 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Data Reusability in Interactive Information Retrieval: Insights from the Community
Dec 20, 2025In this study, we conducted semi-structured interviews with 21 IIR researchers to investigate their data reuse practices. This study aims to expand upon current findings by exploring IIR researchers' information-obtaining behaviors regarding data reuse. We identified the information about shared data characteristics that IIR researchers need when evaluating data reusability, as well as the sources they typically consult to obtain this information. We consider this work to be an initial step toward revealing IIR researchers' data reuse practices and identifying what the community needs to do to promote data reuse. We hope that this study, as well as future research, will inspire more individuals to contribute to ongoing efforts aimed at designing standards, infrastructures, and policies, as well as fostering a sustainable culture of data sharing and reuse in this field.
The Landscape of Data Reuse in Interactive Information Retrieval: Motivations, Sources, and Evaluation of Reusability
Nov 23, 2024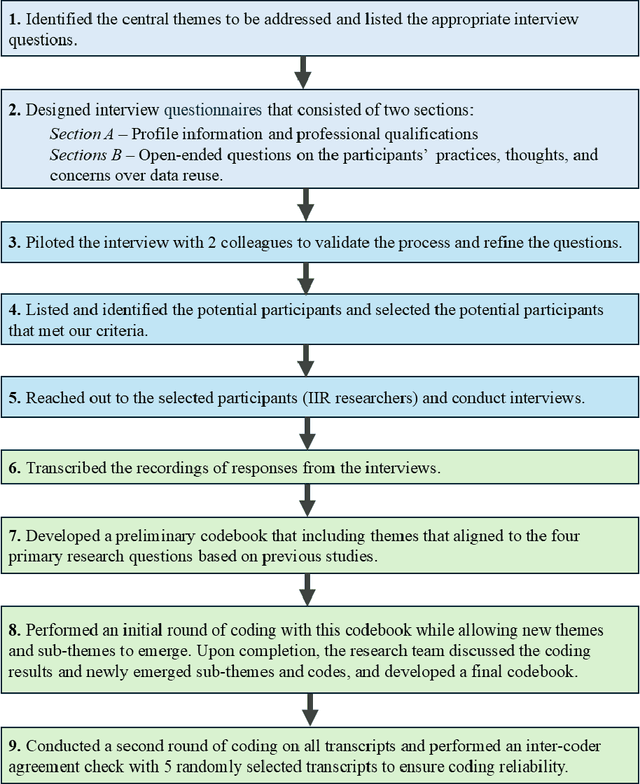


Sharing and reusing research data can effectively reduce redundant efforts in data collection and curation, especially for small labs and research teams conducting human-centered system research, and enhance the replicability of evaluation experiments. Building a sustainable data reuse process and culture relies on frameworks that encompass policies, standards, roles, and responsibilities, all of which must address the diverse needs of data providers, curators, and reusers. To advance the knowledge and accumulate empirical understandings on data reuse, this study investigated the data reuse practices of experienced researchers from the area of Interactive Information Retrieval (IIR) studies, where data reuse has been strongly advocated but still remains a challenge. To enhance the knowledge on data reuse behavior and reusability assessment strategies within IIR community, we conducted 21 semi-structured in-depth interviews with IIR researchers from varying demographic backgrounds, institutions, and stages of careers on their motivations, experiences, and concerns over data reuse. We uncovered the reasons, strategies of reusability assessments, and challenges faced by data reusers within the field of IIR as they attempt to reuse researcher data in their studies. The empirical finding improves our understanding of researchers' motivations for reusing data, their approaches to discovering reusable research data, as well as their concerns and criteria for assessing data reusability, and also enriches the on-going discussions on evaluating user-generated data and research resources and promoting community-level data reuse culture and standards.
DR-WLC: Dimensionality Reduction cognition for object detection and pose estimation by Watching, Learning and Checking
Jan 17, 2023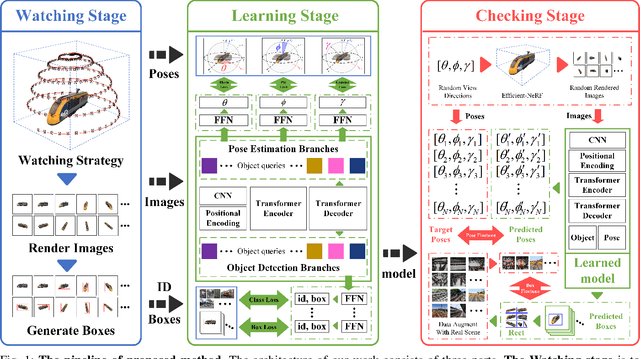

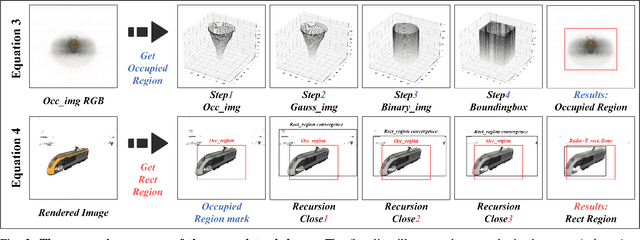

Object detection and pose estimation are difficult tasks in robotics and autonomous driving. Existing object detection and pose estimation methods mostly adopt the same-dimensional data for training. For example, 2D object detection usually requires a large amount of 2D annotation data with high cost. Using high-dimensional information to supervise lower-dimensional tasks is a feasible way to reduce datasets size. In this work, the DR-WLC, a dimensionality reduction cognitive model, which can perform both object detection and pose estimation tasks at the same time is proposed. The model only requires 3D model of objects and unlabeled environment images (with or without objects) to finish the training. In addition, a bounding boxes generation strategy is also proposed to build the relationship between 3D model and 2D object detection task. Experiments show that our method can qualify the work without any manual annotations and it is easy to deploy for practical applications. Source code is at https://github.com/IN2-ViAUn/DR-WLC.