 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFilterGS: Traversal-Free Parallel Filtering and Adaptive Shrinking for Large-Scale LoD 3D Gaussian Splatting
Mar 25, 20263D Gaussian Splatting has revolutionized neural rendering with real-time performance. However, scaling this approach to large scenes using Level-of-Detail methods faces critical challenges: inefficient serial traversal consuming over 60\% of rendering time, and redundant Gaussian-tile pairs that incur unnecessary processing overhead. To address these limitations, we introduce FilterGS, featuring a parallel filtering mechanism with two complementary filters that select Gaussian elements efficiently without tree traversal. Additionally, we propose a novel GTC metric that quantifies the redundancy of Gaussian-tile key-value pairs. Based on this metric, we introduce a scene-adaptive Gaussian shrinking strategy that effectively reduces redundant pairs. Extensive experiments demonstrate that FilterGS achieves state-of-the-art rendering speeds while maintaining competitive visual quality across multiple large-scale datasets. Project page: https://github.com/xenon-w/FilterGS
GaussianGraph: 3D Gaussian-based Scene Graph Generation for Open-world Scene Understanding
Mar 06, 2025Recent advancements in 3D Gaussian Splatting(3DGS) have significantly improved semantic scene understanding, enabling natural language queries to localize objects within a scene. However, existing methods primarily focus on embedding compressed CLIP features to 3D Gaussians, suffering from low object segmentation accuracy and lack spatial reasoning capabilities. To address these limitations, we propose GaussianGraph, a novel framework that enhances 3DGS-based scene understanding by integrating adaptive semantic clustering and scene graph generation. We introduce a "Control-Follow" clustering strategy, which dynamically adapts to scene scale and feature distribution, avoiding feature compression and significantly improving segmentation accuracy. Additionally, we enrich scene representation by integrating object attributes and spatial relations extracted from 2D foundation models. To address inaccuracies in spatial relationships, we propose 3D correction modules that filter implausible relations through spatial consistency verification, ensuring reliable scene graph construction. Extensive experiments on three datasets demonstrate that GaussianGraph outperforms state-of-the-art methods in both semantic segmentation and object grounding tasks, providing a robust solution for complex scene understanding and interaction.
OpenGS-SLAM: Open-Set Dense Semantic SLAM with 3D Gaussian Splatting for Object-Level Scene Understanding
Mar 03, 2025



Recent advancements in 3D Gaussian Splatting have significantly improved the efficiency and quality of dense semantic SLAM. However, previous methods are generally constrained by limited-category pre-trained classifiers and implicit semantic representation, which hinder their performance in open-set scenarios and restrict 3D object-level scene understanding. To address these issues, we propose OpenGS-SLAM, an innovative framework that utilizes 3D Gaussian representation to perform dense semantic SLAM in open-set environments. Our system integrates explicit semantic labels derived from 2D foundational models into the 3D Gaussian framework, facilitating robust 3D object-level scene understanding. We introduce Gaussian Voting Splatting to enable fast 2D label map rendering and scene updating. Additionally, we propose a Confidence-based 2D Label Consensus method to ensure consistent labeling across multiple views. Furthermore, we employ a Segmentation Counter Pruning strategy to improve the accuracy of semantic scene representation. Extensive experiments on both synthetic and real-world datasets demonstrate the effectiveness of our method in scene understanding, tracking, and mapping, achieving 10 times faster semantic rendering and 2 times lower storage costs compared to existing methods. Project page: https://young-bit.github.io/opengs-github.github.io/.
HandS3C: 3D Hand Mesh Reconstruction with State Space Spatial Channel Attention from RGB images
May 14, 2024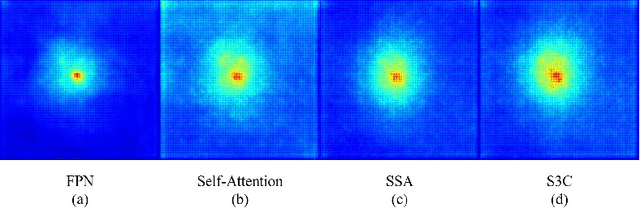
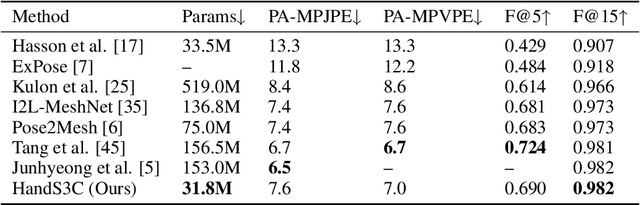


Reconstructing the hand mesh from one single RGB image is a challenging task because hands are often occluded by other objects. Most previous works attempt to explore more additional information and adopt attention mechanisms for improving 3D reconstruction performance, while it would increase computational complexity simultaneously. To achieve a performance-reserving architecture with high computational efficiency, in this work, we propose a simple but effective 3D hand mesh reconstruction network (i.e., HandS3C), which is the first time to incorporate state space model into the task of hand mesh reconstruction. In the network, we design a novel state-space spatial-channel attention module that extends the effective receptive field, extracts hand features in the spatial dimension, and enhances regional features of hands in the channel dimension. This helps to reconstruct a complete and detailed hand mesh. Extensive experiments conducted on well-known datasets facing heavy occlusions (such as FREIHAND, DEXYCB, and HO3D) demonstrate that our proposed HandS3C achieves state-of-the-art performance while maintaining a minimal parameters.
HandSSCA: 3D Hand Mesh Reconstruction with State Space Channel Attention from RGB images
May 02, 2024Reconstructing a hand mesh from a single RGB image is a challenging task because hands are often occluded by objects. Most previous works attempted to introduce more additional information and adopt attention mechanisms to improve 3D reconstruction results, but it would increased computational complexity. This observation prompts us to propose a new and concise architecture while improving computational efficiency. In this work, we propose a simple and effective 3D hand mesh reconstruction network HandSSCA, which is the first to incorporate state space modeling into the field of hand pose estimation. In the network, we have designed a novel state space channel attention module that extends the effective sensory field, extracts hand features in the spatial dimension, and enhances hand regional features in the channel dimension. This design helps to reconstruct a complete and detailed hand mesh. Extensive experiments conducted on well-known datasets featuring challenging hand-object occlusions (such as FREIHAND, DEXYCB, and HO3D) demonstrate that our proposed HandSSCA achieves state-of-the-art performance while maintaining a minimal parameter count.
CRRS: Concentric Rectangles Regression Strategy for Multi-point Representation on Fisheye Images
Mar 26, 2023



Modern object detectors take advantage of rectangular bounding boxes as a conventional way to represent objects. When it comes to fisheye images, rectangular boxes involve more background noise rather than semantic information. Although multi-point representation has been proposed, both the regression accuracy and convergence still perform inferior to the widely used rectangular boxes. In order to further exploit the advantages of multi-point representation for distorted images, Concentric Rectangles Regression Strategy(CRRS) is proposed in this work. We adopt smoother mean loss to allocate weights and discuss the effect of hyper-parameter to prediction results. Moreover, an accurate pixel-level method is designed to obtain irregular IoU for estimating detector performance. Compared with the previous work for muti-point representation, the experiments show that CRRS can improve the training performance both in accurate and stability. We also prove that multi-task weighting strategy facilitates regression process in this design.