 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniMap: A General Mapping Framework Integrating Optics, Geometry, and Semantics
Sep 09, 2025Robotic systems demand accurate and comprehensive 3D environment perception, requiring simultaneous capture of photo-realistic appearance (optical), precise layout shape (geometric), and open-vocabulary scene understanding (semantic). Existing methods typically achieve only partial fulfillment of these requirements while exhibiting optical blurring, geometric irregularities, and semantic ambiguities. To address these challenges, we propose OmniMap. Overall, OmniMap represents the first online mapping framework that simultaneously captures optical, geometric, and semantic scene attributes while maintaining real-time performance and model compactness. At the architectural level, OmniMap employs a tightly coupled 3DGS-Voxel hybrid representation that combines fine-grained modeling with structural stability. At the implementation level, OmniMap identifies key challenges across different modalities and introduces several innovations: adaptive camera modeling for motion blur and exposure compensation, hybrid incremental representation with normal constraints, and probabilistic fusion for robust instance-level understanding. Extensive experiments show OmniMap's superior performance in rendering fidelity, geometric accuracy, and zero-shot semantic segmentation compared to state-of-the-art methods across diverse scenes. The framework's versatility is further evidenced through a variety of downstream applications, including multi-domain scene Q&A, interactive editing, perception-guided manipulation, and map-assisted navigation.
FMimic: Foundation Models are Fine-grained Action Learners from Human Videos
Jul 28, 2025Visual imitation learning (VIL) provides an efficient and intuitive strategy for robotic systems to acquire novel skills. Recent advancements in foundation models, particularly Vision Language Models (VLMs), have demonstrated remarkable capabilities in visual and linguistic reasoning for VIL tasks. Despite this progress, existing approaches primarily utilize these models for learning high-level plans from human demonstrations, relying on pre-defined motion primitives for executing physical interactions, which remains a major bottleneck for robotic systems. In this work, we present FMimic, a novel paradigm that harnesses foundation models to directly learn generalizable skills at even fine-grained action levels, using only a limited number of human videos. Extensive experiments demonstrate that our FMimic delivers strong performance with a single human video, and significantly outperforms all other methods with five videos. Furthermore, our method exhibits significant improvements of over 39% and 29% in RLBench multi-task experiments and real-world manipulation tasks, respectively, and exceeds baselines by more than 34% in high-precision tasks and 47% in long-horizon tasks.
Automated 3D-GS Registration and Fusion via Skeleton Alignment and Gaussian-Adaptive Features
Jul 28, 2025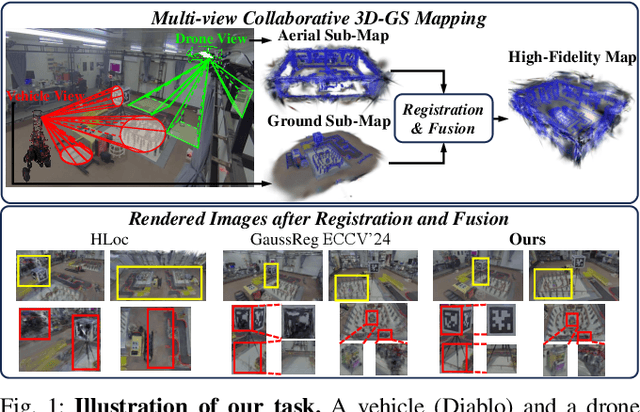
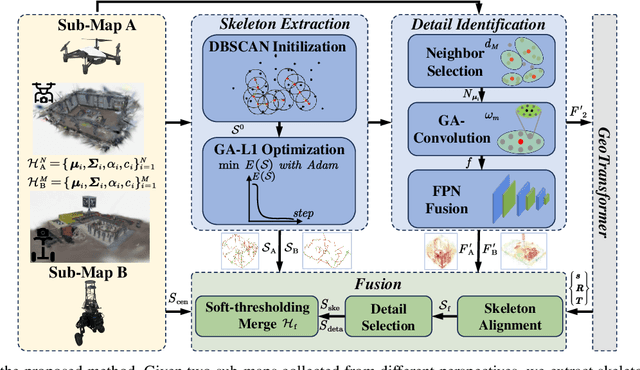
