 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Beyond MOS: Quality Assessment Models Must Integrate Context, Reasoning, and Multimodality
May 26, 2025This position paper argues that Mean Opinion Score (MOS), while historically foundational, is no longer sufficient as the sole supervisory signal for multimedia quality assessment models. MOS reduces rich, context-sensitive human judgments to a single scalar, obscuring semantic failures, user intent, and the rationale behind quality decisions. We contend that modern quality assessment models must integrate three interdependent capabilities: (1) context-awareness, to adapt evaluations to task-specific goals and viewing conditions; (2) reasoning, to produce interpretable, evidence-grounded justifications for quality judgments; and (3) multimodality, to align perceptual and semantic cues using vision-language models. We critique the limitations of current MOS-centric benchmarks and propose a roadmap for reform: richer datasets with contextual metadata and expert rationales, and new evaluation metrics that assess semantic alignment, reasoning fidelity, and contextual sensitivity. By reframing quality assessment as a contextual, explainable, and multimodal modeling task, we aim to catalyze a shift toward more robust, human-aligned, and trustworthy evaluation systems.
Memory-Efficient 3D High-Resolution Medical Image Synthesis Using CRF-Guided GANs
Mar 13, 2025Generative Adversarial Networks (GANs) have many potential medical imaging applications. Due to the limited memory of Graphical Processing Units (GPUs), most current 3D GAN models are trained on low-resolution medical images, these models cannot scale to high-resolution or are susceptible to patchy artifacts. In this work, we propose an end-to-end novel GAN architecture that uses Conditional Random field (CRF) to model dependencies so that it can generate consistent 3D medical Images without exploiting memory. To achieve this purpose, the generator is divided into two parts during training, the first part produces an intermediate representation and CRF is applied to this intermediate representation to capture correlations. The second part of the generator produces a random sub-volume of image using a subset of the intermediate representation. This structure has two advantages: first, the correlations are modeled by using the features that the generator is trying to optimize. Second, the generator can generate full high-resolution images during inference. Experiments on Lung CTs and Brain MRIs show that our architecture outperforms state-of-the-art while it has lower memory usage and less complexity.
Comparative clinical evaluation of "memory-efficient" synthetic 3d generative adversarial networks (gan) head-to-head to state of art: results on computed tomography of the chest
Jan 26, 2025Introduction: Generative Adversarial Networks (GANs) are increasingly used to generate synthetic medical images, addressing the critical shortage of annotated data for training Artificial Intelligence (AI) systems. This study introduces a novel memory-efficient GAN architecture, incorporating Conditional Random Fields (CRFs) to generate high-resolution 3D medical images and evaluates its performance against the state-of-the-art hierarchical (HA)-GAN model. Materials and Methods: The CRF-GAN was trained using the open-source lung CT LUNA16 dataset. The architecture was compared to HA-GAN through a quantitative evaluation, using Frechet Inception Distance (FID) and Maximum Mean Discrepancy (MMD) metrics, and a qualitative evaluation, through a two-alternative forced choice (2AFC) test completed by a pool of 12 resident radiologists, in order to assess the realism of the generated images. Results: CRF-GAN outperformed HA-GAN with lower FID (0.047 vs. 0.061) and MMD (0.084 vs. 0.086) scores, indicating better image fidelity. The 2AFC test showed a significant preference for images generated by CRF-Gan over those generated by HA-GAN with a p-value of 1.93e-05. Additionally, CRF-GAN demonstrated 9.34% lower memory usage at 256 resolution and achieved up to 14.6% faster training speeds, offering substantial computational savings. Discussion: CRF-GAN model successfully generates high-resolution 3D medical images with non-inferior quality to conventional models, while being more memory-efficient and faster. Computational power and time saved can be used to improve the spatial resolution and anatomical accuracy of generated images, which is still a critical factor limiting their direct clinical applicability.
