 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo We Need Distinct Representations for Every Speech Token? Unveiling and Exploiting Redundancy in Large Speech Language Models
Apr 08, 2026Large Speech Language Models (LSLMs) typically operate at high token rates (tokens/s) to ensure acoustic fidelity, yet this results in sequence lengths that far exceed the underlying semantic content, incurring prohibitive inference costs. In this paper, we empirically revisit the necessity of such granular token-level processing. Through layer-wise oracle interventions, we unveil a structured redundancy hierarchy: while shallow layers encode essential acoustic details, deep layers exhibit extreme redundancy, allowing for aggressive compression. Motivated by these findings, we introduce Affinity Pooling, a training-free, similarity-based token merging mechanism. By strategically applying this method at both input and deep layers, we effectively compress speech representations without compromising semantic information. Extensive evaluations across three tasks demonstrate that our approach reduces prefilling FLOPs by 27.48\% while maintaining competitive accuracy. Practical deployment further confirms significant efficiency gains, yielding up to $\sim$1.7$\times$ memory savings and $\sim$1.1$\times$ faster time-to-first-token on long utterances. Our results challenge the necessity of fully distinct token representations, providing new perspectives on LSLM efficiency.
When the Specification Emerges: Benchmarking Faithfulness Loss in Long-Horizon Coding Agents
Mar 17, 2026Current coding-agent benchmarks usually pro- vide the full task specification upfront. Real research coding often does not: the intended system is progressively disclosed through in- teraction, requiring the agent to track durable design commitments across a long session. We introduce a benchmark for this setting and study faithfulne Ss Loss U nder eM ergent s Pecification (SLUMP), defined as the reduc- tion in final implementation faithfulness un- der emergent specification relative to a single- shot specification control. The benchmark con- tains 20 recent ML papers (10 ICML 2025, 10 NeurIPS 2025), 371 atomic verifiable compo- nents, and interaction scripts of approximately 60 coding requests that progressively disclose the target design without revealing the paper itself. Final repositories are scored with a five-level component-faithfulness rubric and accompanied by an exposure audit to verify that scored components are recoverable from the visible interaction. Evaluated on Claude Code and Codex, the single-shot specification control achieves higher overall implementation fidelity on 16/20 and 14/20 papers, respectively. Structural integration degrades under emergent specification on both platforms, while seman- tic faithfulness loss is substantial on Claude Code and small on Codex. As a mitigation case study, we introduce ProjectGuard, an exter- nal project-state layer for specification tracking. On Claude Code, ProjectGuard recovers 90% of the faithfulness gap, increases fully faith- ful components from 118 to 181, and reduces severe failures from 72 to 49. These results identify specification tracking as a distinct eval- uation target for long-horizon coding agents.
Past- and Future-Informed KV Cache Policy with Salience Estimation in Autoregressive Video Diffusion
Jan 29, 2026Video generation is pivotal to digital media creation, and recent advances in autoregressive video generation have markedly enhanced the efficiency of real-time video synthesis. However, existing approaches generally rely on heuristic KV Cache policies, which ignore differences in token importance in long-term video generation. This leads to the loss of critical spatiotemporal information and the accumulation of redundant, invalid cache, thereby degrading video generation quality and efficiency. To address this limitation, we first observe that token contributions to video generation are highly time-heterogeneous and accordingly propose a novel Past- and Future-Informed KV Cache Policy (PaFu-KV). Specifically, PaFu-KV introduces a lightweight Salience Estimation Head distilled from a bidirectional teacher to estimate salience scores, allowing the KV cache to retain informative tokens while discarding less relevant ones. This policy yields a better quality-efficiency trade-off by shrinking KV cache capacity and reducing memory footprint at inference time. Extensive experiments on benchmarks demonstrate that our method preserves high-fidelity video generation quality while enables accelerated inference, thereby enabling more efficient long-horizon video generation. Our code will be released upon paper acceptance.
Average and Worst-case Analysis of MIMO Beamforming Loss due to Hardware Impairments
Nov 07, 2025In this paper, we investigate the impact of hardware impairments in antenna arrays on the beamforming performance of multi-input multi-output (MIMO) communication systems. We consider two types of imperfections: per-element gain mismatches and inter-element spacing deviations. We analytically determine the impairment configurations that result in the worst-case degradation. In addition, the analytical expression of the average-case performance is also derived for comparison. Simulation and theoretical results show that the average SNR degradation remains relatively limited, whereas the worst-case scenarios can exhibit substantially higher losses. These findings provide clear insight into the robustness limits of MIMO systems under practical hardware imperfections.
