 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond the Grid: Layout-Informed Multi-Vector Retrieval with Parsed Visual Document Representations
Mar 02, 2026Harnessing the full potential of visually-rich documents requires retrieval systems that understand not just text, but intricate layouts, a core challenge in Visual Document Retrieval (VDR). The prevailing multi-vector architectures, while powerful, face a crucial storage bottleneck that current optimization strategies, such as embedding merging, pruning, or using abstract tokens, fail to resolve without compromising performance or ignoring vital layout cues. To address this, we introduce ColParse, a novel paradigm that leverages a document parsing model to generate a small set of layout-informed sub-image embeddings, which are then fused with a global page-level vector to create a compact and structurally-aware multi-vector representation. Extensive experiments demonstrate that our method reduces storage requirements by over 95% while simultaneously yielding significant performance gains across numerous benchmarks and base models. ColParse thus bridges the critical gap between the fine-grained accuracy of multi-vector retrieval and the practical demands of large-scale deployment, offering a new path towards efficient and interpretable multimodal information systems.
Unlocking Multimodal Document Intelligence: From Current Triumphs to Future Frontiers of Visual Document Retrieval
Feb 23, 2026With the rapid proliferation of multimodal information, Visual Document Retrieval (VDR) has emerged as a critical frontier in bridging the gap between unstructured visually rich data and precise information acquisition. Unlike traditional natural image retrieval, visual documents exhibit unique characteristics defined by dense textual content, intricate layouts, and fine-grained semantic dependencies. This paper presents the first comprehensive survey of the VDR landscape, specifically through the lens of the Multimodal Large Language Model (MLLM) era. We begin by examining the benchmark landscape, and subsequently dive into the methodological evolution, categorizing approaches into three primary aspects: multimodal embedding models, multimodal reranker models, and the integration of Retrieval-Augmented Generation (RAG) and Agentic systems for complex document intelligence. Finally, we identify persistent challenges and outline promising future directions, aiming to provide a clear roadmap for future multimodal document intelligence.
Sculpting the Vector Space: Towards Efficient Multi-Vector Visual Document Retrieval via Prune-then-Merge Framework
Feb 23, 2026Visual Document Retrieval (VDR), which aims to retrieve relevant pages within vast corpora of visually-rich documents, is of significance in current multimodal retrieval applications. The state-of-the-art multi-vector paradigm excels in performance but suffers from prohibitive overhead, a problem that current efficiency methods like pruning and merging address imperfectly, creating a difficult trade-off between compression rate and feature fidelity. To overcome this dilemma, we introduce Prune-then-Merge, a novel two-stage framework that synergizes these complementary approaches. Our method first employs an adaptive pruning stage to filter out low-information patches, creating a refined, high-signal set of embeddings. Subsequently, a hierarchical merging stage compresses this pre-filtered set, effectively summarizing semantic content without the noise-induced feature dilution seen in single-stage methods. Extensive experiments on 29 VDR datasets demonstrate that our framework consistently outperforms existing methods, significantly extending the near-lossless compression range and providing robust performance at high compression ratios.
CausalEmbed: Auto-Regressive Multi-Vector Generation in Latent Space for Visual Document Embedding
Jan 29, 2026Although Multimodal Large Language Models (MLLMs) have shown remarkable potential in Visual Document Retrieval (VDR) through generating high-quality multi-vector embeddings, the substantial storage overhead caused by representing a page with thousands of visual tokens limits their practicality in real-world applications. To address this challenge, we propose an auto-regressive generation approach, CausalEmbed, for constructing multi-vector embeddings. By incorporating iterative margin loss during contrastive training, CausalEmbed encourages the embedding models to learn compact and well-structured representations. Our method enables efficient VDR tasks using only dozens of visual tokens, achieving a 30-155x reduction in token count while maintaining highly competitive performance across various backbones and benchmarks. Theoretical analysis and empirical results demonstrate the unique advantages of auto-regressive embedding generation in terms of training efficiency and scalability at test time. As a result, CausalEmbed introduces a flexible test-time scaling strategy for multi-vector VDR representations and sheds light on the generative paradigm within multimodal document retrieval.
