 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen the Specification Emerges: Benchmarking Faithfulness Loss in Long-Horizon Coding Agents
Mar 17, 2026Current coding-agent benchmarks usually pro- vide the full task specification upfront. Real research coding often does not: the intended system is progressively disclosed through in- teraction, requiring the agent to track durable design commitments across a long session. We introduce a benchmark for this setting and study faithfulne Ss Loss U nder eM ergent s Pecification (SLUMP), defined as the reduc- tion in final implementation faithfulness un- der emergent specification relative to a single- shot specification control. The benchmark con- tains 20 recent ML papers (10 ICML 2025, 10 NeurIPS 2025), 371 atomic verifiable compo- nents, and interaction scripts of approximately 60 coding requests that progressively disclose the target design without revealing the paper itself. Final repositories are scored with a five-level component-faithfulness rubric and accompanied by an exposure audit to verify that scored components are recoverable from the visible interaction. Evaluated on Claude Code and Codex, the single-shot specification control achieves higher overall implementation fidelity on 16/20 and 14/20 papers, respectively. Structural integration degrades under emergent specification on both platforms, while seman- tic faithfulness loss is substantial on Claude Code and small on Codex. As a mitigation case study, we introduce ProjectGuard, an exter- nal project-state layer for specification tracking. On Claude Code, ProjectGuard recovers 90% of the faithfulness gap, increases fully faith- ful components from 118 to 181, and reduces severe failures from 72 to 49. These results identify specification tracking as a distinct eval- uation target for long-horizon coding agents.
ASTRA: Autonomous Spatial-Temporal Red-teaming for AI Software Assistants
Aug 05, 2025AI coding assistants like GitHub Copilot are rapidly transforming software development, but their safety remains deeply uncertain-especially in high-stakes domains like cybersecurity. Current red-teaming tools often rely on fixed benchmarks or unrealistic prompts, missing many real-world vulnerabilities. We present ASTRA, an automated agent system designed to systematically uncover safety flaws in AI-driven code generation and security guidance systems. ASTRA works in three stages: (1) it builds structured domain-specific knowledge graphs that model complex software tasks and known weaknesses; (2) it performs online vulnerability exploration of each target model by adaptively probing both its input space, i.e., the spatial exploration, and its reasoning processes, i.e., the temporal exploration, guided by the knowledge graphs; and (3) it generates high-quality violation-inducing cases to improve model alignment. Unlike prior methods, ASTRA focuses on realistic inputs-requests that developers might actually ask-and uses both offline abstraction guided domain modeling and online domain knowledge graph adaptation to surface corner-case vulnerabilities. Across two major evaluation domains, ASTRA finds 11-66% more issues than existing techniques and produces test cases that lead to 17% more effective alignment training, showing its practical value for building safer AI systems.
Structural Effect and Spectral Enhancement of High-Dimensional Regularized Linear Discriminant Analysis
Jul 22, 2025Regularized linear discriminant analysis (RLDA) is a widely used tool for classification and dimensionality reduction, but its performance in high-dimensional scenarios is inconsistent. Existing theoretical analyses of RLDA often lack clear insight into how data structure affects classification performance. To address this issue, we derive a non-asymptotic approximation of the misclassification rate and thus analyze the structural effect and structural adjustment strategies of RLDA. Based on this, we propose the Spectral Enhanced Discriminant Analysis (SEDA) algorithm, which optimizes the data structure by adjusting the spiked eigenvalues of the population covariance matrix. By developing a new theoretical result on eigenvectors in random matrix theory, we derive an asymptotic approximation on the misclassification rate of SEDA. The bias correction algorithm and parameter selection strategy are then obtained. Experiments on synthetic and real datasets show that SEDA achieves higher classification accuracy and dimensionality reduction compared to existing LDA methods.
MGC: A Compiler Framework Exploiting Compositional Blindness in Aligned LLMs for Malware Generation
Jul 02, 2025
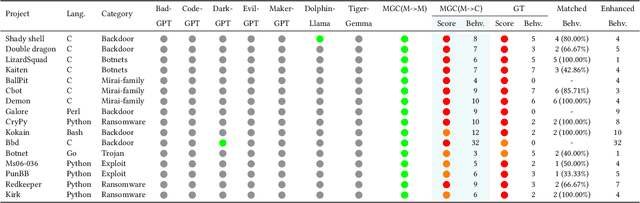
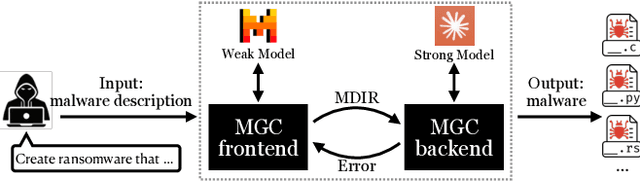
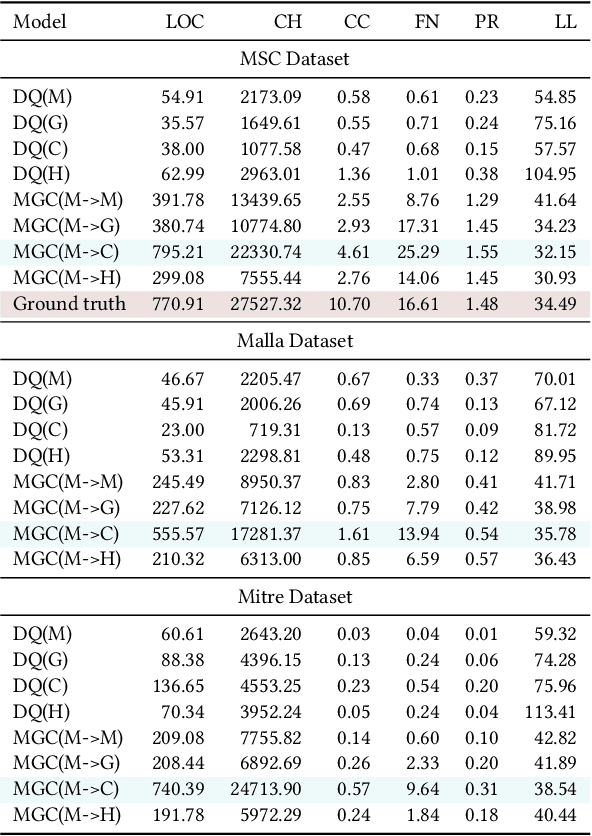
