 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated 3D-GS Registration and Fusion via Skeleton Alignment and Gaussian-Adaptive Features
Jul 28, 2025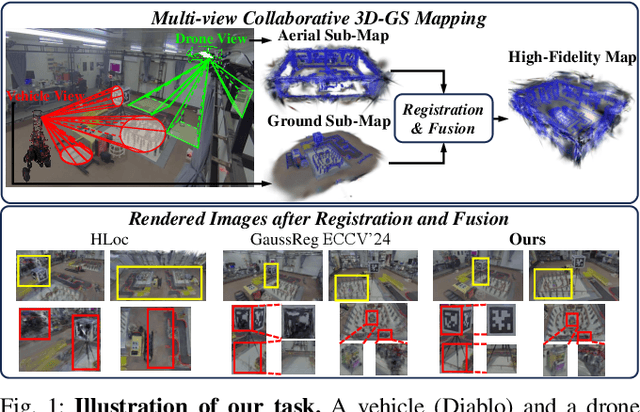
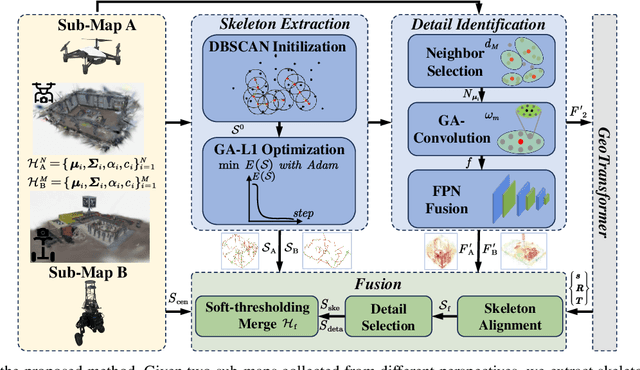
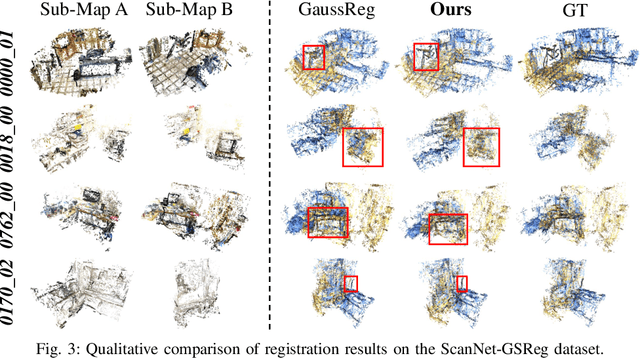
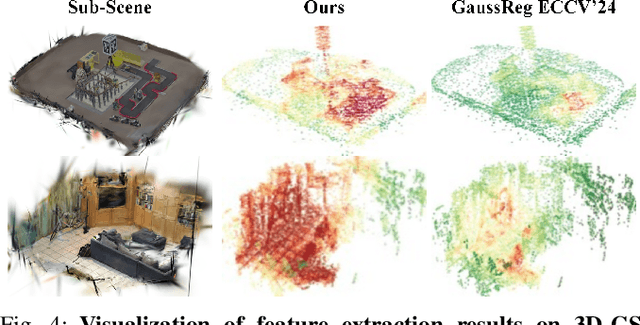
In recent years, 3D Gaussian Splatting (3D-GS)-based scene representation demonstrates significant potential in real-time rendering and training efficiency. However, most existing methods primarily focus on single-map reconstruction, while the registration and fusion of multiple 3D-GS sub-maps remain underexplored. Existing methods typically rely on manual intervention to select a reference sub-map as a template and use point cloud matching for registration. Moreover, hard-threshold filtering of 3D-GS primitives often degrades rendering quality after fusion. In this paper, we present a novel approach for automated 3D-GS sub-map alignment and fusion, eliminating the need for manual intervention while enhancing registration accuracy and fusion quality. First, we extract geometric skeletons across multiple scenes and leverage ellipsoid-aware convolution to capture 3D-GS attributes, facilitating robust scene registration. Second, we introduce a multi-factor Gaussian fusion strategy to mitigate the scene element loss caused by rigid thresholding. Experiments on the ScanNet-GSReg and our Coord datasets demonstrate the effectiveness of the proposed method in registration and fusion. For registration, it achieves a 41.9\% reduction in RRE on complex scenes, ensuring more precise pose estimation. For fusion, it improves PSNR by 10.11 dB, highlighting superior structural preservation. These results confirm its ability to enhance scene alignment and reconstruction fidelity, ensuring more consistent and accurate 3D scene representation for robotic perception and autonomous navigation.