Detection of subclinical atherosclerosis by image-based deep learning on chest x-ray
Mar 27, 2024



Aims. To develop a deep-learning based system for recognition of subclinical atherosclerosis on a plain frontal chest x-ray. Methods and Results. A deep-learning algorithm to predict coronary artery calcium (CAC) score (the AI-CAC model) was developed on 460 chest x-ray (80% training cohort, 20% internal validation cohort) of primary prevention patients (58.4% male, median age 63 [51-74] years) with available paired chest x-ray and chest computed tomography (CT) indicated for any clinical reason and performed within 3 months. The CAC score calculated on chest CT was used as ground truth. The model was validated on an temporally-independent cohort of 90 patients from the same institution (external validation). The diagnostic accuracy of the AI-CAC model assessed by the area under the curve (AUC) was the primary outcome. Overall, median AI-CAC score was 35 (0-388) and 28.9% patients had no AI-CAC. AUC of the AI-CAC model to identify a CAC>0 was 0.90 in the internal validation cohort and 0.77 in the external validation cohort. Sensitivity was consistently above 92% in both cohorts. In the overall cohort (n=540), among patients with AI-CAC=0, a single ASCVD event occurred, after 4.3 years. Patients with AI-CAC>0 had significantly higher Kaplan Meier estimates for ASCVD events (13.5% vs. 3.4%, log-rank=0.013). Conclusion. The AI-CAC model seems to accurately detect subclinical atherosclerosis on chest x-ray with elevated sensitivity, and to predict ASCVD events with elevated negative predictive value. Adoption of the AI-CAC model to refine CV risk stratification or as an opportunistic screening tool requires prospective evaluation.
Quantization Effects on Neural Networks Perception: How would quantization change the perceptual field of vision models?
Mar 15, 2024Neural network quantization is an essential technique for deploying models on resource-constrained devices. However, its impact on model perceptual fields, particularly regarding class activation maps (CAMs), remains a significant area of investigation. In this study, we explore how quantization alters the spatial recognition ability of the perceptual field of vision models, shedding light on the alignment between CAMs and visual saliency maps across various architectures. Leveraging a dataset of 10,000 images from ImageNet, we rigorously evaluate six diverse foundational CNNs: VGG16, ResNet50, EfficientNet, MobileNet, SqueezeNet, and DenseNet. We uncover nuanced changes in CAMs and their alignment with human visual saliency maps through systematic quantization techniques applied to these models. Our findings reveal the varying sensitivities of different architectures to quantization and underscore its implications for real-world applications in terms of model performance and interpretability. The primary contribution of this work revolves around deepening our understanding of neural network quantization, providing insights crucial for deploying efficient and interpretable models in practical settings.
Shifting Focus: From Global Semantics to Local Prominent Features in Swin-Transformer for Knee Osteoarthritis Severity Assessment
Mar 15, 2024



Conventional imaging diagnostics frequently encounter bottlenecks due to manual inspection, which can lead to delays and inconsistencies. Although deep learning offers a pathway to automation and enhanced accuracy, foundational models in computer vision often emphasize global context at the expense of local details, which are vital for medical imaging diagnostics. To address this, we harness the Swin Transformer's capacity to discern extended spatial dependencies within images through the hierarchical framework. Our novel contribution lies in refining local feature representations, orienting them specifically toward the final distribution of the classifier. This method ensures that local features are not only preserved but are also enriched with task-specific information, enhancing their relevance and detail at every hierarchical level. By implementing this strategy, our model demonstrates significant robustness and precision, as evidenced by extensive validation of two established benchmarks for Knee OsteoArthritis (KOA) grade classification. These results highlight our approach's effectiveness and its promising implications for the future of medical imaging diagnostics. Our implementation is available on https://github.com/mtliba/KOA_NLCS2024
Insights into Classifying and Mitigating LLMs' Hallucinations
Nov 14, 2023The widespread adoption of large language models (LLMs) across diverse AI applications is proof of the outstanding achievements obtained in several tasks, such as text mining, text generation, and question answering. However, LLMs are not exempt from drawbacks. One of the most concerning aspects regards the emerging problematic phenomena known as "Hallucinations". They manifest in text generation systems, particularly in question-answering systems reliant on LLMs, potentially resulting in false or misleading information propagation. This paper delves into the underlying causes of AI hallucination and elucidates its significance in artificial intelligence. In particular, Hallucination classification is tackled over several tasks (Machine Translation, Question and Answer, Dialog Systems, Summarisation Systems, Knowledge Graph with LLMs, and Visual Question Answer). Additionally, we explore potential strategies to mitigate hallucinations, aiming to enhance the overall reliability of LLMs. Our research addresses this critical issue within the HeReFaNMi (Health-Related Fake News Mitigation) project, generously supported by NGI Search, dedicated to combating Health-Related Fake News dissemination on the Internet. This endeavour represents a concerted effort to safeguard the integrity of information dissemination in an age of evolving AI technologies.
