 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrameRef: A Framing Dataset and Simulation Testbed for Modeling Bounded Rational Information Health
Feb 17, 2026Information ecosystems increasingly shape how people internalize exposure to adverse digital experiences, raising concerns about the long-term consequences for information health. In modern search and recommendation systems, ranking and personalization policies play a central role in shaping such exposure and its long-term effects on users. To study these effects in a controlled setting, we present FrameRef, a large-scale dataset of 1,073,740 systematically reframed claims across five framing dimensions: authoritative, consensus, emotional, prestige, and sensationalist, and propose a simulation-based framework for modeling sequential information exposure and reinforcement dynamics characteristic of ranking and recommendation systems. Within this framework, we construct framing-sensitive agent personas by fine-tuning language models with framing-conditioned loss attenuation, inducing targeted biases while preserving overall task competence. Using Monte Carlo trajectory sampling, we show that small, systematic shifts in acceptance and confidence can compound over time, producing substantial divergence in cumulative information health trajectories. Human evaluation further confirms that FrameRef's generated framings measurably affect human judgment. Together, our dataset and framework provide a foundation for systematic information health research through simulation, complementing and informing responsible human-centered research. We release FrameRef, code, documentation, human evaluation data, and persona adapter models at https://github.com/infosenselab/frameref.
ECHO: An Open Research Platform for Evaluation of Chat, Human Behavior, and Outcomes
Feb 10, 2026ECHO (Evaluation of Chat, Human behavior, and Outcomes) is an open research platform designed to support reproducible, mixed-method studies of human interaction with both conversational AI systems and Web search engines. It enables researchers from varying disciplines to orchestrate end-to-end experimental workflows that integrate consent and background surveys, chat-based and search-based information-seeking sessions, writing or judgment tasks, and pre- and post-task evaluations within a unified, low-coding-load framework. ECHO logs fine-grained interaction traces and participant responses, and exports structured datasets for downstream analysis. By supporting both chat and search alongside flexible evaluation instruments, ECHO lowers technical barriers for studying learning, decision making, and user experience across different information access paradigms, empowering researchers from information retrieval, HCI, and the social sciences to conduct scalable and reproducible human-centered AI evaluations.
Bounded Minds, Generative Machines: Envisioning Conversational AI that Works with Human Heuristics and Reduces Bias Risk
Jan 19, 2026Conversational AI is rapidly becoming a primary interface for information seeking and decision making, yet most systems still assume idealized users. In practice, human reasoning is bounded by limited attention, uneven knowledge, and reliance on heuristics that are adaptive but bias-prone. This article outlines a research pathway grounded in bounded rationality, and argues that conversational AI should be designed to work with human heuristics rather than against them. It identifies key directions for detecting cognitive vulnerability, supporting judgment under uncertainty, and evaluating conversational systems beyond factual accuracy, toward decision quality and cognitive robustness.
Re-Rankers as Relevance Judges
Jan 08, 2026Using large language models (LLMs) to predict relevance judgments has shown promising results. Most studies treat this task as a distinct research line, e.g., focusing on prompt design for predicting relevance labels given a query and passage. However, predicting relevance judgments is essentially a form of relevance prediction, a problem extensively studied in tasks such as re-ranking. Despite this potential overlap, little research has explored reusing or adapting established re-ranking methods to predict relevance judgments, leading to potential resource waste and redundant development. To bridge this gap, we reproduce re-rankers in a re-ranker-as-relevance-judge setup. We design two adaptation strategies: (i) using binary tokens (e.g., "true" and "false") generated by a re-ranker as direct judgments, and (ii) converting continuous re-ranking scores into binary labels via thresholding. We perform extensive experiments on TREC-DL 2019 to 2023 with 8 re-rankers from 3 families, ranging from 220M to 32B, and analyse the evaluation bias exhibited by re-ranker-based judges. Results show that re-ranker-based relevance judges, under both strategies, can outperform UMBRELA, a state-of-the-art LLM-based relevance judge, in around 40% to 50% of the cases; they also exhibit strong self-preference towards their own and same-family re-rankers, as well as cross-family bias.
