 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDe-amplifying Bias from Differential Privacy in Language Model Fine-tuning
Feb 07, 2024



Fairness and privacy are two important values machine learning (ML) practitioners often seek to operationalize in models. Fairness aims to reduce model bias for social/demographic sub-groups. Privacy via differential privacy (DP) mechanisms, on the other hand, limits the impact of any individual's training data on the resulting model. The trade-offs between privacy and fairness goals of trustworthy ML pose a challenge to those wishing to address both. We show that DP amplifies gender, racial, and religious bias when fine-tuning large language models (LLMs), producing models more biased than ones fine-tuned without DP. We find the cause of the amplification to be a disparity in convergence of gradients across sub-groups. Through the case of binary gender bias, we demonstrate that Counterfactual Data Augmentation (CDA), a known method for addressing bias, also mitigates bias amplification by DP. As a consequence, DP and CDA together can be used to fine-tune models while maintaining both fairness and privacy.
Abstracting Influence Paths for Explaining (Contextualization of) BERT Models
Nov 02, 2020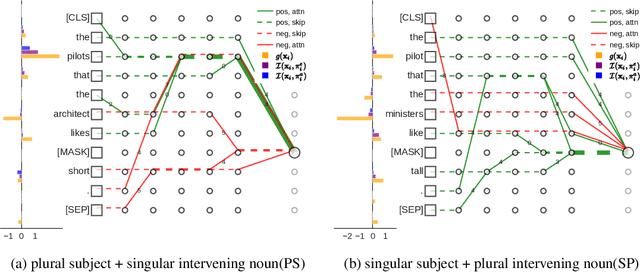
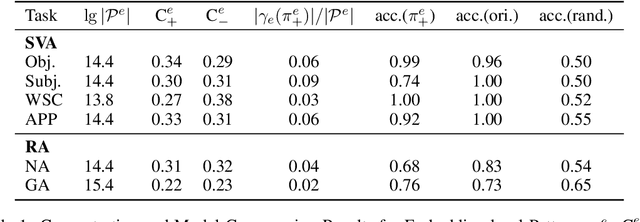
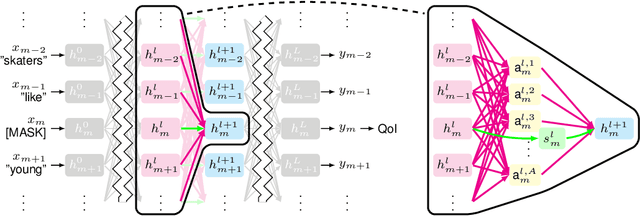
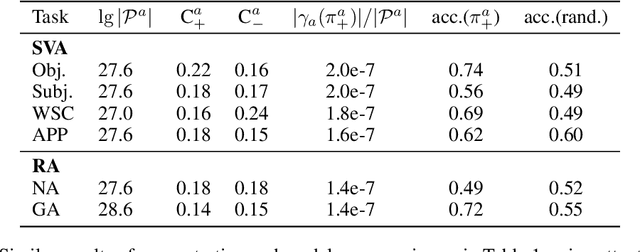
While "attention is all you need" may be proving true, we do not yet know why: attention-based models such as BERT are superior but how they contextualize information even for simple grammatical rules such as subject-verb number agreement (SVA) is uncertain. We introduce multi-partite patterns, abstractions of sets of paths through a neural network model. Patterns quantify and localize the effect of an input concept (e.g., a subject's number) on an output concept (e.g. corresponding verb's number) to paths passing through a sequence of model components, thus surfacing how BERT contextualizes information. We describe guided pattern refinement, an efficient search procedure for finding patterns representative of concept-critical paths. We discover that patterns generate succinct and meaningful explanations for BERT, highlighted by "copy" and "transfer" operations implemented by skip connections and attention heads, respectively. We also show how pattern visualizations help us understand how BERT contextualizes various grammatical concepts, such as SVA across clauses, and why it makes errors in some cases while succeeding in others.
