 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvolutional Quantum-Like Language Model with Mutual-Attention for Product Rating Prediction
Dec 25, 2019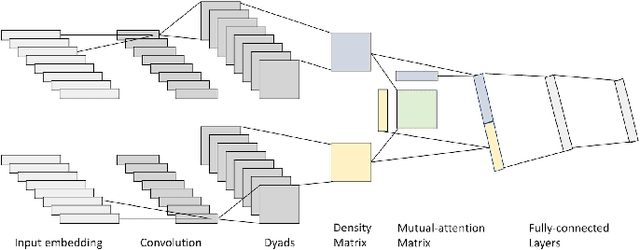
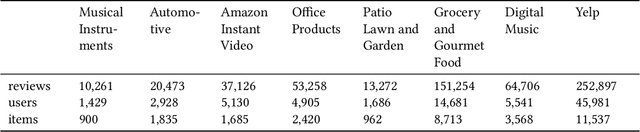
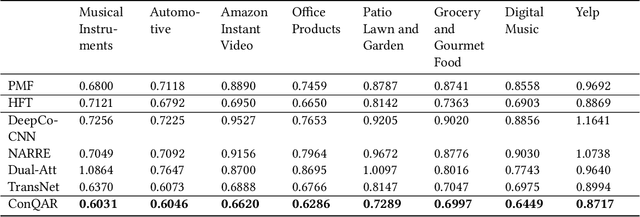
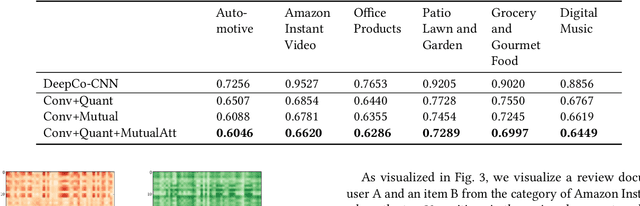
Recommender systems are designed to help mitigate information overload users experience during online shopping. Recent work explores neural language models to learn user and item representations from user reviews and combines such representations with rating information. Most existing convolutional-based neural models take pooling immediately after convolution and loses the interaction information between the latent dimension of convolutional feature vectors along the way. Moreover, these models usually take all feature vectors at higher levels as equal and do not take into consideration that some features are more relevant to this specific user-item context. To bridge these gaps, this paper proposes a convolutional quantum-like language model with mutual-attention for rating prediction (ConQAR). By introducing a quantum-like density matrix layer, interactions between latent dimensions of convolutional feature vectors are well captured. With the attention weights learned from the mutual-attention layer, final representations of a user and an item absorb information from both itself and its counterparts for making rating prediction. Experiments on two large datasets show that our model outperforms multiple state-of-the-art CNN-based models. We also perform an ablation test to analyze the independent effects of the two components of our model. Moreover, we conduct a case study and present visualizations of the quantum probabilistic distributions in one user and one item review document to show that the learned distributions capture meaningful information about this user and item, and can be potentially used as textual profiling of the user and item.