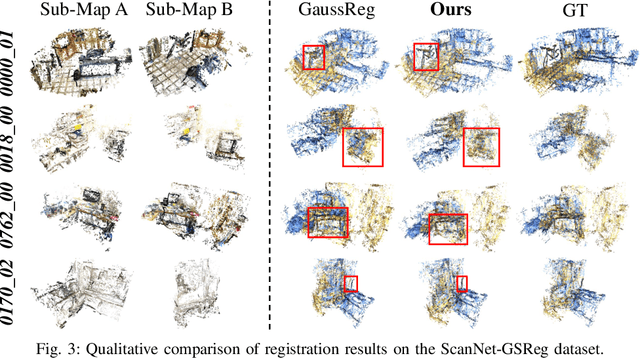
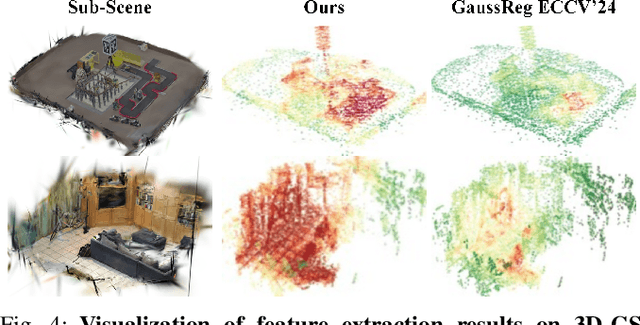
In recent years, 3D Gaussian Splatting (3D-GS)-based scene representation demonstrates significant potential in real-time rendering and training efficiency. However, most existing methods primarily focus on single-map reconstruction, while the registration and fusion of multiple 3D-GS sub-maps remain underexplored. Existing methods typically rely on manual intervention to select a reference sub-map as a template and use point cloud matching for registration. Moreover, hard-threshold filtering of 3D-GS primitives often degrades rendering quality after fusion. In this paper, we present a novel approach for automated 3D-GS sub-map alignment and fusion, eliminating the need for manual intervention while enhancing registration accuracy and fusion quality. First, we extract geometric skeletons across multiple scenes and leverage ellipsoid-aware convolution to capture 3D-GS attributes, facilitating robust scene registration. Second, we introduce a multi-factor Gaussian fusion strategy to mitigate the scene element loss caused by rigid thresholding. Experiments on the ScanNet-GSReg and our Coord datasets demonstrate the effectiveness of the proposed method in registration and fusion. For registration, it achieves a 41.9\% reduction in RRE on complex scenes, ensuring more precise pose estimation. For fusion, it improves PSNR by 10.11 dB, highlighting superior structural preservation. These results confirm its ability to enhance scene alignment and reconstruction fidelity, ensuring more consistent and accurate 3D scene representation for robotic perception and autonomous navigation.
ChatStitch: Visualizing Through Structures via Surround-View Unsupervised Deep Image Stitching with Collaborative LLM-Agents
Mar 19, 2025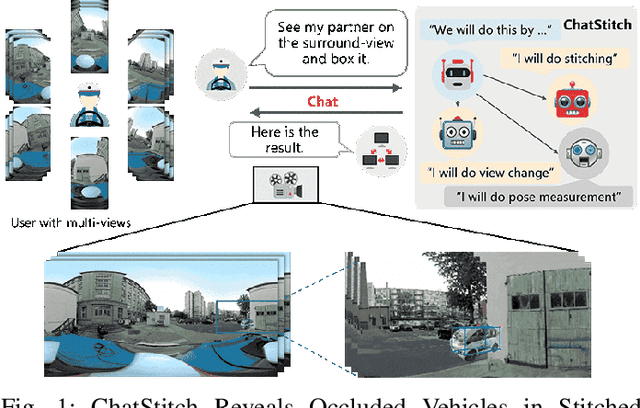


Collaborative perception has garnered significant attention for its ability to enhance the perception capabilities of individual vehicles through the exchange of information with surrounding vehicle-agents. However, existing collaborative perception systems are limited by inefficiencies in user interaction and the challenge of multi-camera photorealistic visualization. To address these challenges, this paper introduces ChatStitch, the first collaborative perception system capable of unveiling obscured blind spot information through natural language commands integrated with external digital assets. To adeptly handle complex or abstract commands, ChatStitch employs a multi-agent collaborative framework based on Large Language Models. For achieving the most intuitive perception for humans, ChatStitch proposes SV-UDIS, the first surround-view unsupervised deep image stitching method under the non-global-overlapping condition. We conducted extensive experiments on the UDIS-D, MCOV-SLAM open datasets, and our real-world dataset. Specifically, our SV-UDIS method achieves state-of-the-art performance on the UDIS-D dataset for 3, 4, and 5 image stitching tasks, with PSNR improvements of 9%, 17%, and 21%, and SSIM improvements of 8%, 18%, and 26%, respectively.