GaussianGraph: 3D Gaussian-based Scene Graph Generation for Open-world Scene Understanding
Mar 06, 2025Recent advancements in 3D Gaussian Splatting(3DGS) have significantly improved semantic scene understanding, enabling natural language queries to localize objects within a scene. However, existing methods primarily focus on embedding compressed CLIP features to 3D Gaussians, suffering from low object segmentation accuracy and lack spatial reasoning capabilities. To address these limitations, we propose GaussianGraph, a novel framework that enhances 3DGS-based scene understanding by integrating adaptive semantic clustering and scene graph generation. We introduce a "Control-Follow" clustering strategy, which dynamically adapts to scene scale and feature distribution, avoiding feature compression and significantly improving segmentation accuracy. Additionally, we enrich scene representation by integrating object attributes and spatial relations extracted from 2D foundation models. To address inaccuracies in spatial relationships, we propose 3D correction modules that filter implausible relations through spatial consistency verification, ensuring reliable scene graph construction. Extensive experiments on three datasets demonstrate that GaussianGraph outperforms state-of-the-art methods in both semantic segmentation and object grounding tasks, providing a robust solution for complex scene understanding and interaction.
OpenGS-SLAM: Open-Set Dense Semantic SLAM with 3D Gaussian Splatting for Object-Level Scene Understanding
Mar 03, 2025



Recent advancements in 3D Gaussian Splatting have significantly improved the efficiency and quality of dense semantic SLAM. However, previous methods are generally constrained by limited-category pre-trained classifiers and implicit semantic representation, which hinder their performance in open-set scenarios and restrict 3D object-level scene understanding. To address these issues, we propose OpenGS-SLAM, an innovative framework that utilizes 3D Gaussian representation to perform dense semantic SLAM in open-set environments. Our system integrates explicit semantic labels derived from 2D foundational models into the 3D Gaussian framework, facilitating robust 3D object-level scene understanding. We introduce Gaussian Voting Splatting to enable fast 2D label map rendering and scene updating. Additionally, we propose a Confidence-based 2D Label Consensus method to ensure consistent labeling across multiple views. Furthermore, we employ a Segmentation Counter Pruning strategy to improve the accuracy of semantic scene representation. Extensive experiments on both synthetic and real-world datasets demonstrate the effectiveness of our method in scene understanding, tracking, and mapping, achieving 10 times faster semantic rendering and 2 times lower storage costs compared to existing methods. Project page: https://young-bit.github.io/opengs-github.github.io/.
MetaFood CVPR 2024 Challenge on Physically Informed 3D Food Reconstruction: Methods and Results
Jul 12, 2024
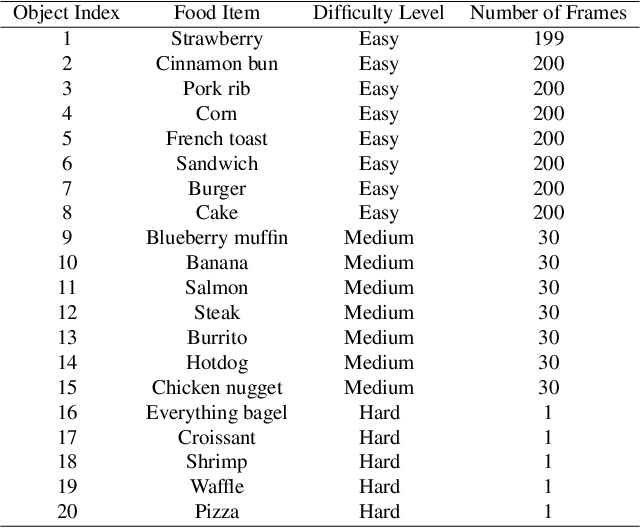
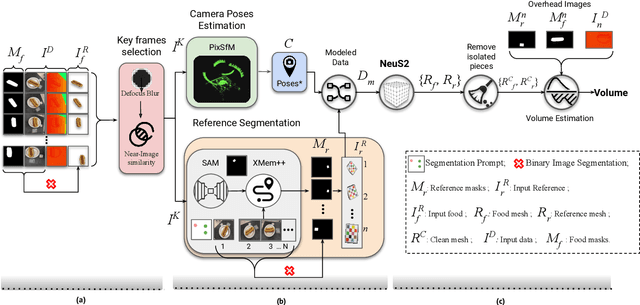
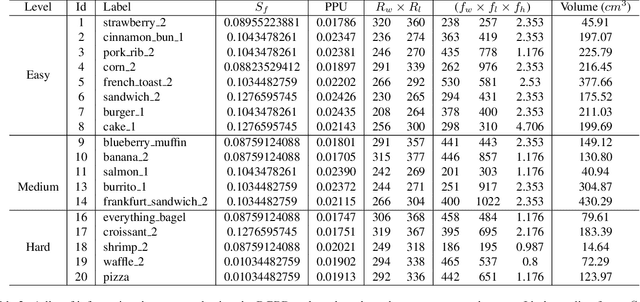
The increasing interest in computer vision applications for nutrition and dietary monitoring has led to the development of advanced 3D reconstruction techniques for food items. However, the scarcity of high-quality data and limited collaboration between industry and academia have constrained progress in this field. Building on recent advancements in 3D reconstruction, we host the MetaFood Workshop and its challenge for Physically Informed 3D Food Reconstruction. This challenge focuses on reconstructing volume-accurate 3D models of food items from 2D images, using a visible checkerboard as a size reference. Participants were tasked with reconstructing 3D models for 20 selected food items of varying difficulty levels: easy, medium, and hard. The easy level provides 200 images, the medium level provides 30 images, and the hard level provides only 1 image for reconstruction. In total, 16 teams submitted results in the final testing phase. The solutions developed in this challenge achieved promising results in 3D food reconstruction, with significant potential for improving portion estimation for dietary assessment and nutritional monitoring. More details about this workshop challenge and access to the dataset can be found at https://sites.google.com/view/cvpr-metafood-2024.
