 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNovelty-Prepared Few-Shot Classification
Paper and Code
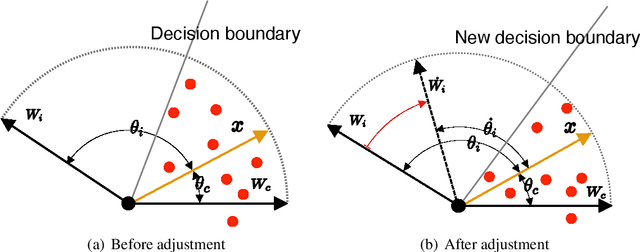
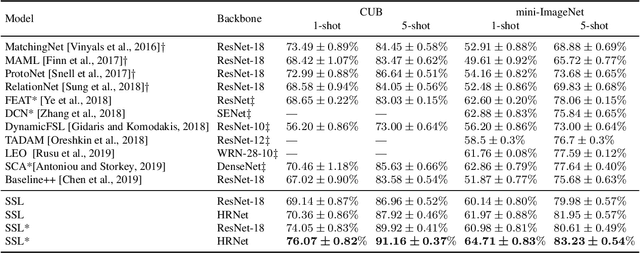
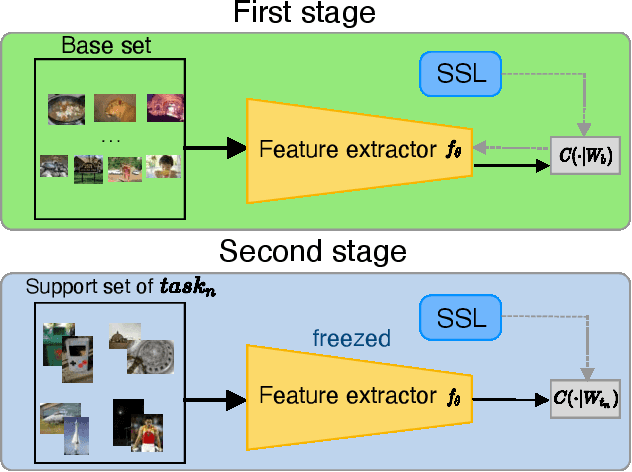
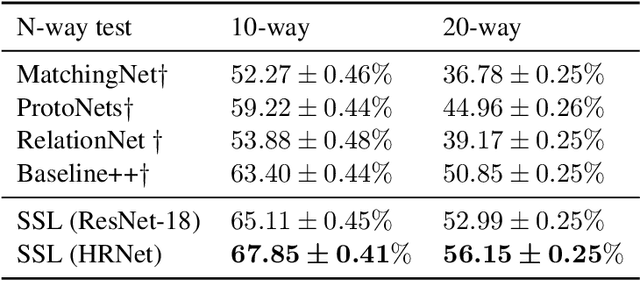
Few-shot classification algorithms can alleviate the data scarceness issue, which is vital in many real-world problems, by adopting models pre-trained from abundant data in other domains. However, the pre-training process was commonly unaware of the future adaptation to other concept classes. We disclose that a classically fully trained feature extractor can leave little embedding space for unseen classes, which keeps the model from well-fitting the new classes. In this work, we propose to use a novelty-prepared loss function, called self-compacting softmax loss (SSL), for few-shot classification. The SSL can prevent the full occupancy of the embedding space. Thus the model is more prepared to learn new classes. In experiments on CUB-200-2011 and mini-ImageNet datasets, we show that SSL leads to significant improvement of the state-of-the-art performance. This work may shed some light on considering the model capacity for few-shot classification tasks.