 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMGC: A Compiler Framework Exploiting Compositional Blindness in Aligned LLMs for Malware Generation
Jul 02, 2025
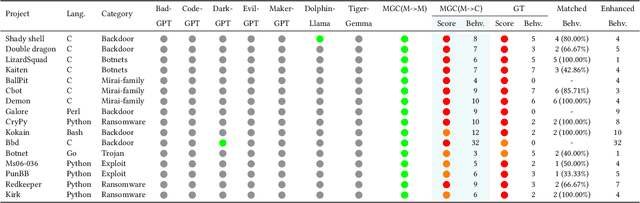
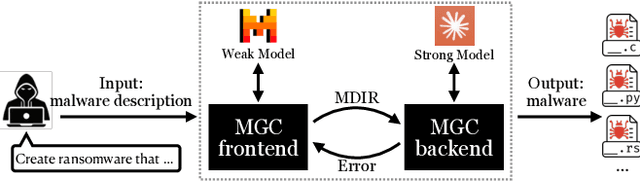
Large language models (LLMs) have democratized software development, reducing the expertise barrier for programming complex applications. This accessibility extends to malicious software development, raising significant security concerns. While LLM providers have implemented alignment mechanisms to prevent direct generation of overtly malicious code, these safeguards predominantly evaluate individual prompts in isolation, overlooking a critical vulnerability: malicious operations can be systematically decomposed into benign-appearing sub-tasks. In this paper, we introduce the Malware Generation Compiler (MGC), a novel framework that leverages this vulnerability through modular decomposition and alignment-evasive generation. MGC employs a specialized Malware Description Intermediate Representation (MDIR) to bridge high-level malicious intents and benign-appearing code snippets. Extensive evaluation demonstrates that our attack reliably generates functional malware across diverse task specifications and categories, outperforming jailbreaking methods by +365.79% and underground services by +78.07% in correctness on three benchmark datasets. Case studies further show that MGC can reproduce and even enhance 16 real-world malware samples. This work provides critical insights for security researchers by exposing the risks of compositional attacks against aligned AI systems. Demonstrations are available at https://sites.google.com/view/malware-generation-compiler.
SOFT: Selective Data Obfuscation for Protecting LLM Fine-tuning against Membership Inference Attacks
Jun 12, 2025



Large language models (LLMs) have achieved remarkable success and are widely adopted for diverse applications. However, fine-tuning these models often involves private or sensitive information, raising critical privacy concerns. In this work, we conduct the first comprehensive study evaluating the vulnerability of fine-tuned LLMs to membership inference attacks (MIAs). Our empirical analysis demonstrates that MIAs exploit the loss reduction during fine-tuning, making them highly effective in revealing membership information. These findings motivate the development of our defense. We propose SOFT (\textbf{S}elective data \textbf{O}bfuscation in LLM \textbf{F}ine-\textbf{T}uning), a novel defense technique that mitigates privacy leakage by leveraging influential data selection with an adjustable parameter to balance utility preservation and privacy protection. Our extensive experiments span six diverse domains and multiple LLM architectures and scales. Results show that SOFT effectively reduces privacy risks while maintaining competitive model performance, offering a practical and scalable solution to safeguard sensitive information in fine-tuned LLMs.
CENSOR: Defense Against Gradient Inversion via Orthogonal Subspace Bayesian Sampling
Jan 27, 2025



Federated learning collaboratively trains a neural network on a global server, where each local client receives the current global model weights and sends back parameter updates (gradients) based on its local private data. The process of sending these model updates may leak client's private data information. Existing gradient inversion attacks can exploit this vulnerability to recover private training instances from a client's gradient vectors. Recently, researchers have proposed advanced gradient inversion techniques that existing defenses struggle to handle effectively. In this work, we present a novel defense tailored for large neural network models. Our defense capitalizes on the high dimensionality of the model parameters to perturb gradients within a subspace orthogonal to the original gradient. By leveraging cold posteriors over orthogonal subspaces, our defense implements a refined gradient update mechanism. This enables the selection of an optimal gradient that not only safeguards against gradient inversion attacks but also maintains model utility. We conduct comprehensive experiments across three different datasets and evaluate our defense against various state-of-the-art attacks and defenses. Code is available at https://censor-gradient.github.io.
UNIT: Backdoor Mitigation via Automated Neural Distribution Tightening
Jul 16, 2024