Judging with Personality and Confidence: A Study on Personality-Conditioned LLM Relevance Assessment
Jan 05, 2026Recent studies have shown that prompting can enable large language models (LLMs) to simulate specific personality traits and produce behaviors that align with those traits. However, there is limited understanding of how these simulated personalities influence critical web search decisions, specifically relevance assessment. Moreover, few studies have examined how simulated personalities impact confidence calibration, specifically the tendencies toward overconfidence or underconfidence. This gap exists even though psychological literature suggests these biases are trait-specific, often linking high extraversion to overconfidence and high neuroticism to underconfidence. To address this gap, we conducted a comprehensive study evaluating multiple LLMs, including commercial models and open-source models, prompted to simulate Big Five personality traits. We tested these models across three test collections (TREC DL 2019, TREC DL 2020, and LLMJudge), collecting two key outputs for each query-document pair: a relevance judgment and a self-reported confidence score. The findings show that personalities such as low agreeableness consistently align more closely with human labels than the unprompted condition. Additionally, low conscientiousness performs well in balancing the suppression of both overconfidence and underconfidence. We also observe that relevance scores and confidence distributions vary systematically across different personalities. Based on the above findings, we incorporate personality-conditioned scores and confidence as features in a random forest classifier. This approach achieves performance that surpasses the best single-personality condition on a new dataset (TREC DL 2021), even with limited training data. These findings highlight that personality-derived confidence offers a complementary predictive signal, paving the way for more reliable and human-aligned LLM evaluators.
Improving Data Reusability in Interactive Information Retrieval: Insights from the Community
Dec 20, 2025In this study, we conducted semi-structured interviews with 21 IIR researchers to investigate their data reuse practices. This study aims to expand upon current findings by exploring IIR researchers' information-obtaining behaviors regarding data reuse. We identified the information about shared data characteristics that IIR researchers need when evaluating data reusability, as well as the sources they typically consult to obtain this information. We consider this work to be an initial step toward revealing IIR researchers' data reuse practices and identifying what the community needs to do to promote data reuse. We hope that this study, as well as future research, will inspire more individuals to contribute to ongoing efforts aimed at designing standards, infrastructures, and policies, as well as fostering a sustainable culture of data sharing and reuse in this field.
Not All Transparency Is Equal: Source Presentation Effects on Attention, Interaction, and Persuasion in Conversational Search
Dec 13, 2025Conversational search systems increasingly provide source citations, yet how citation or source presentation formats influence user engagement remains unclear. We conducted a crowdsourcing user experiment with 394 participants comparing four source presentation designs that varied citation visibility and accessibility: collapsible lists, hover cards, footer lists, and aligned sidebars.High-visibility interfaces generated substantially more hovering on sources, though clicking remained infrequent across all conditions. While interface design showed limited effects on user experience and perception measures, it significantly influenced knowledge, interest, and agreement changes. High-visibility interfaces initially reduced knowledge gain and interest, but these positive effects emerged with increasing source usage. The sidebar condition uniquely increased agreement change. Our findings demonstrate that source presentation alone may not enhance engagement and can even reduce it when insufficient sources are provided.
LLM-Driven Usefulness Judgment for Web Search Evaluation
Apr 19, 2025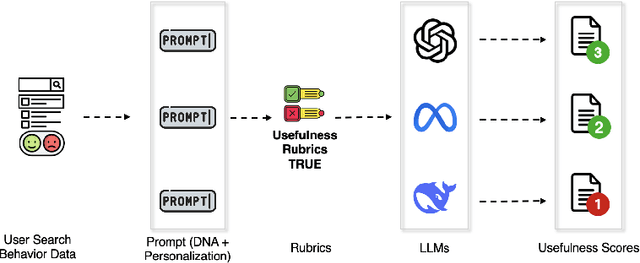

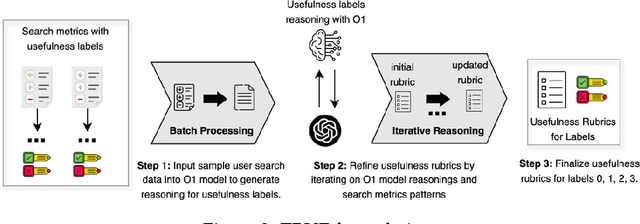
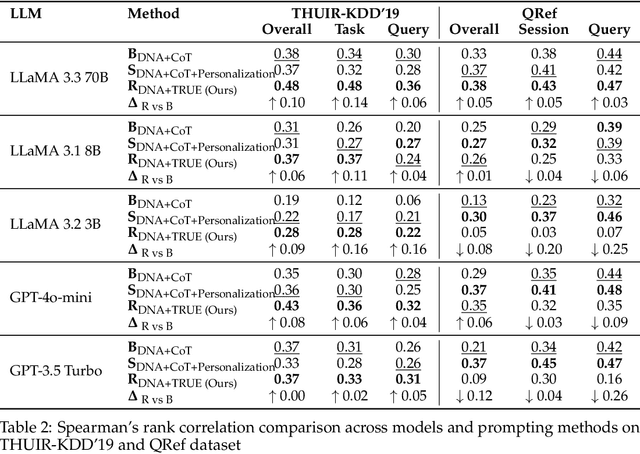
