 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetaFood CVPR 2024 Challenge on Physically Informed 3D Food Reconstruction: Methods and Results
Jul 12, 2024
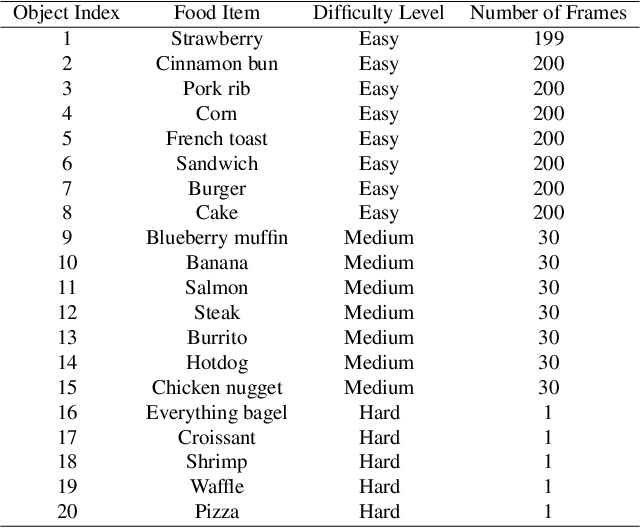
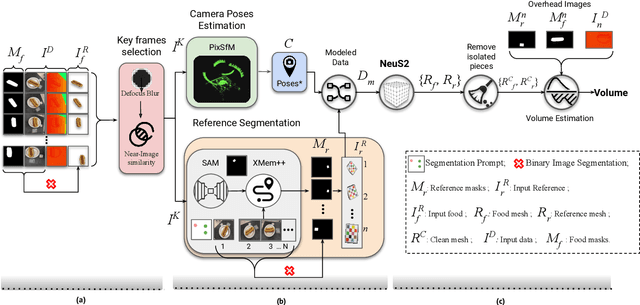
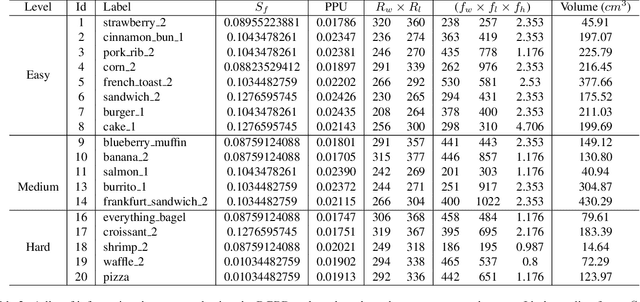
The increasing interest in computer vision applications for nutrition and dietary monitoring has led to the development of advanced 3D reconstruction techniques for food items. However, the scarcity of high-quality data and limited collaboration between industry and academia have constrained progress in this field. Building on recent advancements in 3D reconstruction, we host the MetaFood Workshop and its challenge for Physically Informed 3D Food Reconstruction. This challenge focuses on reconstructing volume-accurate 3D models of food items from 2D images, using a visible checkerboard as a size reference. Participants were tasked with reconstructing 3D models for 20 selected food items of varying difficulty levels: easy, medium, and hard. The easy level provides 200 images, the medium level provides 30 images, and the hard level provides only 1 image for reconstruction. In total, 16 teams submitted results in the final testing phase. The solutions developed in this challenge achieved promising results in 3D food reconstruction, with significant potential for improving portion estimation for dietary assessment and nutritional monitoring. More details about this workshop challenge and access to the dataset can be found at https://sites.google.com/view/cvpr-metafood-2024.
Sector Patch Embedding: An Embedding Module Conforming to The Distortion Pattern of Fisheye Image
Mar 26, 2023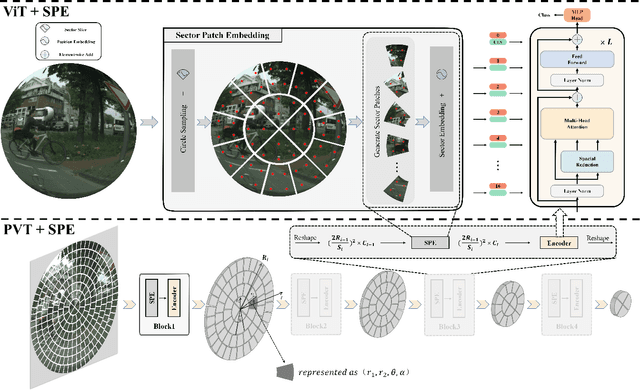
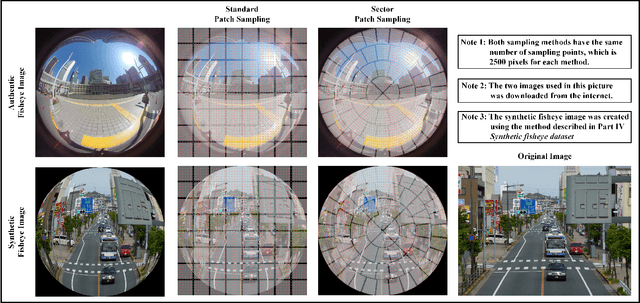
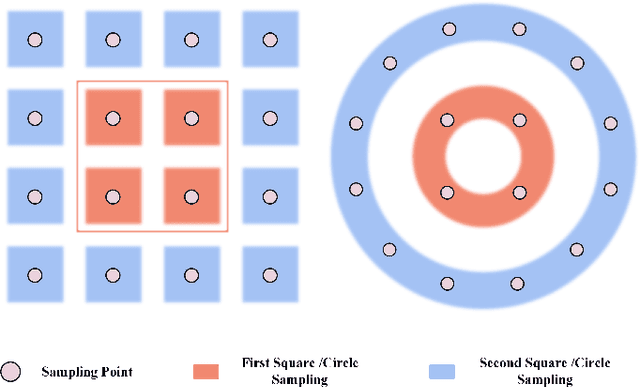
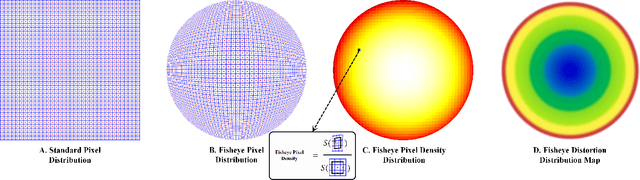
Fisheye cameras suffer from image distortion while having a large field of view(LFOV). And this fact leads to poor performance on some fisheye vision tasks. One of the solutions is to optimize the current vision algorithm for fisheye images. However, most of the CNN-based methods and the Transformer-based methods lack the capability of leveraging distortion information efficiently. In this work, we propose a novel patch embedding method called Sector Patch Embedding(SPE), conforming to the distortion pattern of the fisheye image. Furthermore, we put forward a synthetic fisheye dataset based on the ImageNet-1K and explore the performance of several Transformer models on the dataset. The classification top-1 accuracy of ViT and PVT is improved by 0.75% and 2.8% with SPE respectively. The experiments show that the proposed sector patch embedding method can better perceive distortion and extract features on the fisheye images. Our method can be easily adopted to other Transformer-based models. Source code is at https://github.com/IN2-ViAUn/Sector-Patch-Embedding.