GaussianGraph: 3D Gaussian-based Scene Graph Generation for Open-world Scene Understanding
Mar 06, 2025Recent advancements in 3D Gaussian Splatting(3DGS) have significantly improved semantic scene understanding, enabling natural language queries to localize objects within a scene. However, existing methods primarily focus on embedding compressed CLIP features to 3D Gaussians, suffering from low object segmentation accuracy and lack spatial reasoning capabilities. To address these limitations, we propose GaussianGraph, a novel framework that enhances 3DGS-based scene understanding by integrating adaptive semantic clustering and scene graph generation. We introduce a "Control-Follow" clustering strategy, which dynamically adapts to scene scale and feature distribution, avoiding feature compression and significantly improving segmentation accuracy. Additionally, we enrich scene representation by integrating object attributes and spatial relations extracted from 2D foundation models. To address inaccuracies in spatial relationships, we propose 3D correction modules that filter implausible relations through spatial consistency verification, ensuring reliable scene graph construction. Extensive experiments on three datasets demonstrate that GaussianGraph outperforms state-of-the-art methods in both semantic segmentation and object grounding tasks, providing a robust solution for complex scene understanding and interaction.
OpenGS-SLAM: Open-Set Dense Semantic SLAM with 3D Gaussian Splatting for Object-Level Scene Understanding
Mar 03, 2025



Recent advancements in 3D Gaussian Splatting have significantly improved the efficiency and quality of dense semantic SLAM. However, previous methods are generally constrained by limited-category pre-trained classifiers and implicit semantic representation, which hinder their performance in open-set scenarios and restrict 3D object-level scene understanding. To address these issues, we propose OpenGS-SLAM, an innovative framework that utilizes 3D Gaussian representation to perform dense semantic SLAM in open-set environments. Our system integrates explicit semantic labels derived from 2D foundational models into the 3D Gaussian framework, facilitating robust 3D object-level scene understanding. We introduce Gaussian Voting Splatting to enable fast 2D label map rendering and scene updating. Additionally, we propose a Confidence-based 2D Label Consensus method to ensure consistent labeling across multiple views. Furthermore, we employ a Segmentation Counter Pruning strategy to improve the accuracy of semantic scene representation. Extensive experiments on both synthetic and real-world datasets demonstrate the effectiveness of our method in scene understanding, tracking, and mapping, achieving 10 times faster semantic rendering and 2 times lower storage costs compared to existing methods. Project page: https://young-bit.github.io/opengs-github.github.io/.
Unified Vertex Motion Estimation for Integrated Video Stabilization and Stitching in Tractor-Trailer Wheeled Robots
Dec 10, 2024



Tractor-trailer wheeled robots need to perform comprehensive perception tasks to enhance their operations in areas such as logistics parks and long-haul transportation. The perception of these robots face three major challenges: the relative pose change between the tractor and trailer, the asynchronous vibrations between the tractor and trailer, and the significant camera parallax caused by the large size. In this paper, we propose a novel Unified Vertex Motion Video Stabilization and Stitching framework designed for unknown environments. To establish the relationship between stabilization and stitching, the proposed Unified Vertex Motion framework comprises the Stitching Motion Field, which addresses relative positional change, and the Stabilization Motion Field, which tackles asynchronous vibrations. Then, recognizing the heterogeneity of optimization functions required for stabilization and stitching, a weighted cost function approach is proposed to address the problem of camera parallax. Furthermore, this framework has been successfully implemented in real tractor-trailer wheeled robots. The proposed Unified Vertex Motion Video Stabilization and Stitching method has been thoroughly tested in various challenging scenarios, demonstrating its accuracy and practicality in real-world robot tasks.