Evaluation is fundamental in optimizing search experiences and supporting diverse user intents in Information Retrieval (IR). Traditional search evaluation methods primarily rely on relevance labels, which assess how well retrieved documents match a user's query. However, relevance alone fails to capture a search system's effectiveness in helping users achieve their search goals, making usefulness a critical evaluation criterion. In this paper, we explore an alternative approach: LLM-generated usefulness labels, which incorporate both implicit and explicit user behavior signals to evaluate document usefulness. We propose Task-aware Rubric-based Usefulness Evaluation (TRUE), a rubric-driven evaluation method that employs iterative sampling and reasoning to model complex search behavior patterns. Our findings show that (i) LLMs can generate moderate usefulness labels by leveraging comprehensive search session history incorporating personalization and contextual understanding, and (ii) fine-tuned LLMs improve usefulness judgments when provided with structured search session contexts. Additionally, we examine whether LLMs can distinguish between relevance and usefulness, particularly in cases where this divergence impacts search success. We also conduct an ablation study to identify key metrics for accurate usefulness label generation, optimizing for token efficiency and cost-effectiveness in real-world applications. This study advances LLM-based usefulness evaluation by refining key user metrics, exploring LLM-generated label reliability, and ensuring feasibility for large-scale search systems.
Trapped by Expectations: Functional Fixedness in LLM-Enabled Chat Search
Apr 02, 2025Functional fixedness, a cognitive bias that restricts users' interactions with a new system or tool to expected or familiar ways, limits the full potential of Large Language Model (LLM)-enabled chat search, especially in complex and exploratory tasks. To investigate its impact, we conducted a crowdsourcing study with 450 participants, each completing one of six decision-making tasks spanning public safety, diet and health management, sustainability, and AI ethics. Participants engaged in a multi-prompt conversation with ChatGPT to address the task, allowing us to compare pre-chat intent-based expectations with observed interactions. We found that: 1) Several aspects of pre-chat expectations are closely associated with users' prior experiences with ChatGPT, search engines, and virtual assistants; 2) Prior system experience shapes language use and prompting behavior. Frequent ChatGPT users reduced deictic terms and hedge words and frequently adjusted prompts. Users with rich search experience maintained structured, less-conversational queries with minimal modifications. Users of virtual assistants favored directive, command-like prompts, reinforcing functional fixedness; 3) When the system failed to meet expectations, participants generated more detailed prompts with increased linguistic diversity, reflecting adaptive shifts. These findings suggest that while preconceived expectations constrain early interactions, unmet expectations can motivate behavioral adaptation. With appropriate system support, this may promote broader exploration of LLM capabilities. This work also introduces a typology for user intents in chat search and highlights the importance of mitigating functional fixedness to support more creative and analytical use of LLMs.
LLM-Driven Usefulness Labeling for IR Evaluation
Mar 12, 2025In the information retrieval (IR) domain, evaluation plays a crucial role in optimizing search experiences and supporting diverse user intents. In the recent LLM era, research has been conducted to automate document relevance labels, as these labels have traditionally been assigned by crowd-sourced workers - a process that is both time and consuming and costly. This study focuses on LLM-generated usefulness labels, a crucial evaluation metric that considers the user's search intents and task objectives, an aspect where relevance falls short. Our experiment utilizes task-level, query-level, and document-level features along with user search behavior signals, which are essential in defining the usefulness of a document. Our research finds that (i) pre-trained LLMs can generate moderate usefulness labels by understanding the comprehensive search task session, (ii) pre-trained LLMs perform better judgement in short search sessions when provided with search session contexts. Additionally, we investigated whether LLMs can capture the unique divergence between relevance and usefulness, along with conducting an ablation study to identify the most critical metrics for accurate usefulness label generation. In conclusion, this work explores LLM-generated usefulness labels by evaluating critical metrics and optimizing for practicality in real-world settings.