Towards Behavior-Level Explanation for Deep Reinforcement Learning
Sep 17, 2020
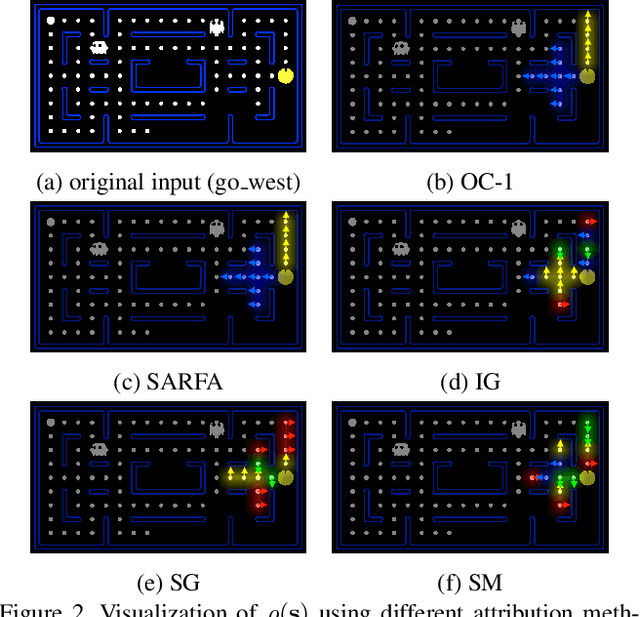
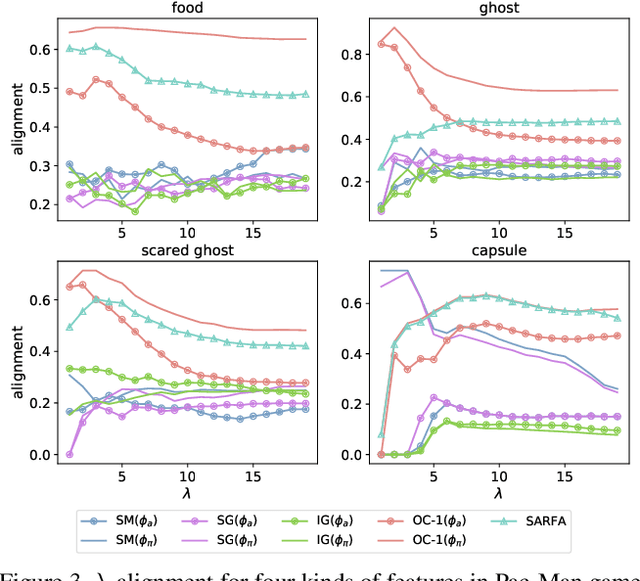
While Deep Neural Networks (DNNs) are becoming the state-of-the-art for many tasks including reinforcement learning (RL), they are especially resistant to human scrutiny and understanding. Input attributions have been a foundational building block for DNN expalainabilty but face new challenges when applied to deep RL. We address the challenges with two novel techniques. We define a class of \emph{behaviour-level attributions} for explaining agent behaviour beyond input importance and interpret existing attribution methods on the behaviour level. We then introduce \emph{$\lambda$-alignment}, a metric for evaluating the performance of behaviour-level attributions methods in terms of whether they are indicative of the agent actions they are meant to explain. Our experiments on Atari games suggest that perturbation-based attribution methods are significantly more suitable to deep RL than alternatives from the perspective of this metric. We argue that our methods demonstrate the minimal set of considerations for adopting general DNN explanation technology to the unique aspects of reinforcement learning and hope the outlined direction can serve as a basis for future research on understanding Deep RL using attribution.