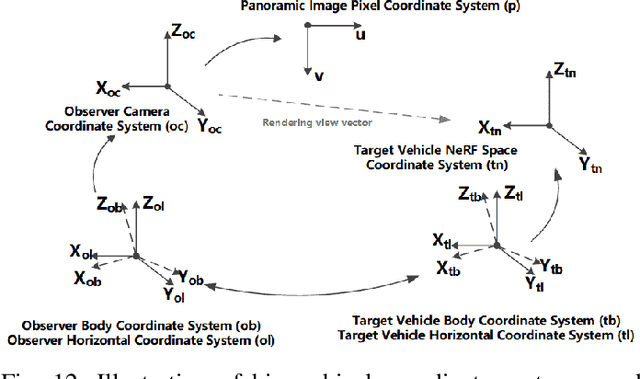
MC-NeRF: Muti-Camera Neural Radiance Fields for Muti-Camera Image Acquisition Systems
Sep 14, 2023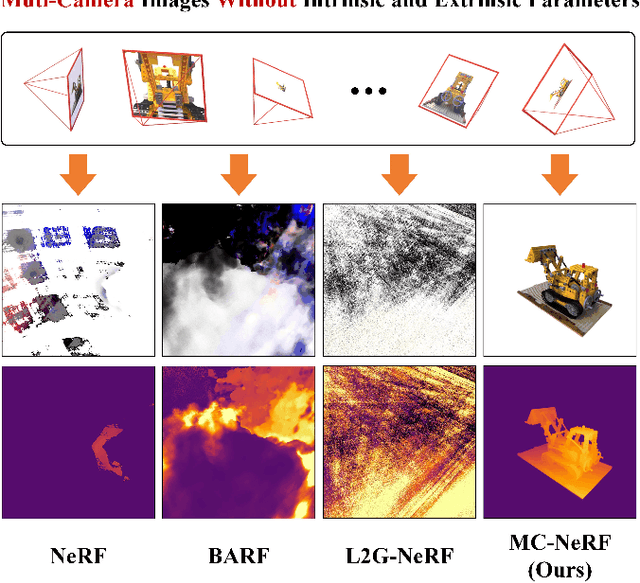

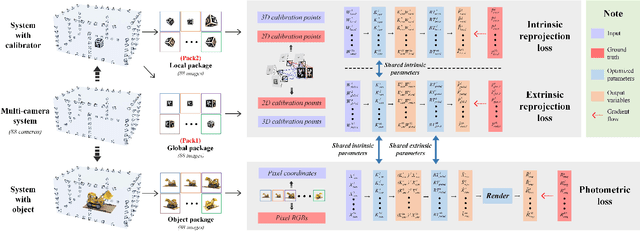

Neural Radiance Fields (NeRF) employ multi-view images for 3D scene representation and have shown remarkable performance. As one of the primary sources of multi-view images, multi-camera systems encounter challenges such as varying intrinsic parameters and frequent pose changes. Most previous NeRF-based methods often assume a global unique camera and seldom consider scenarios with multiple cameras. Besides, some pose-robust methods still remain susceptible to suboptimal solutions when poses are poor initialized. In this paper, we propose MC-NeRF, a method can jointly optimize both intrinsic and extrinsic parameters for bundle-adjusting Neural Radiance Fields. Firstly, we conduct a theoretical analysis to tackle the degenerate case and coupling issue that arise from the joint optimization between intrinsic and extrinsic parameters. Secondly, based on the proposed solutions, we introduce an efficient calibration image acquisition scheme for multi-camera systems, including the design of calibration object. Lastly, we present a global end-to-end network with training sequence that enables the regression of intrinsic and extrinsic parameters, along with the rendering network. Moreover, most existing datasets are designed for unique camera, we create a new dataset that includes four different styles of multi-camera acquisition systems, allowing readers to generate custom datasets. Experiments confirm the effectiveness of our method when each image corresponds to different camera parameters. Specifically, we adopt up to 110 images with 110 different intrinsic and extrinsic parameters, to achieve 3D scene representation without providing initial poses. The Code and supplementary materials are available at https://in2-viaun.github.io/MC-NeRF.