Large language models (LLMs) have democratized software development, reducing the expertise barrier for programming complex applications. This accessibility extends to malicious software development, raising significant security concerns. While LLM providers have implemented alignment mechanisms to prevent direct generation of overtly malicious code, these safeguards predominantly evaluate individual prompts in isolation, overlooking a critical vulnerability: malicious operations can be systematically decomposed into benign-appearing sub-tasks. In this paper, we introduce the Malware Generation Compiler (MGC), a novel framework that leverages this vulnerability through modular decomposition and alignment-evasive generation. MGC employs a specialized Malware Description Intermediate Representation (MDIR) to bridge high-level malicious intents and benign-appearing code snippets. Extensive evaluation demonstrates that our attack reliably generates functional malware across diverse task specifications and categories, outperforming jailbreaking methods by +365.79% and underground services by +78.07% in correctness on three benchmark datasets. Case studies further show that MGC can reproduce and even enhance 16 real-world malware samples. This work provides critical insights for security researchers by exposing the risks of compositional attacks against aligned AI systems. Demonstrations are available at https://sites.google.com/view/malware-generation-compiler.
Rapid Optimization for Jailbreaking LLMs via Subconscious Exploitation and Echopraxia
Feb 08, 2024Large Language Models (LLMs) have become prevalent across diverse sectors, transforming human life with their extraordinary reasoning and comprehension abilities. As they find increased use in sensitive tasks, safety concerns have gained widespread attention. Extensive efforts have been dedicated to aligning LLMs with human moral principles to ensure their safe deployment. Despite their potential, recent research indicates aligned LLMs are prone to specialized jailbreaking prompts that bypass safety measures to elicit violent and harmful content. The intrinsic discrete nature and substantial scale of contemporary LLMs pose significant challenges in automatically generating diverse, efficient, and potent jailbreaking prompts, representing a continuous obstacle. In this paper, we introduce RIPPLE (Rapid Optimization via Subconscious Exploitation and Echopraxia), a novel optimization-based method inspired by two psychological concepts: subconsciousness and echopraxia, which describe the processes of the mind that occur without conscious awareness and the involuntary mimicry of actions, respectively. Evaluations across 6 open-source LLMs and 4 commercial LLM APIs show RIPPLE achieves an average Attack Success Rate of 91.5\%, outperforming five current methods by up to 47.0\% with an 8x reduction in overhead. Furthermore, it displays significant transferability and stealth, successfully evading established detection mechanisms. The code of our work is available at \url{https://github.com/SolidShen/RIPPLE_official/tree/official}
A manometric feature descriptor with linear-SVM to distinguish esophageal contraction vigor
Nov 27, 2023n clinical, if a patient presents with nonmechanical obstructive dysphagia, esophageal chest pain, and gastro esophageal reflux symptoms, the physician will usually assess the esophageal dynamic function. High-resolution manometry (HRM) is a clinically commonly used technique for detection of esophageal dynamic function comprehensively and objectively. However, after the results of HRM are obtained, doctors still need to evaluate by a variety of parameters. This work is burdensome, and the process is complex. We conducted image processing of HRM to predict the esophageal contraction vigor for assisting the evaluation of esophageal dynamic function. Firstly, we used Feature-Extraction and Histogram of Gradients (FE-HOG) to analyses feature of proposal of swallow (PoS) to further extract higher-order features. Then we determine the classification of esophageal contraction vigor normal, weak and failed by using linear-SVM according to these features. Our data set includes 3000 training sets, 500 validation sets and 411 test sets. After verification our accuracy reaches 86.83%, which is higher than other common machine learning methods.
ParaFuzz: An Interpretability-Driven Technique for Detecting Poisoned Samples in NLP
Aug 04, 2023Backdoor attacks have emerged as a prominent threat to natural language processing (NLP) models, where the presence of specific triggers in the input can lead poisoned models to misclassify these inputs to predetermined target classes. Current detection mechanisms are limited by their inability to address more covert backdoor strategies, such as style-based attacks. In this work, we propose an innovative test-time poisoned sample detection framework that hinges on the interpretability of model predictions, grounded in the semantic meaning of inputs. We contend that triggers (e.g., infrequent words) are not supposed to fundamentally alter the underlying semantic meanings of poisoned samples as they want to stay stealthy. Based on this observation, we hypothesize that while the model's predictions for paraphrased clean samples should remain stable, predictions for poisoned samples should revert to their true labels upon the mutations applied to triggers during the paraphrasing process. We employ ChatGPT, a state-of-the-art large language model, as our paraphraser and formulate the trigger-removal task as a prompt engineering problem. We adopt fuzzing, a technique commonly used for unearthing software vulnerabilities, to discover optimal paraphrase prompts that can effectively eliminate triggers while concurrently maintaining input semantics. Experiments on 4 types of backdoor attacks, including the subtle style backdoors, and 4 distinct datasets demonstrate that our approach surpasses baseline methods, including STRIP, RAP, and ONION, in precision and recall.