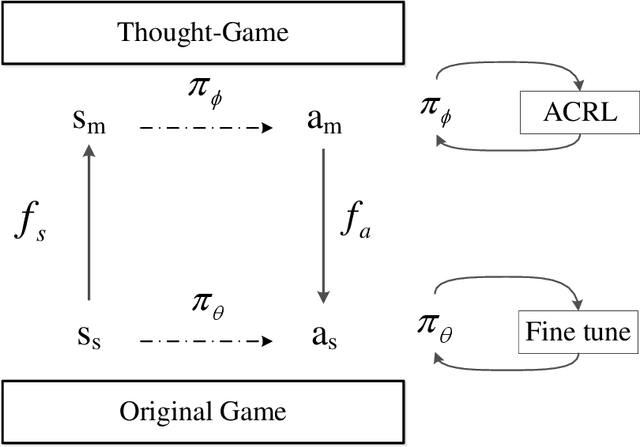

StarCraft II provides an extremely challenging platform for reinforcement learning due to its huge state-space and game length. The previous fastest method requires days to train a full-length game policy in a single commercial machine. In this paper, we introduce the mind-game to facilitate the reinforcement learning, which is an abstract task model. With the mind-game, the policy is firstly trained in the mind-game fastly and is then mapped to the real game for the second phase training. In our experiments, the trained agent can achieve a 100% win-rate on the map Simple64 against the most difficult non-cheating built-in bot (level-7), and the training is 100 times faster than the previous ones under the same computational resource. To test the generalization performance of the agent, a Golden level of StarCraft II Ladder human player has competed with the agent. With restricted strategy, the agent wins the human player by 4 out of 5 games. The mind-game approach might shed some light for further studies of efficient reinforcement learning. The codes are publicly available (https://github.com/mindgameSC2/mind-SC2).
On Reinforcement Learning for Full-length Game of StarCraft
Sep 23, 2018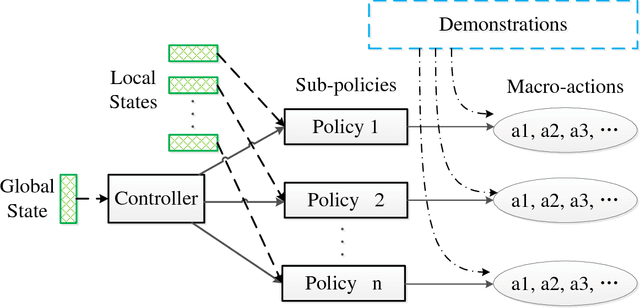


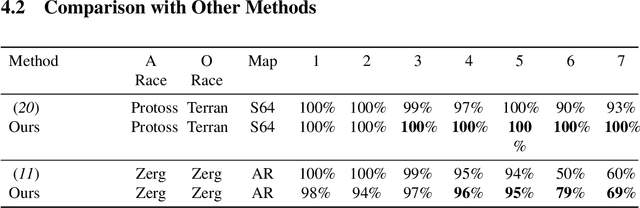
StarCraft II poses a grand challenge for reinforcement learning. The main difficulties of it include huge state and action space and a long-time horizon. In this paper, we investigate a hierarchical reinforcement learning approach for StarCraft II. The hierarchy involves two levels of abstraction. One is the macro-action automatically extracted from expert's trajectories, which reduces the action space in an order of magnitude yet remains effective. The other is a two-layer hierarchical architecture which is modular and easy to scale, enabling a curriculum transferring from simpler tasks to more complex tasks. The reinforcement training algorithm for this architecture is also investigated. On a 64x64 map and using restrictive units, we achieve a winning rate of more than 99\% against the difficulty level-1 built-in AI. Through the curriculum transfer learning algorithm and a mixture of combat model, we can achieve over 93\% winning rate of Protoss against the most difficult non-cheating built-in AI (level-7) of Terran, training within two days using a single machine with only 48 CPU cores and 8 K40 GPUs. It also shows strong generalization performance, when tested against never seen opponents including cheating levels built-in AI and all levels of Zerg and Protoss built-in AI. We hope this study could shed some light on the future research of large-scale reinforcement learning.
Shape Robust Text Detection with Progressive Scale Expansion Network
Jun 07, 2018
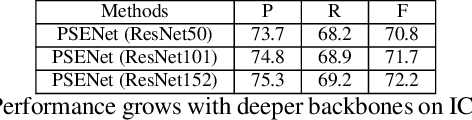

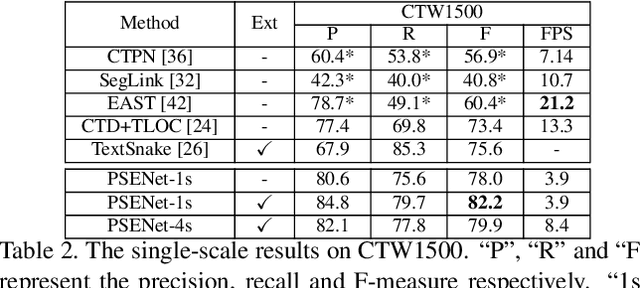
The challenges of shape robust text detection lie in two aspects: 1) most existing quadrangular bounding box based detectors are difficult to locate texts with arbitrary shapes, which are hard to be enclosed perfectly in a rectangle; 2) most pixel-wise segmentation-based detectors may not separate the text instances that are very close to each other. To address these problems, we propose a novel Progressive Scale Expansion Network (PSENet), designed as a segmentation-based detector with multiple predictions for each text instance. These predictions correspond to different `kernels' produced by shrinking the original text instance into various scales. Consequently, the final detection can be conducted through our progressive scale expansion algorithm which gradually expands the kernels with minimal scales to the text instances with maximal and complete shapes. Due to the fact that there are large geometrical margins among these minimal kernels, our method is effective to distinguish the adjacent text instances and is robust to arbitrary shapes. The state-of-the-art results on ICDAR 2015 and ICDAR 2017 MLT benchmarks further confirm the great effectiveness of PSENet. Notably, PSENet outperforms the previous best record by absolute 6.37\% on the curve text dataset SCUT-CTW1500. Code will be available in https://github.com/whai362/PSENet.