 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Distillation Approach for SOS Fusion Staging: Towards Fully Automated Skeletal Maturity Assessment
May 27, 2025



We introduce a novel deep learning framework for the automated staging of spheno-occipital synchondrosis (SOS) fusion, a critical diagnostic marker in both orthodontics and forensic anthropology. Our approach leverages a dual-model architecture wherein a teacher model, trained on manually cropped images, transfers its precise spatial understanding to a student model that operates on full, uncropped images. This knowledge distillation is facilitated by a newly formulated loss function that aligns spatial logits as well as incorporates gradient-based attention spatial mapping, ensuring that the student model internalizes the anatomically relevant features without relying on external cropping or YOLO-based segmentation. By leveraging expert-curated data and feedback at each step, our framework attains robust diagnostic accuracy, culminating in a clinically viable end-to-end pipeline. This streamlined approach obviates the need for additional pre-processing tools and accelerates deployment, thereby enhancing both the efficiency and consistency of skeletal maturation assessment in diverse clinical settings.
Modeling Beyond MOS: Quality Assessment Models Must Integrate Context, Reasoning, and Multimodality
May 26, 2025This position paper argues that Mean Opinion Score (MOS), while historically foundational, is no longer sufficient as the sole supervisory signal for multimedia quality assessment models. MOS reduces rich, context-sensitive human judgments to a single scalar, obscuring semantic failures, user intent, and the rationale behind quality decisions. We contend that modern quality assessment models must integrate three interdependent capabilities: (1) context-awareness, to adapt evaluations to task-specific goals and viewing conditions; (2) reasoning, to produce interpretable, evidence-grounded justifications for quality judgments; and (3) multimodality, to align perceptual and semantic cues using vision-language models. We critique the limitations of current MOS-centric benchmarks and propose a roadmap for reform: richer datasets with contextual metadata and expert rationales, and new evaluation metrics that assess semantic alignment, reasoning fidelity, and contextual sensitivity. By reframing quality assessment as a contextual, explainable, and multimodal modeling task, we aim to catalyze a shift toward more robust, human-aligned, and trustworthy evaluation systems.
Gradient Attention Map Based Verification of Deep Convolutional Neural Networks with Application to X-ray Image Datasets
Apr 29, 2025

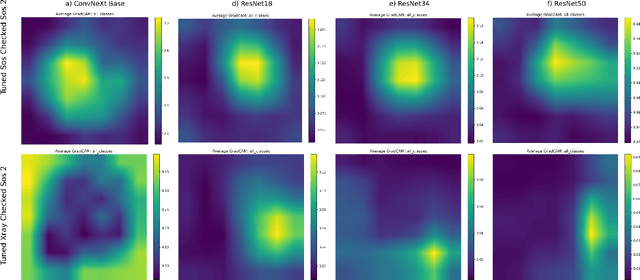

Deep learning models have great potential in medical imaging, including orthodontics and skeletal maturity assessment. However, applying a model to data different from its training set can lead to unreliable predictions that may impact patient care. To address this, we propose a comprehensive verification framework that evaluates model suitability through multiple complementary strategies. First, we introduce a Gradient Attention Map (GAM)-based approach that analyzes attention patterns using Grad-CAM and compares them via similarity metrics such as IoU, Dice Similarity, SSIM, Cosine Similarity, Pearson Correlation, KL Divergence, and Wasserstein Distance. Second, we extend verification to early convolutional feature maps, capturing structural mis-alignments missed by attention alone. Finally, we incorporate an additional garbage class into the classification model to explicitly reject out-of-distribution inputs. Experimental results demonstrate that these combined methods effectively identify unsuitable models and inputs, promoting safer and more reliable deployment of deep learning in medical imaging.
Shifts in Doctors' Eye Movements Between Real and AI-Generated Medical Images
Apr 21, 2025Eye-tracking analysis plays a vital role in medical imaging, providing key insights into how radiologists visually interpret and diagnose clinical cases. In this work, we first analyze radiologists' attention and agreement by measuring the distribution of various eye-movement patterns, including saccades direction, amplitude, and their joint distribution. These metrics help uncover patterns in attention allocation and diagnostic strategies. Furthermore, we investigate whether and how doctors' gaze behavior shifts when viewing authentic (Real) versus deep-learning-generated (Fake) images. To achieve this, we examine fixation bias maps, focusing on first, last, short, and longest fixations independently, along with detailed saccades patterns, to quantify differences in gaze distribution and visual saliency between authentic and synthetic images.
Eyes Tell the Truth: GazeVal Highlights Shortcomings of Generative AI in Medical Imaging
Mar 26, 2025



The demand for high-quality synthetic data for model training and augmentation has never been greater in medical imaging. However, current evaluations predominantly rely on computational metrics that fail to align with human expert recognition. This leads to synthetic images that may appear realistic numerically but lack clinical authenticity, posing significant challenges in ensuring the reliability and effectiveness of AI-driven medical tools. To address this gap, we introduce GazeVal, a practical framework that synergizes expert eye-tracking data with direct radiological evaluations to assess the quality of synthetic medical images. GazeVal leverages gaze patterns of radiologists as they provide a deeper understanding of how experts perceive and interact with synthetic data in different tasks (i.e., diagnostic or Turing tests). Experiments with sixteen radiologists revealed that 96.6% of the generated images (by the most recent state-of-the-art AI algorithm) were identified as fake, demonstrating the limitations of generative AI in producing clinically accurate images.
Shifting Focus: From Global Semantics to Local Prominent Features in Swin-Transformer for Knee Osteoarthritis Severity Assessment
Mar 15, 2024