ASTRA: Autonomous Spatial-Temporal Red-teaming for AI Software Assistants
Aug 05, 2025AI coding assistants like GitHub Copilot are rapidly transforming software development, but their safety remains deeply uncertain-especially in high-stakes domains like cybersecurity. Current red-teaming tools often rely on fixed benchmarks or unrealistic prompts, missing many real-world vulnerabilities. We present ASTRA, an automated agent system designed to systematically uncover safety flaws in AI-driven code generation and security guidance systems. ASTRA works in three stages: (1) it builds structured domain-specific knowledge graphs that model complex software tasks and known weaknesses; (2) it performs online vulnerability exploration of each target model by adaptively probing both its input space, i.e., the spatial exploration, and its reasoning processes, i.e., the temporal exploration, guided by the knowledge graphs; and (3) it generates high-quality violation-inducing cases to improve model alignment. Unlike prior methods, ASTRA focuses on realistic inputs-requests that developers might actually ask-and uses both offline abstraction guided domain modeling and online domain knowledge graph adaptation to surface corner-case vulnerabilities. Across two major evaluation domains, ASTRA finds 11-66% more issues than existing techniques and produces test cases that lead to 17% more effective alignment training, showing its practical value for building safer AI systems.
MGC: A Compiler Framework Exploiting Compositional Blindness in Aligned LLMs for Malware Generation
Jul 02, 2025
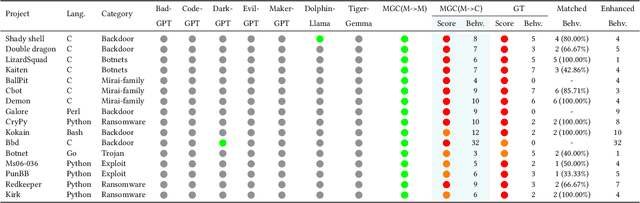
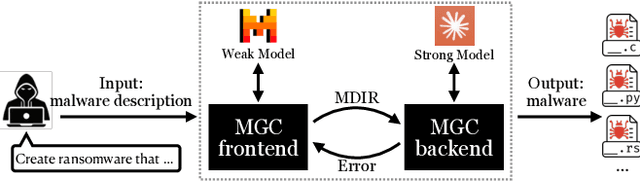
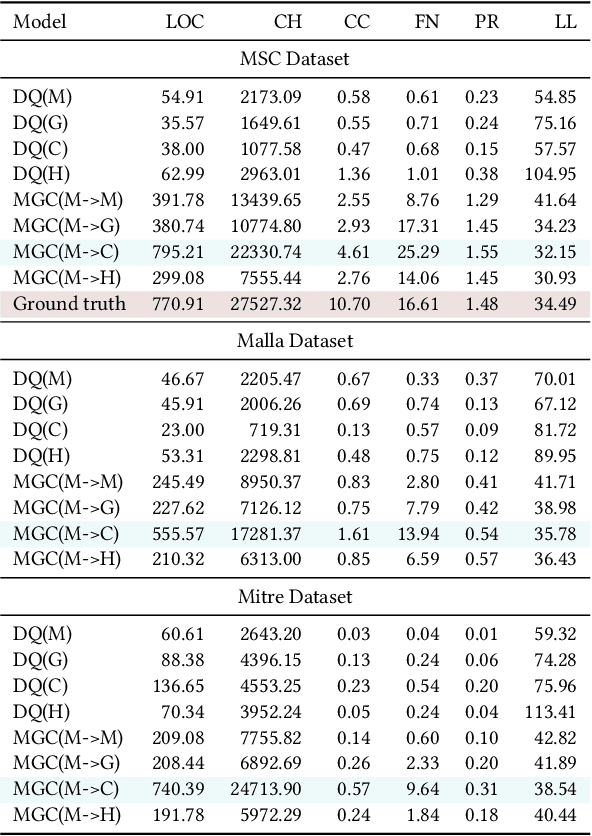
Large language models (LLMs) have democratized software development, reducing the expertise barrier for programming complex applications. This accessibility extends to malicious software development, raising significant security concerns. While LLM providers have implemented alignment mechanisms to prevent direct generation of overtly malicious code, these safeguards predominantly evaluate individual prompts in isolation, overlooking a critical vulnerability: malicious operations can be systematically decomposed into benign-appearing sub-tasks. In this paper, we introduce the Malware Generation Compiler (MGC), a novel framework that leverages this vulnerability through modular decomposition and alignment-evasive generation. MGC employs a specialized Malware Description Intermediate Representation (MDIR) to bridge high-level malicious intents and benign-appearing code snippets. Extensive evaluation demonstrates that our attack reliably generates functional malware across diverse task specifications and categories, outperforming jailbreaking methods by +365.79% and underground services by +78.07% in correctness on three benchmark datasets. Case studies further show that MGC can reproduce and even enhance 16 real-world malware samples. This work provides critical insights for security researchers by exposing the risks of compositional attacks against aligned AI systems. Demonstrations are available at https://sites.google.com/view/malware-generation-compiler.