Maximizing Cumulative User Engagement in Sequential Recommendation: An Online Optimization Perspective
Jun 02, 2020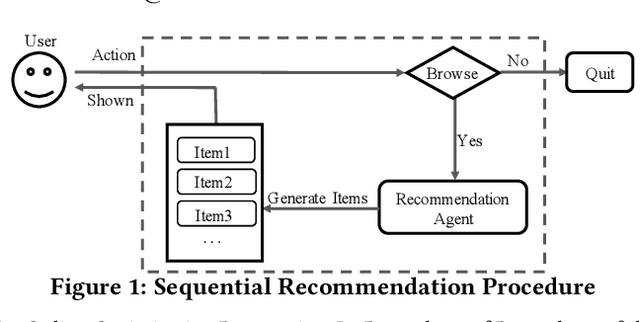

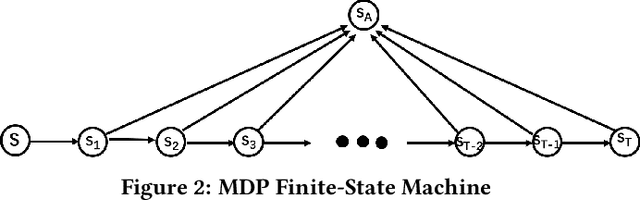

To maximize cumulative user engagement (e.g. cumulative clicks) in sequential recommendation, it is often needed to tradeoff two potentially conflicting objectives, that is, pursuing higher immediate user engagement (e.g., click-through rate) and encouraging user browsing (i.e., more items exposured). Existing works often study these two tasks separately, thus tend to result in sub-optimal results. In this paper, we study this problem from an online optimization perspective, and propose a flexible and practical framework to explicitly tradeoff longer user browsing length and high immediate user engagement. Specifically, by considering items as actions, user's requests as states and user leaving as an absorbing state, we formulate each user's behavior as a personalized Markov decision process (MDP), and the problem of maximizing cumulative user engagement is reduced to a stochastic shortest path (SSP) problem. Meanwhile, with immediate user engagement and quit probability estimation, it is shown that the SSP problem can be efficiently solved via dynamic programming. Experiments on real-world datasets demonstrate the effectiveness of the proposed approach. Moreover, this approach is deployed at a large E-commerce platform, achieved over 7% improvement of cumulative clicks.
Multinomial Logit Bandit with Linear Utility Functions
May 08, 2018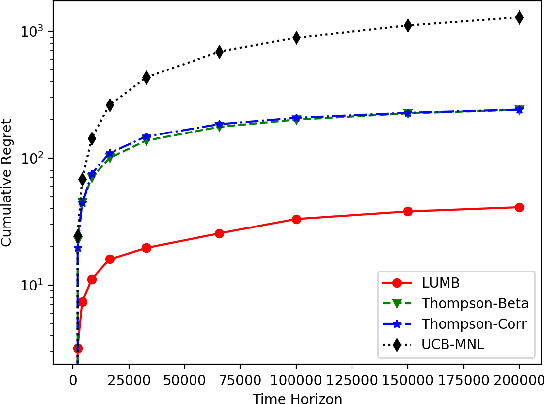
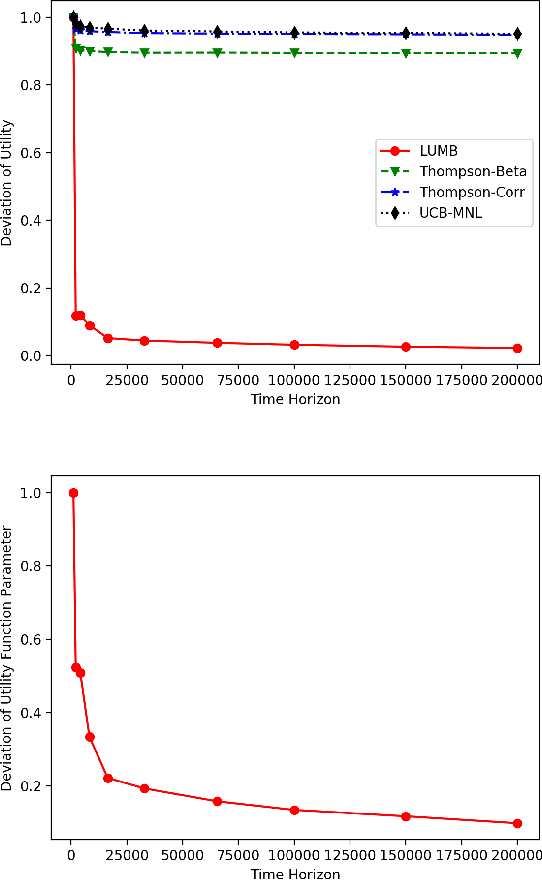
Multinomial logit bandit is a sequential subset selection problem which arises in many applications. In each round, the player selects a $K$-cardinality subset from $N$ candidate items, and receives a reward which is governed by a {\it multinomial logit} (MNL) choice model considering both item utility and substitution property among items. The player's objective is to dynamically learn the parameters of MNL model and maximize cumulative reward over a finite horizon $T$. This problem faces the exploration-exploitation dilemma, and the involved combinatorial nature makes it non-trivial. In recent years, there have developed some algorithms by exploiting specific characteristics of the MNL model, but all of them estimate the parameters of MNL model separately and incur a regret no better than $\tilde{O}\big(\sqrt{NT}\big)$ which is not preferred for large candidate set size $N$. In this paper, we consider the {\it linear utility} MNL choice model whose item utilities are represented as linear functions of $d$-dimension item features, and propose an algorithm, titled {\bf LUMB}, to exploit the underlying structure. It is proven that the proposed algorithm achieves $\tilde{O}\big(dK\sqrt{T}\big)$ regret which is free of candidate set size. Experiments show the superiority of the proposed algorithm.