Fairness Under Feature Exemptions: Counterfactual and Observational Measures
Jun 14, 2020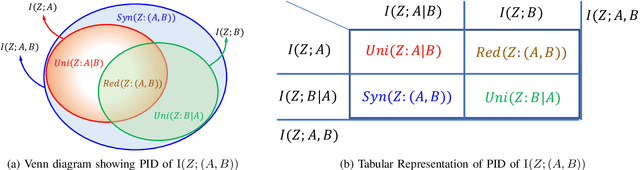
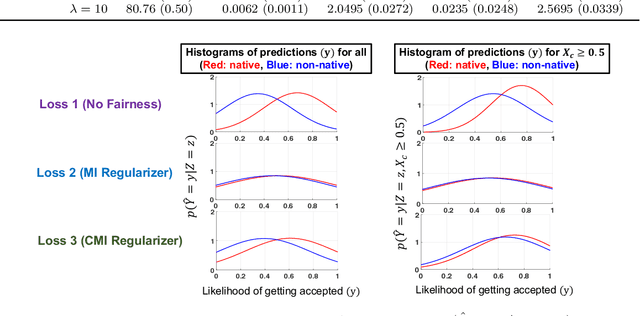
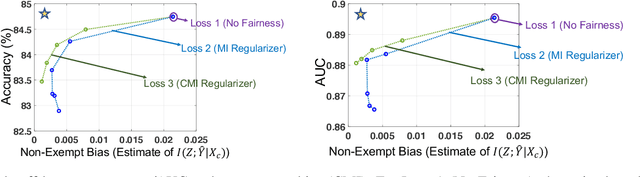
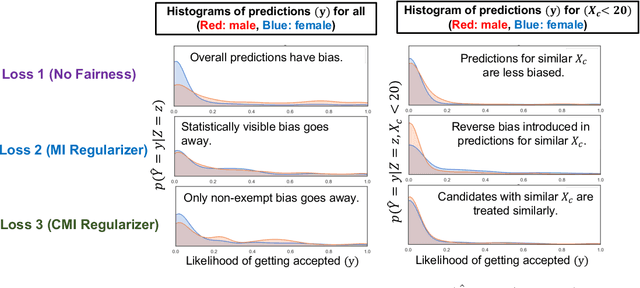
With the growing use of AI in highly consequential domains, the quantification and removal of bias with respect to protected attributes, such as gender, race, etc., is becoming increasingly important. While quantifying bias is essential, sometimes the needs of a business (e.g., hiring) may require the use of certain features that are critical in a way that any bias that can be explained by them might need to be exempted. E.g., a standardized test-score may be a critical feature that should be weighed strongly in hiring even if biased, whereas other features, such as zip code may be used only to the extent that they do not discriminate. In this work, we propose a novel information-theoretic decomposition of the total bias (in a counterfactual sense) into a non-exempt component that quantifies the part of the bias that cannot be accounted for by the critical features, and an exempt component which quantifies the remaining bias. This decomposition allows one to check if the bias arose purely due to the critical features (inspired from the business necessity defense of disparate impact law) and also enables selective removal of the non-exempt component if desired. We arrive at this decomposition through examples that lead to a set of desirable properties (axioms) that any measure of non-exempt bias should satisfy. We demonstrate that our proposed counterfactual measure satisfies all of them. Our quantification bridges ideas of causality, Simpson's paradox, and a body of work from information theory called Partial Information Decomposition. We also obtain an impossibility result showing that no observational measure of non-exempt bias can satisfy all of the desirable properties, which leads us to relax our goals and examine observational measures that satisfy only some of these properties. We then perform case studies to show how one can train models while reducing non-exempt bias.
Smoothed Geometry for Robust Attribution
Jun 11, 2020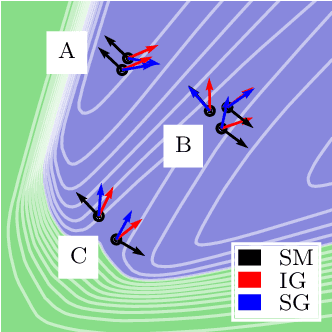
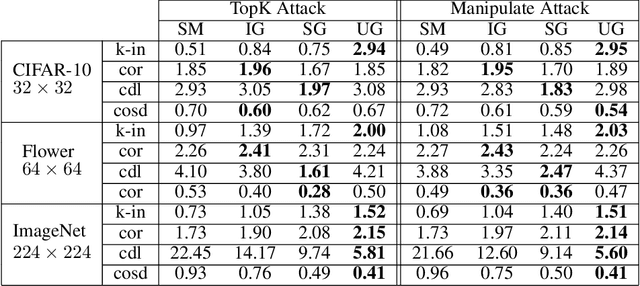
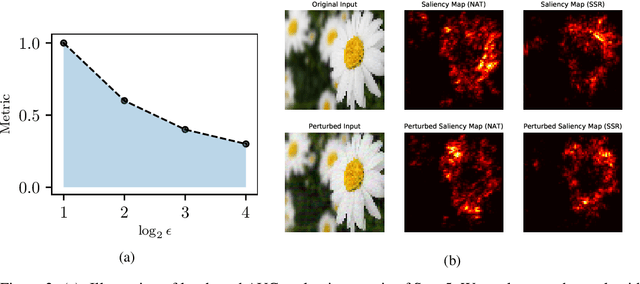
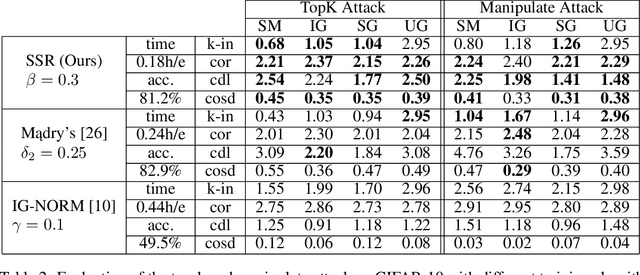
Feature attributions are a popular tool for explaining the behavior of Deep Neural Networks (DNNs), but have recently been shown to be vulnerable to attacks that produce divergent explanations for nearby inputs. This lack of robustness is especially problematic in high-stakes applications where adversarially-manipulated explanations could impair safety and trustworthiness. Building on a geometric understanding of these attacks presented in recent work, we identify Lipschitz continuity conditions on models' gradient that lead to robust gradient-based attributions, and observe that smoothness may also be related to the ability of an attack to transfer across multiple attribution methods. To mitigate these attacks in practice, we propose an inexpensive regularization method that promotes these conditions in DNNs, as well as a stochastic smoothing technique that does not require re-training. Our experiments on a range of image models demonstrate that both of these mitigations consistently improve attribution robustness, and confirm the role that smooth geometry plays in these attacks on real, large-scale models.