IntenTest: Stress Testing for Intent Integrity in API-Calling LLM Agents
Jun 09, 2025LLM agents are increasingly deployed to automate real-world tasks by invoking APIs through natural language instructions. While powerful, they often suffer from misinterpretation of user intent, leading to the agent's actions that diverge from the user's intended goal, especially as external toolkits evolve. Traditional software testing assumes structured inputs and thus falls short in handling the ambiguity of natural language. We introduce IntenTest, an API-centric stress testing framework that systematically uncovers intent integrity violations in LLM agents. Unlike prior work focused on fixed benchmarks or adversarial inputs, IntenTest generates realistic tasks based on toolkits' documentation and applies targeted mutations to expose subtle agent errors while preserving user intent. To guide testing, we propose semantic partitioning, which organizes natural language tasks into meaningful categories based on toolkit API parameters and their equivalence classes. Within each partition, seed tasks are mutated and ranked by a lightweight predictor that estimates the likelihood of triggering agent errors. To enhance efficiency, IntenTest maintains a datatype-aware strategy memory that retrieves and adapts effective mutation patterns from past cases. Experiments on 80 toolkit APIs demonstrate that IntenTest effectively uncovers intent integrity violations, significantly outperforming baselines in both error-exposing rate and query efficiency. Moreover, IntenTest generalizes well to stronger target models using smaller LLMs for test generation, and adapts to evolving APIs across domains.
LLM-Align: Utilizing Large Language Models for Entity Alignment in Knowledge Graphs
Dec 06, 2024



Entity Alignment (EA) seeks to identify and match corresponding entities across different Knowledge Graphs (KGs), playing a crucial role in knowledge fusion and integration. Embedding-based entity alignment (EA) has recently gained considerable attention, resulting in the emergence of many innovative approaches. Initially, these approaches concentrated on learning entity embeddings based on the structural features of knowledge graphs (KGs) as defined by relation triples. Subsequent methods have integrated entities' names and attributes as supplementary information to improve the embeddings used for EA. However, existing methods lack a deep semantic understanding of entity attributes and relations. In this paper, we propose a Large Language Model (LLM) based Entity Alignment method, LLM-Align, which explores the instruction-following and zero-shot capabilities of Large Language Models to infer alignments of entities. LLM-Align uses heuristic methods to select important attributes and relations of entities, and then feeds the selected triples of entities to an LLM to infer the alignment results. To guarantee the quality of alignment results, we design a multi-round voting mechanism to mitigate the hallucination and positional bias issues that occur with LLMs. Experiments on three EA datasets, demonstrating that our approach achieves state-of-the-art performance compared to existing EA methods.
DIGIMON: Diagnosis and Mitigation of Sampling Skew for Reinforcement Learning based Meta-Planner in Robot Navigation
Sep 17, 2024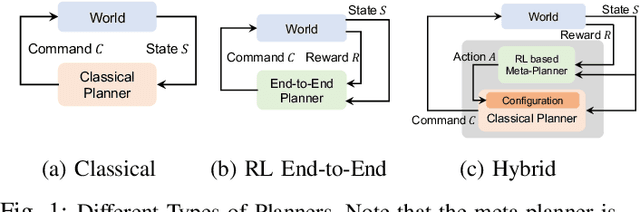



Robot navigation is increasingly crucial across applications like delivery services and warehouse management. The integration of Reinforcement Learning (RL) with classical planning has given rise to meta-planners that combine the adaptability of RL with the explainable decision-making of classical planners. However, the exploration capabilities of RL-based meta-planners during training are often constrained by the capabilities of the underlying classical planners. This constraint can result in limited exploration, thereby leading to sampling skew issues. To address these issues, our paper introduces a novel framework, DIGIMON, which begins with behavior-guided diagnosis for exploration bottlenecks within the meta-planner and follows up with a mitigation strategy that conducts up-sampling from diagnosed bottleneck data. Our evaluation shows 13.5%+ improvement in navigation performance, greater robustness in out-of-distribution environments, and a 4x boost in training efficiency. DIGIMON is designed as a versatile, plug-and-play solution, allowing seamless integration into various RL-based meta-planners.
DERA: Dense Entity Retrieval for Entity Alignment in Knowledge Graphs
Aug 02, 2024



Entity Alignment (EA) aims to match equivalent entities in different Knowledge Graphs (KGs), which is essential for knowledge fusion and integration. Recently, embedding-based EA has attracted significant attention and many approaches have been proposed. Early approaches primarily focus on learning entity embeddings from the structural features of KGs, defined by relation triples. Later methods incorporated entities' names and attributes as auxiliary information to enhance embeddings for EA. However, these approaches often used different techniques to encode structural and attribute information, limiting their interaction and mutual enhancement. In this work, we propose a dense entity retrieval framework for EA, leveraging language models to uniformly encode various features of entities and facilitate nearest entity search across KGs. Alignment candidates are first generated through entity retrieval, which are subsequently reranked to determine the final alignments. We conduct comprehensive experiments on both cross-lingual and monolingual EA datasets, demonstrating that our approach achieves state-of-the-art performance compared to existing EA methods.