Deep neural networks (DNNs) have demonstrated effectiveness in various fields. However, DNNs are vulnerable to backdoor attacks, which inject a unique pattern, called trigger, into the input to cause misclassification to an attack-chosen target label. While existing works have proposed various methods to mitigate backdoor effects in poisoned models, they tend to be less effective against recent advanced attacks. In this paper, we introduce a novel post-training defense technique UNIT that can effectively eliminate backdoor effects for a variety of attacks. In specific, UNIT approximates a unique and tight activation distribution for each neuron in the model. It then proactively dispels substantially large activation values that exceed the approximated boundaries. Our experimental results demonstrate that UNIT outperforms 7 popular defense methods against 14 existing backdoor attacks, including 2 advanced attacks, using only 5\% of clean training data. UNIT is also cost efficient. The code is accessible at https://github.com/Megum1/UNIT.
LOTUS: Evasive and Resilient Backdoor Attacks through Sub-Partitioning
Mar 25, 2024



Backdoor attack poses a significant security threat to Deep Learning applications. Existing attacks are often not evasive to established backdoor detection techniques. This susceptibility primarily stems from the fact that these attacks typically leverage a universal trigger pattern or transformation function, such that the trigger can cause misclassification for any input. In response to this, recent papers have introduced attacks using sample-specific invisible triggers crafted through special transformation functions. While these approaches manage to evade detection to some extent, they reveal vulnerability to existing backdoor mitigation techniques. To address and enhance both evasiveness and resilience, we introduce a novel backdoor attack LOTUS. Specifically, it leverages a secret function to separate samples in the victim class into a set of partitions and applies unique triggers to different partitions. Furthermore, LOTUS incorporates an effective trigger focusing mechanism, ensuring only the trigger corresponding to the partition can induce the backdoor behavior. Extensive experimental results show that LOTUS can achieve high attack success rate across 4 datasets and 7 model structures, and effectively evading 13 backdoor detection and mitigation techniques. The code is available at https://github.com/Megum1/LOTUS.
Rapid Optimization for Jailbreaking LLMs via Subconscious Exploitation and Echopraxia
Feb 08, 2024Large Language Models (LLMs) have become prevalent across diverse sectors, transforming human life with their extraordinary reasoning and comprehension abilities. As they find increased use in sensitive tasks, safety concerns have gained widespread attention. Extensive efforts have been dedicated to aligning LLMs with human moral principles to ensure their safe deployment. Despite their potential, recent research indicates aligned LLMs are prone to specialized jailbreaking prompts that bypass safety measures to elicit violent and harmful content. The intrinsic discrete nature and substantial scale of contemporary LLMs pose significant challenges in automatically generating diverse, efficient, and