Influence Paths for Characterizing Subject-Verb Number Agreement in LSTM Language Models
May 03, 2020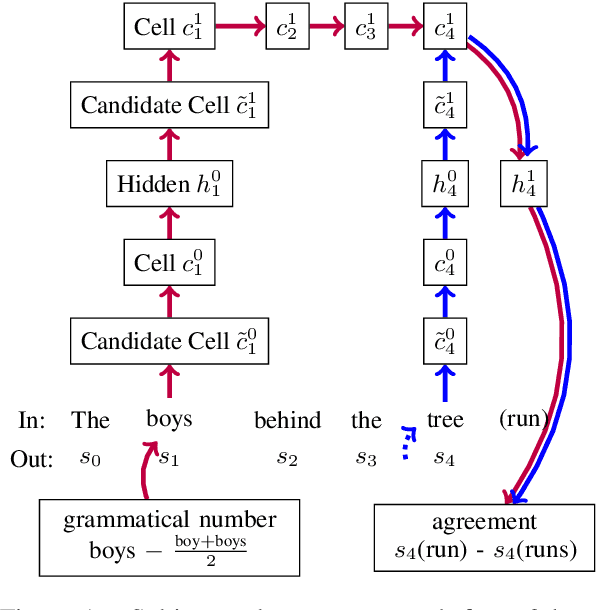
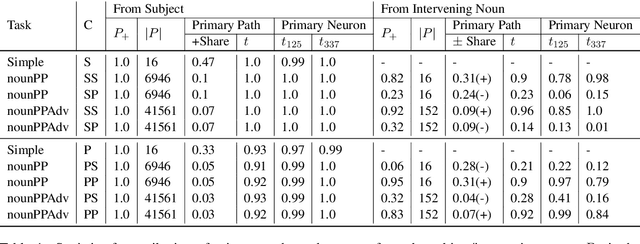
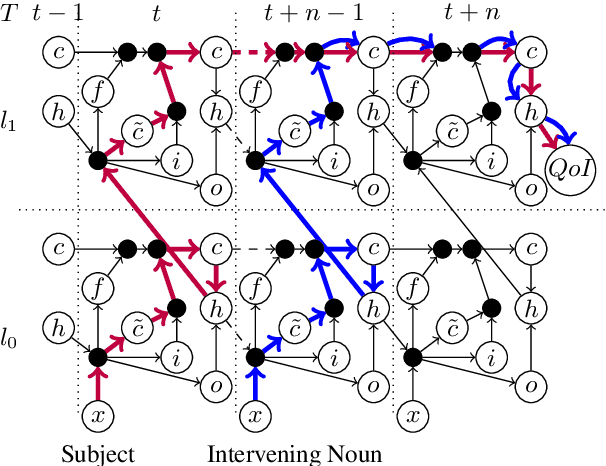
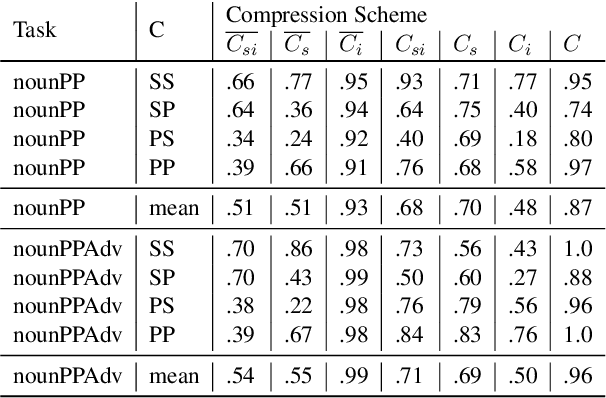
LSTM-based recurrent neural networks are the state-of-the-art for many natural language processing (NLP) tasks. Despite their performance, it is unclear whether, or how, LSTMs learn structural features of natural languages such as subject-verb number agreement in English. Lacking this understanding, the generality of LSTM performance on this task and their suitability for related tasks remains uncertain. Further, errors cannot be properly attributed to a lack of structural capability, training data omissions, or other exceptional faults. We introduce *influence paths*, a causal account of structural properties as carried by paths across gates and neurons of a recurrent neural network. The approach refines the notion of influence (the subject's grammatical number has influence on the grammatical number of the subsequent verb) into a set of gate or neuron-level paths. The set localizes and segments the concept (e.g., subject-verb agreement), its constituent elements (e.g., the subject), and related or interfering elements (e.g., attractors). We exemplify the methodology on a widely-studied multi-layer LSTM language model, demonstrating its accounting for subject-verb number agreement. The results offer both a finer and a more complete view of an LSTM's handling of this structural aspect of the English language than prior results based on diagnostic classifiers and ablation.