Understanding the Changing Roles of Scientific Publications via Citation Embeddings
Nov 15, 2017
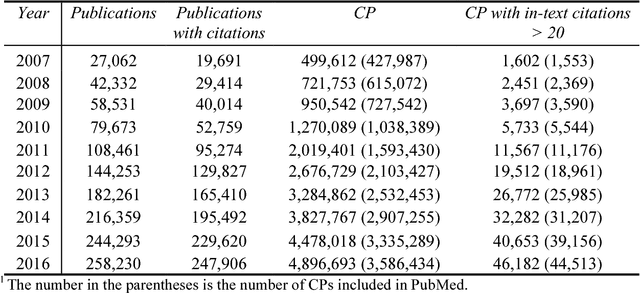
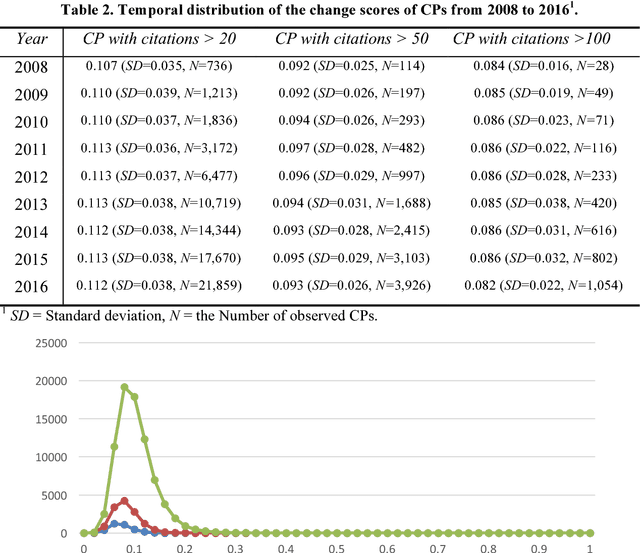
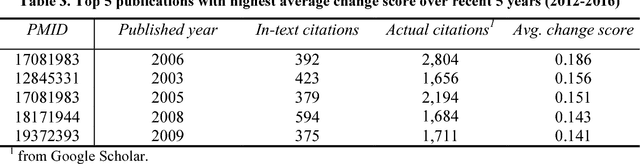
Researchers may describe different aspects of past scientific publications in their publications and the descriptions may keep changing in the evolution of science. The diverse and changing descriptions (i.e., citation context) on a publication characterize the impact and contributions of the past publication. In this article, we aim to provide an approach to understanding the changing and complex roles of a publication characterized by its citation context. We described a method to represent the publications' dynamic roles in science community in different periods as a sequence of vectors by training temporal embedding models. The temporal representations can be used to quantify how much the roles of publications changed and interpret how they changed. Our study in the biomedical domain shows that our metric on the changes of publications' roles is stable over time at the population level but significantly distinguish individuals. We also show the interpretability of our methods by a concrete example.
LitStoryTeller: An Interactive System for Visual Exploration of Scientific Papers Leveraging Named entities and Comparative Sentences
Sep 12, 2017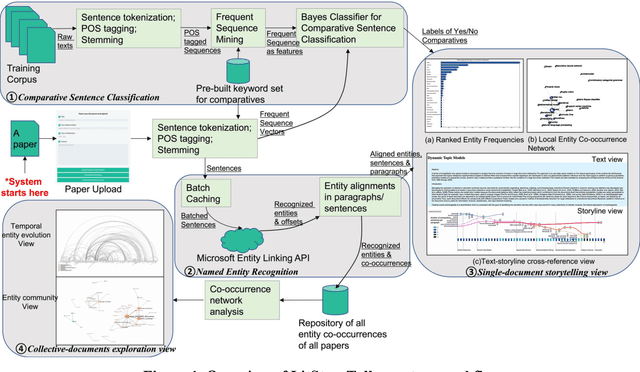
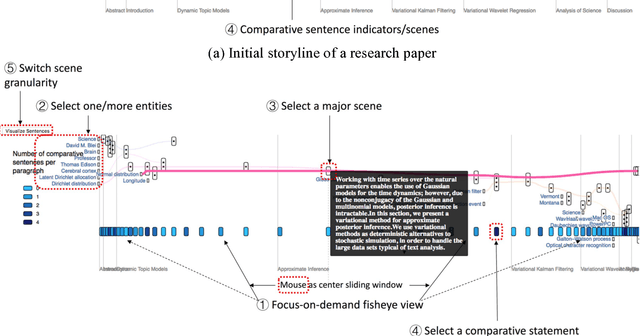
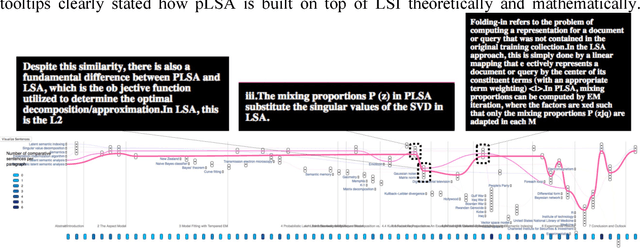
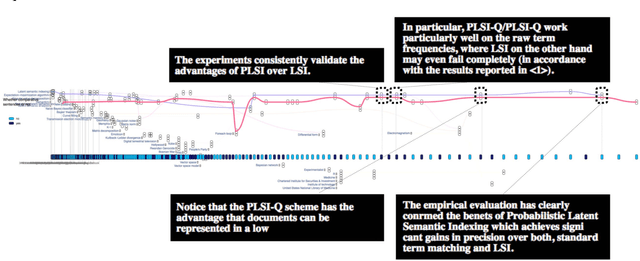
The present study proposes LitStoryTeller, an interactive system for visually exploring the semantic structure of a scientific article. We demonstrate how LitStoryTeller could be used to answer some of the most fundamental research questions, such as how a new method was built on top of existing methods, based on what theoretical proof and experimental evidences. More importantly, LitStoryTeller can assist users to understand the full and interesting story a scientific paper, with a concise outline and important details. The proposed system borrows a