 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy That Robot? A Qualitative Analysis of Justification Strategies for Robot Color Selection Across Occupational Contexts
Mar 30, 2026As robots increasingly enter the workforce, human-robot interaction (HRI) must address how implicit social biases influence user preferences. This paper investigates how users rationalize their selections of robots varying in skin tone and anthropomorphic features across different occupations. By qualitatively analyzing 4,146 open-ended justifications from 1,038 participants, we map the reasoning frameworks driving robot color selection across four professional contexts. We developed and validated a comprehensive, multidimensional coding scheme via human--AI consensus ($κ= 0.73$). Our results demonstrate that while utilitarian \textit{Functionalism} is the dominant justification strategy (52\%), participants systematically adapted these practical rationales to align with established racial and occupational stereotypes. Furthermore, we reveal that bias frequently operates beneath conscious rationalization: exposure to racial stereotype primes significantly shifted participants' color choices, yet their spoken justifications remained masked by standard affective or task-related reasoning. We also found that demographic backgrounds significantly shape justification strategies, and that robot shape strongly modulates color interpretation. Specifically, as robots become highly anthropomorphic, users increasingly retreat from functional reasoning toward \textit{Machine-Centric} de-racialization. Through these empirical results, we provide actionable design implications to help reduce the perpetuation of societal biases in future workforce robots.
From Human Bias to Robot Choice: How Occupational Contexts and Racial Priming Shape Robot Selection
Dec 24, 2025



As artificial agents increasingly integrate into professional environments, fundamental questions have emerged about how societal biases influence human-robot selection decisions. We conducted two comprehensive experiments (N = 1,038) examining how occupational contexts and stereotype activation shape robotic agent choices across construction, healthcare, educational, and athletic domains. Participants made selections from artificial agents that varied systematically in skin tone and anthropomorphic characteristics. Our study revealed distinct context-dependent patterns. Healthcare and educational scenarios demonstrated strong favoritism toward lighter-skinned artificial agents, while construction and athletic contexts showed greater acceptance of darker-toned alternatives. Participant race was associated with systematic differences in selection patterns across professional domains. The second experiment demonstrated that exposure to human professionals from specific racial backgrounds systematically shifted later robotic agent preferences in stereotype-consistent directions. These findings show that occupational biases and color-based discrimination transfer directly from human-human to human-robot evaluation contexts. The results highlight mechanisms through which robotic deployment may unintentionally perpetuate existing social inequalities.
Not All Transparency Is Equal: Source Presentation Effects on Attention, Interaction, and Persuasion in Conversational Search
Dec 13, 2025Conversational search systems increasingly provide source citations, yet how citation or source presentation formats influence user engagement remains unclear. We conducted a crowdsourcing user experiment with 394 participants comparing four source presentation designs that varied citation visibility and accessibility: collapsible lists, hover cards, footer lists, and aligned sidebars.High-visibility interfaces generated substantially more hovering on sources, though clicking remained infrequent across all conditions. While interface design showed limited effects on user experience and perception measures, it significantly influenced knowledge, interest, and agreement changes. High-visibility interfaces initially reduced knowledge gain and interest, but these positive effects emerged with increasing source usage. The sidebar condition uniquely increased agreement change. Our findings demonstrate that source presentation alone may not enhance engagement and can even reduce it when insufficient sources are provided.
Investigating the Impact of LLM Personality on Cognitive Bias Manifestation in Automated Decision-Making Tasks
Feb 20, 2025Large Language Models (LLMs) are increasingly used in decision-making, yet their susceptibility to cognitive biases remains a pressing challenge. This study explores how personality traits influence these biases and evaluates the effectiveness of mitigation strategies across various model architectures. Our findings identify six prevalent cognitive biases, while the sunk cost and group attribution biases exhibit minimal impact. Personality traits play a crucial role in either amplifying or reducing biases, significantly affecting how LLMs respond to debiasing techniques. Notably, Conscientiousness and Agreeableness may generally enhance the efficacy of bias mitigation strategies, suggesting that LLMs exhibiting these traits are more receptive to corrective measures. These findings address the importance of personality-driven bias dynamics and highlight the need for targeted mitigation approaches to improve fairness and reliability in AI-assisted decision-making.
The Decoy Dilemma in Online Medical Information Evaluation: A Comparative Study of Credibility Assessments by LLM and Human Judges
Nov 23, 2024