potent jailbreaking prompts, representing a continuous obstacle. In this paper, we introduce RIPPLE (Rapid Optimization via Subconscious Exploitation and Echopraxia), a novel optimization-based method inspired by two psychological concepts: subconsciousness and echopraxia, which describe the processes of the mind that occur without conscious awareness and the involuntary mimicry of actions, respectively. Evaluations across 6 open-source LLMs and 4 commercial LLM APIs show RIPPLE achieves an average Attack Success Rate of 91.5\%, outperforming five current methods by up to 47.0\% with an 8x reduction in overhead. Furthermore, it displays significant transferability and stealth, successfully evading established detection mechanisms. The code of our work is available at \url{https://github.com/SolidShen/RIPPLE_official/tree/official}
Elijah: Eliminating Backdoors Injected in Diffusion Models via Distribution Shift
Nov 27, 2023Diffusion models (DM) have become state-of-the-art generative models because of their capability to generate high-quality images from noises without adversarial training. However, they are vulnerable to backdoor attacks as reported by recent studies. When a data input (e.g., some Gaussian noise) is stamped with a trigger (e.g., a white patch), the backdoored model always generates the target image (e.g., an improper photo). However, effective defense strategies to mitigate backdoors from DMs are underexplored. To bridge this gap, we propose the first backdoor detection and removal framework for DMs. We evaluate our framework Elijah on hundreds of DMs of 3 types including DDPM, NCSN and LDM, with 13 samplers against 3 existing backdoor attacks. Extensive experiments show that our approach can have close to 100% detection accuracy and reduce the backdoor effects to close to zero without significantly sacrificing the model utility.
BEAGLE: Forensics of Deep Learning Backdoor Attack for Better Defense
Jan 16, 2023
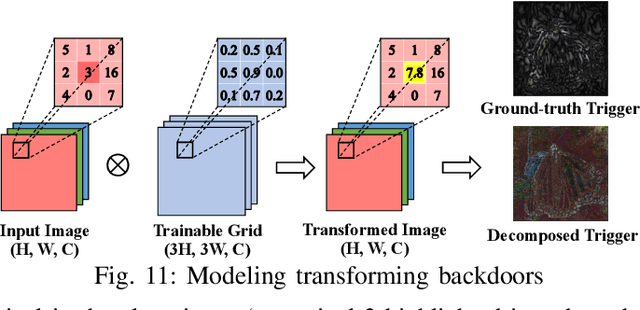
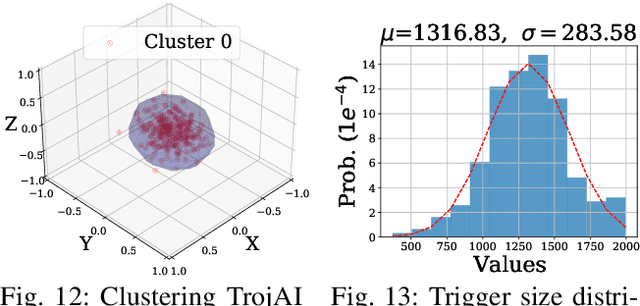
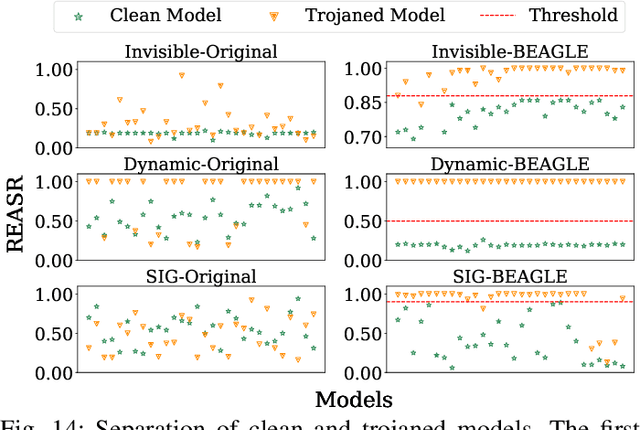
Deep Learning backdoor attacks have a threat model similar to traditional cyber attacks. Attack forensics, a critical counter-measure for traditional cyber attacks, is hence of importance for defending model backdoor attacks. In this paper, we propose a novel model backdoor forensics technique. Given a few attack samples such as inputs with backdoor triggers, which may represent different types of backdoors, our technique automatically decomposes them to clean inputs and the corresponding triggers. It then clusters the triggers based on their properties to allow automatic attack categorization and summarization. Backdoor scanners can then be automatically synthesized to find other instances of the same type of backdoor in other models. Our evaluation on 2,532 pre-trained models, 10 popular attacks, and comparison with 9 baselines show that our technique is highly effective. The decomposed clean inputs and triggers closely resemble the ground truth. The synthesized scanners substantially outperform the vanilla versions of existing scanners that can hardly generalize to different kinds of attacks.
Backdoor Vulnerabilities in Normally Trained Deep Learning Models
Nov 29, 2022