Sector Patch Embedding: An Embedding Module Conforming to The Distortion Pattern of Fisheye Image
Mar 26, 2023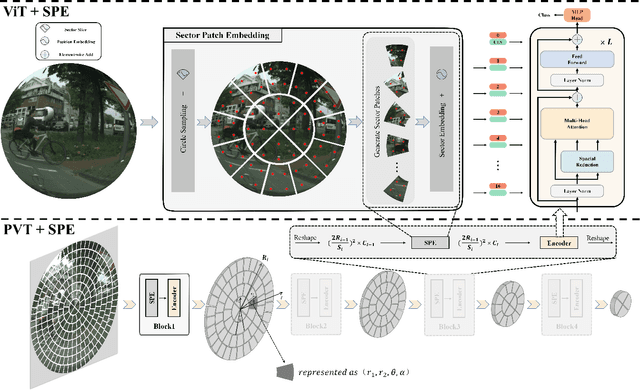
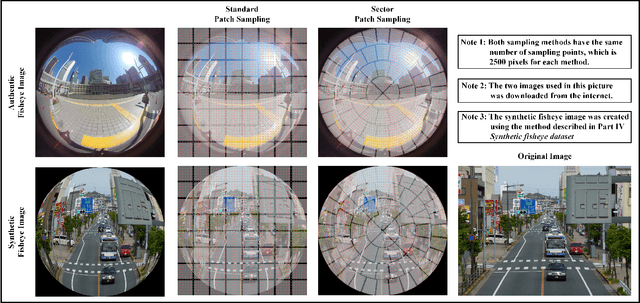
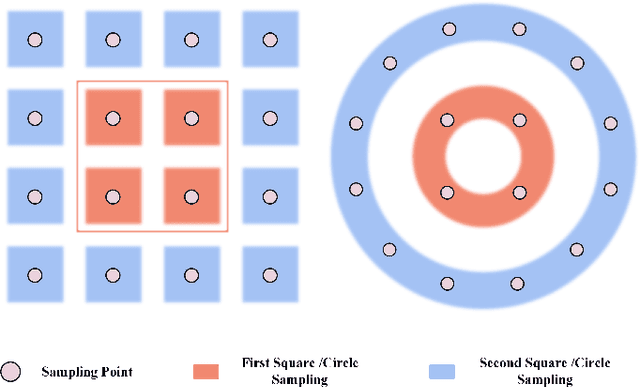
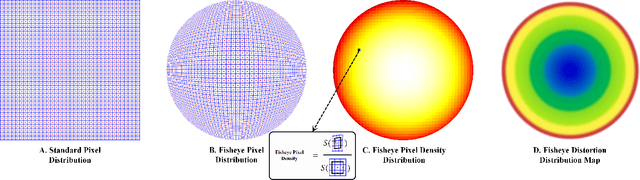
Fisheye cameras suffer from image distortion while having a large field of view(LFOV). And this fact leads to poor performance on some fisheye vision tasks. One of the solutions is to optimize the current vision algorithm for fisheye images. However, most of the CNN-based methods and the Transformer-based methods lack the capability of leveraging distortion information efficiently. In this work, we propose a novel patch embedding method called Sector Patch Embedding(SPE), conforming to the distortion pattern of the fisheye image. Furthermore, we put forward a synthetic fisheye dataset based on the ImageNet-1K and explore the performance of several Transformer models on the dataset. The classification top-1 accuracy of ViT and PVT is improved by 0.75% and 2.8% with SPE respectively. The experiments show that the proposed sector patch embedding method can better perceive distortion and extract features on the fisheye images. Our method can be easily adopted to other Transformer-based models. Source code is at https://github.com/IN2-ViAUn/Sector-Patch-Embedding.