metaphor from screen play, and visualizes the storyline of a scientific paper by arranging its characters (scientific concepts or terminologies) and scenes (paragraphs/sentences) into a progressive and interactive storyline. Such storylines help to preserve the semantic structure and logical thinking process of a scientific paper. Semantic structures, such as scientific concepts and comparative sentences, are extracted using existing named entity recognition APIs and supervised classifiers, from a scientific paper automatically. Two supplementary views, ranked entity frequency view and entity co-occurrence network view, are provided to help users identify the "main plot" of such scientific storylines. When collective documents are ready, LitStoryTeller also provides a temporal entity evolution view and entity community view for collection digestion.
Video Highlights Detection and Summarization with Lag-Calibration based on Concept-Emotion Mapping of Crowd-sourced Time-Sync Comments
Aug 07, 2017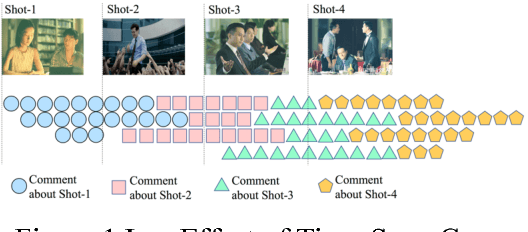


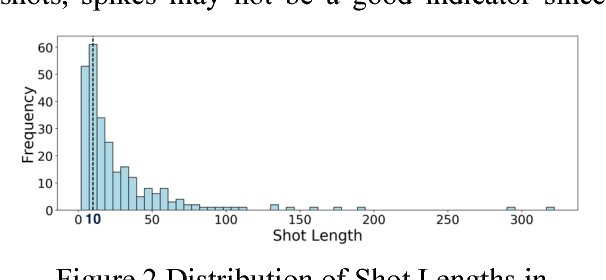
With the prevalence of video sharing, there are increasing demands for automatic video digestion such as highlight detection. Recently, platforms with crowdsourced time-sync video comments have emerged worldwide, providing a good opportunity for highlight detection. However, this task is non-trivial: (1) time-sync comments often lag behind their corresponding shot; (2) time-sync comments are semantically sparse and noisy; (3) to determine which shots are highlights is highly subjective. The present paper aims to tackle these challenges by proposing a framework that (1) uses concept-mapped lexical-chains for lag calibration; (2) models video highlights based on comment intensity and combination of emotion and concept concentration of each shot; (3) summarize each detected highlight using improved SumBasic with emotion and concept mapping. Experiments on large real-world datasets show that our highlight detection method and summarization method both outperform other benchmarks with considerable margins.