Conventional imaging diagnostics frequently encounter bottlenecks due to manual inspection, which can lead to delays and inconsistencies. Although deep learning offers a pathway to automation and enhanced accuracy, foundational models in computer vision often emphasize global context at the expense of local details, which are vital for medical imaging diagnostics. To address this, we harness the Swin Transformer's capacity to discern extended spatial dependencies within images through the hierarchical framework. Our novel contribution lies in refining local feature representations, orienting them specifically toward the final distribution of the classifier. This method ensures that local features are not only preserved but are also enriched with task-specific information, enhancing their relevance and detail at every hierarchical level. By implementing this strategy, our model demonstrates significant robustness and precision, as evidenced by extensive validation of two established benchmarks for Knee OsteoArthritis (KOA) grade classification. These results highlight our approach's effectiveness and its promising implications for the future of medical imaging diagnostics. Our implementation is available on https://github.com/mtliba/KOA_NLCS2024
Quantization Effects on Neural Networks Perception: How would quantization change the perceptual field of vision models?
Mar 15, 2024Neural network quantization is an essential technique for deploying models on resource-constrained devices. However, its impact on model perceptual fields, particularly regarding class activation maps (CAMs), remains a significant area of investigation. In this study, we explore how quantization alters the spatial recognition ability of the perceptual field of vision models, shedding light on the alignment between CAMs and visual saliency maps across various architectures. Leveraging a dataset of 10,000 images from ImageNet, we rigorously evaluate six diverse foundational CNNs: VGG16, ResNet50, EfficientNet, MobileNet, SqueezeNet, and DenseNet. We uncover nuanced changes in CAMs and their alignment with human visual saliency maps through systematic quantization techniques applied to these models. Our findings reveal the varying sensitivities of different architectures to quantization and underscore its implications for real-world applications in terms of model performance and interpretability. The primary contribution of this work revolves around deepening our understanding of neural network quantization, providing insights crucial for deploying efficient and interpretable models in practical settings.
Insights into Classifying and Mitigating LLMs' Hallucinations
Nov 14, 2023The widespread adoption of large language models (LLMs) across diverse AI applications is proof of the outstanding achievements obtained in several tasks, such as text mining, text generation, and question answering. However, LLMs are not exempt from drawbacks. One of the most concerning aspects regards the emerging problematic phenomena known as "Hallucinations". They manifest in text generation systems, particularly in question-answering systems reliant on LLMs, potentially resulting in false or misleading information propagation. This paper delves into the underlying causes of AI hallucination and elucidates its significance in artificial intelligence. In particular, Hallucination classification is tackled over several tasks (Machine Translation, Question and Answer, Dialog Systems, Summarisation Systems, Knowledge Graph with LLMs, and Visual Question Answer). Additionally, we explore potential strategies to mitigate hallucinations, aiming to enhance the overall reliability of LLMs. Our research addresses this critical issue within the HeReFaNMi (Health-Related Fake News Mitigation) project, generously supported by NGI Search, dedicated to combating Health-Related Fake News dissemination on the Internet. This endeavour represents a concerted effort to safeguard the integrity of information dissemination in an age of evolving AI technologies.
Automatic diagnosis of knee osteoarthritis severity using Swin transformer
Jul 10, 2023Knee osteoarthritis (KOA) is a widespread condition that can cause chronic pain and stiffness in the knee joint. Early detection and diagnosis are crucial for successful clinical intervention and management to prevent severe complications, such as loss of mobility. In this paper, we propose an automated approach that employs the Swin Transformer to predict the severity of KOA. Our model uses publicly available radiographic datasets with Kellgren and Lawrence scores to enable early detection and severity assessment. To improve the accuracy of our model, we employ a multi-prediction head architecture that utilizes multi-layer perceptron classifiers. Additionally, we introduce a novel training approach that reduces the data drift between multiple datasets to ensure the generalization ability of the model. The results of our experiments demonstrate the effectiveness and feasibility of our approach in predicting KOA severity accurately.
Quality evaluation of point clouds: a novel no-reference approach using transformer-based architecture
Mar 15, 2023


With the increased interest in immersive experiences, point cloud came to birth and was widely adopted as the first choice to represent 3D media. Besides several distortions that could affect the 3D content spanning from acquisition to rendering, efficient transmission of such volumetric content over traditional communication systems stands at the expense of the delivered perceptual quality. To estimate the magnitude of such degradation, employing quality metrics became an inevitable solution. In this work, we propose a novel deep-based no-reference quality metric that operates directly on the whole point cloud without requiring extensive pre-processing, enabling real-time evaluation over both transmission and rendering levels. To do so, we use a novel model design consisting primarily of cross and self-attention layers, in order to learn the best set of local semantic affinities while keeping the best combination of geometry and color information in multiple levels from basic features extraction to deep representation modeling.