Automatic diagnosis of knee osteoarthritis severity using Swin transformer
Jul 10, 2023Knee osteoarthritis (KOA) is a widespread condition that can cause chronic pain and stiffness in the knee joint. Early detection and diagnosis are crucial for successful clinical intervention and management to prevent severe complications, such as loss of mobility. In this paper, we propose an automated approach that employs the Swin Transformer to predict the severity of KOA. Our model uses publicly available radiographic datasets with Kellgren and Lawrence scores to enable early detection and severity assessment. To improve the accuracy of our model, we employ a multi-prediction head architecture that utilizes multi-layer perceptron classifiers. Additionally, we introduce a novel training approach that reduces the data drift between multiple datasets to ensure the generalization ability of the model. The results of our experiments demonstrate the effectiveness and feasibility of our approach in predicting KOA severity accurately.
An Inter-observer consistent deep adversarial training for visual scanpath prediction
Nov 14, 2022



The visual scanpath is a sequence of points through which the human gaze moves while exploring a scene. It represents the fundamental concepts upon which visual attention research is based. As a result, the ability to predict them has emerged as an important task in recent years. In this paper, we propose an inter-observer consistent adversarial training approach for scanpath prediction through a lightweight deep neural network. The adversarial method employs a discriminative neural network as a dynamic loss that is better suited to model the natural stochastic phenomenon while maintaining consistency between the distributions related to the subjective nature of scanpaths traversed by different observers. Through extensive testing, we show the competitiveness of our approach in regard to state-of-the-art methods.
A domain adaptive deep learning solution for scanpath prediction of paintings
Sep 22, 2022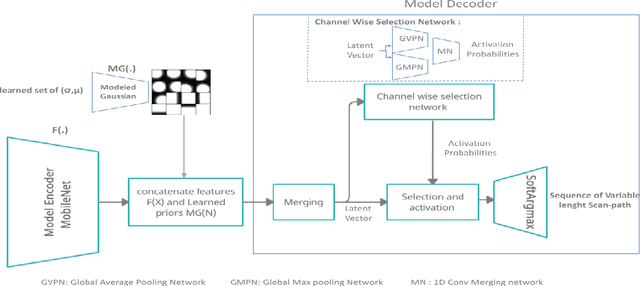
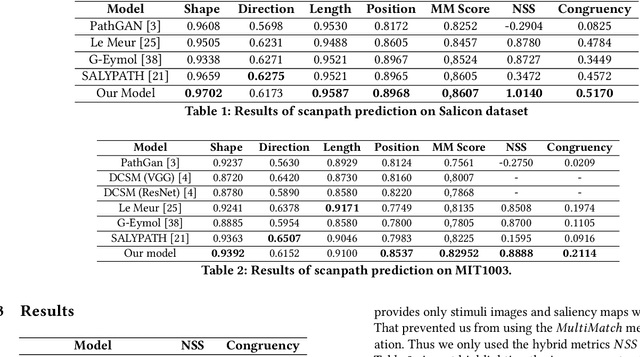


Cultural heritage understanding and preservation is an important issue for society as it represents a fundamental aspect of its identity. Paintings represent a significant part of cultural heritage, and are the subject of study continuously. However, the way viewers perceive paintings is strictly related to the so-called HVS (Human Vision System) behaviour. This paper focuses on the eye-movement analysis of viewers during the visual experience of a certain number of paintings. In further details, we introduce a new approach to predicting human visual attention, which impacts several cognitive functions for humans, including the fundamental understanding of a scene, and then extend it to painting images. The proposed new architecture ingests images and returns scanpaths, a sequence of points featuring a high likelihood of catching viewers' attention. We use an FCNN (Fully Convolutional Neural Network), in which we exploit a differentiable channel-wise selection and Soft-Argmax modules. We also incorporate learnable Gaussian distributions onto the network bottleneck to simulate visual attention process bias in natural scene images. Furthermore, to reduce the effect of shifts between different domains (i.e. natural images, painting), we urge the model to learn unsupervised general features from other domains using a gradient reversal classifier. The results obtained by our model outperform existing state-of-the-art ones in terms of accuracy and efficiency.