CRRS: Concentric Rectangles Regression Strategy for Multi-point Representation on Fisheye Images
Mar 26, 2023Modern object detectors take advantage of rectangular bounding boxes as a conventional way to represent objects. When it comes to fisheye images, rectangular boxes involve more background noise rather than semantic information. Although multi-point representation has been proposed, both the regression accuracy and convergence still perform inferior to the widely used rectangular boxes. In order to further exploit the advantages of multi-point representation for distorted images, Concentric Rectangles Regression Strategy(CRRS) is proposed in this work. We adopt smoother mean loss to allocate weights and discuss the effect of hyper-parameter to prediction results. Moreover, an accurate pixel-level method is designed to obtain irregular IoU for estimating detector performance. Compared with the previous work for muti-point representation, the experiments show that CRRS can improve the training performance both in accurate and stability. We also prove that multi-task weighting strategy facilitates regression process in this design.
Sector Patch Embedding: An Embedding Module Conforming to The Distortion Pattern of Fisheye Image
Mar 26, 2023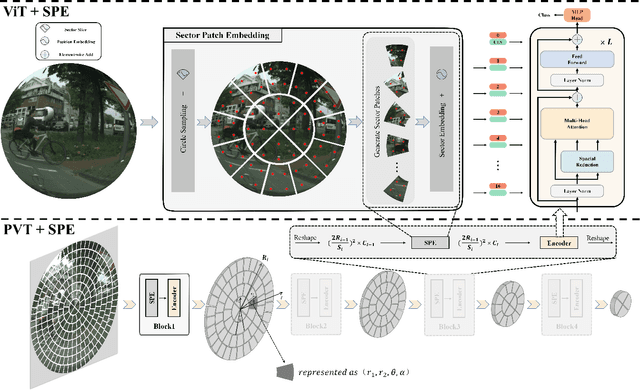
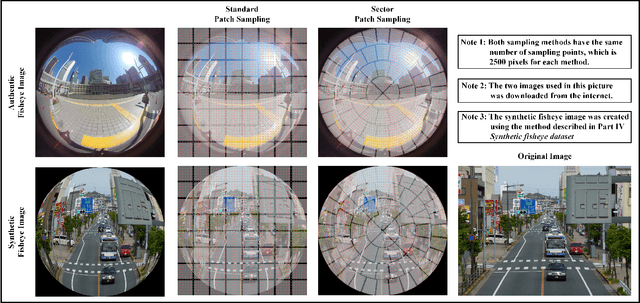
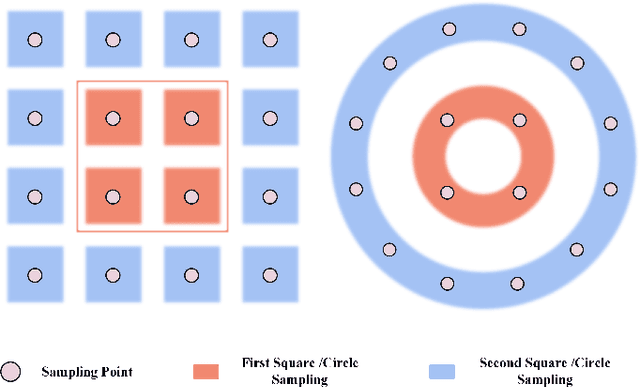
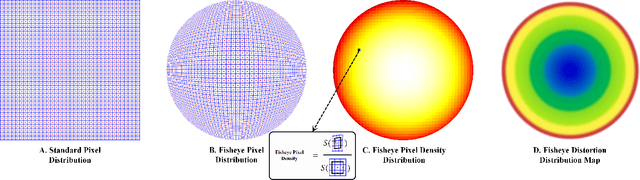
Fisheye cameras suffer from image distortion while having a large field of view(LFOV). And this fact leads to poor performance on some fisheye vision tasks. One of the solutions is to optimize the current vision algorithm for fisheye images. However, most of the CNN-based methods and the Transformer-based methods lack the capability of leveraging distortion information efficiently. In this work, we propose a novel patch embedding method called Sector Patch Embedding(SPE), conforming to the distortion pattern of the fisheye image. Furthermore, we put forward a synthetic fisheye dataset based on the ImageNet-1K and explore the performance of several Transformer models on the dataset. The classification top-1 accuracy of ViT and PVT is improved by 0.75% and 2.8% with SPE respectively. The experiments show that the proposed sector patch embedding method can better perceive distortion and extract features on the fisheye images. Our method can be easily adopted to other Transformer-based models. Source code is at https://github.com/IN2-ViAUn/Sector-Patch-Embedding.