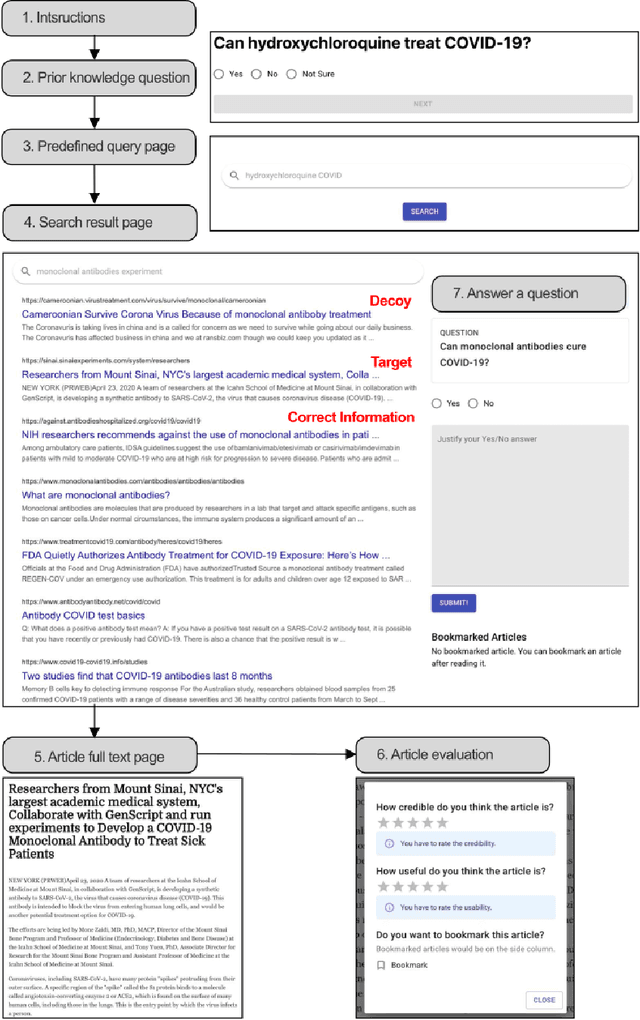

Can AI be cognitively biased in automated information judgment tasks? Despite recent progresses in measuring and mitigating social and algorithmic biases in AI and large language models (LLMs), it is not clear to what extent LLMs behave "rationally", or if they are also vulnerable to human cognitive bias triggers. To address this open problem, our study, consisting of a crowdsourcing user experiment and a LLM-enabled simulation experiment, compared the credibility assessments by LLM and human judges under potential decoy effects in an information retrieval (IR) setting, and empirically examined the extent to which LLMs are cognitively biased in COVID-19 medical (mis)information assessment tasks compared to traditional human assessors as a baseline. The results, collected from a between-subject user experiment and a LLM-enabled replicate experiment, demonstrate that 1) Larger and more recent LLMs tend to show a higher level of consistency and accuracy in distinguishing credible information from misinformation. However, they are more likely to give higher ratings for misinformation due to the presence of a more salient, decoy misinformation result; 2) While decoy effect occurred in both human and LLM assessments, the effect is more prevalent across different conditions and topics in LLM judgments compared to human credibility ratings. In contrast to the generally assumed "rationality" of AI tools, our study empirically confirms the cognitive bias risks embedded in LLM agents, evaluates the decoy impact on LLMs against human credibility assessments, and thereby highlights the complexity and importance of debiasing AI agents and developing psychology-informed AI audit techniques and policies for automated judgment tasks and beyond.
Understanding the Changing Roles of Scientific Publications via Citation Embeddings
Nov 15, 2017
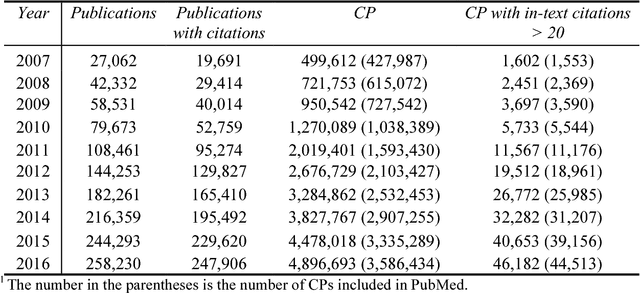
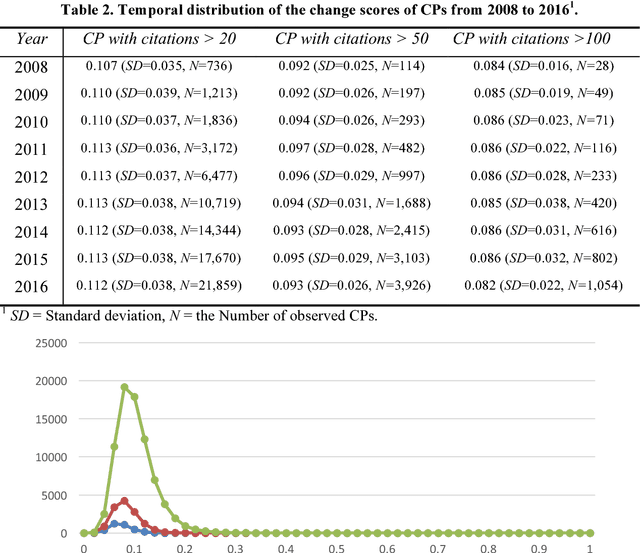
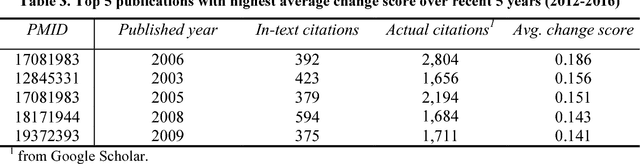
Researchers may describe different aspects of past scientific publications in their publications and the descriptions may keep changing in the evolution of science. The diverse and changing descriptions (i.e., citation context) on a publication characterize the impact and contributions of the past publication. In this article, we aim to provide an approach to understanding the changing and complex roles of a publication characterized by its citation context. We described a method to represent the publications' dynamic roles in science community in different periods as a sequence of vectors by training temporal embedding models. The temporal representations can be used to quantify how much the roles of publications changed and interpret how they changed. Our study in the biomedical domain shows that our metric on the changes of publications' roles is stable over time at the population level but significantly distinguish individuals. We also show the interpretability of our methods by a concrete example.