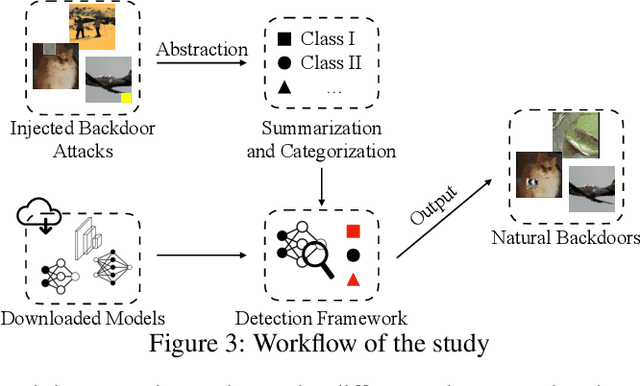
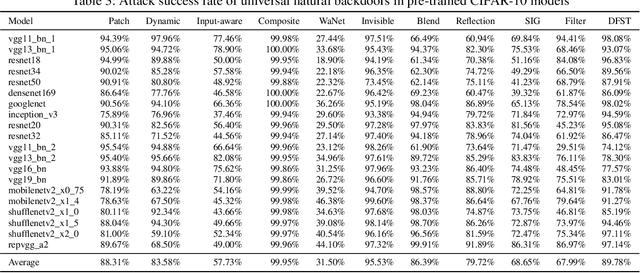
We conduct a systematic study of backdoor vulnerabilities in normally trained Deep Learning models. They are as dangerous as backdoors injected by data poisoning because both can be equally exploited. We leverage 20 different types of injected backdoor attacks in the literature as the guidance and study their correspondences in normally trained models, which we call natural backdoor vulnerabilities. We find that natural backdoors are widely existing, with most injected backdoor attacks having natural correspondences. We categorize these natural backdoors and propose a general detection framework. It finds 315 natural backdoors in the 56 normally trained models downloaded from the Internet, covering all the different categories, while existing scanners designed for injected backdoors can at most detect 65 backdoors. We also study the root causes and defense of natural backdoors.
FLIP: A Provable Defense Framework for Backdoor Mitigation in Federated Learning
Oct 23, 2022

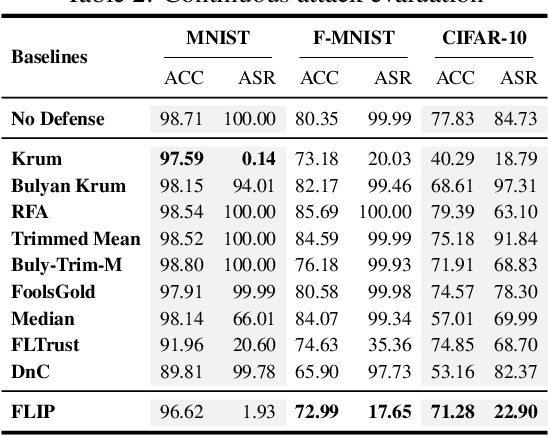

Federated Learning (FL) is a distributed learning paradigm that enables different parties to train a model together for high quality and strong privacy protection. In this scenario, individual participants may get compromised and perform backdoor attacks by poisoning the data (or gradients). Existing work on robust aggregation and certified FL robustness does not study how hardening benign clients can affect the global model (and the malicious clients). In this work, we theoretically analyze the connection among cross-entropy loss, attack success rate, and clean accuracy in this setting. Moreover, we propose a trigger reverse engineering based defense and show that our method can achieve robustness improvement with guarantee (i.e., reducing the attack success rate) without affecting benign accuracy. We conduct comprehensive experiments across different datasets and attack settings. Our results on eight competing SOTA defense methods show the empirical superiority of our method on both single-shot and continuous FL backdoor attacks.