Gender Bias in Neural Natural Language Processing
Jul 31, 2018

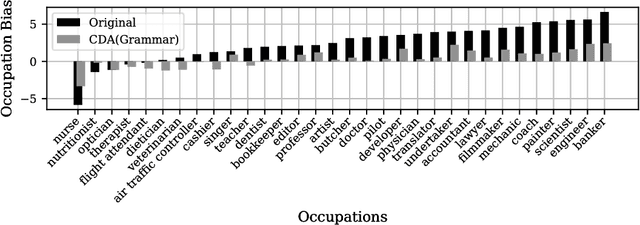
We examine whether neural natural language processing (NLP) systems reflect historical biases in training data. We define a general benchmark to quantify gender bias in a variety of neural NLP tasks. Our empirical evaluation with state-of-the-art neural coreference resolution and textbook RNN-based language models trained on benchmark datasets finds significant gender bias in how models view occupations. We then mitigate bias with CDA: a generic methodology for corpus augmentation via causal interventions that breaks associations between gendered and gender-neutral words. We empirically show that CDA effectively decreases gender bias while preserving accuracy. We also explore the space of mitigation strategies with CDA, a prior approach to word embedding debiasing (WED), and their compositions. We show that CDA outperforms WED, drastically so when word embeddings are trained. For pre-trained embeddings, the two methods can be effectively composed. We also find that as training proceeds on the original data set with gradient descent the gender bias grows as the loss reduces, indicating that the optimization encourages bias; CDA mitigates this behavior.
Supervising Feature Influence
Apr 07, 2018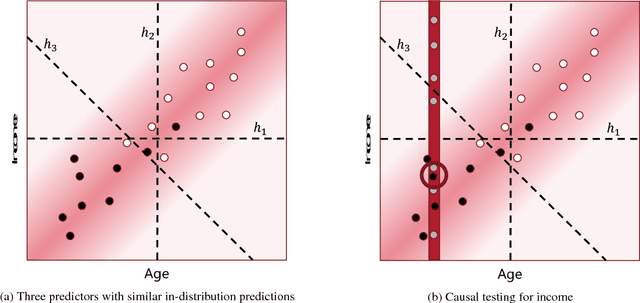
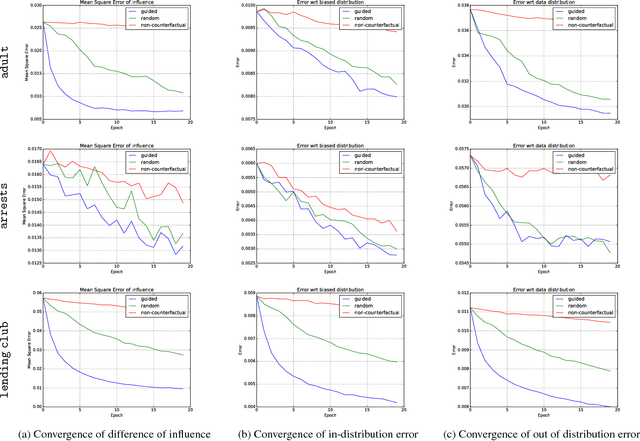
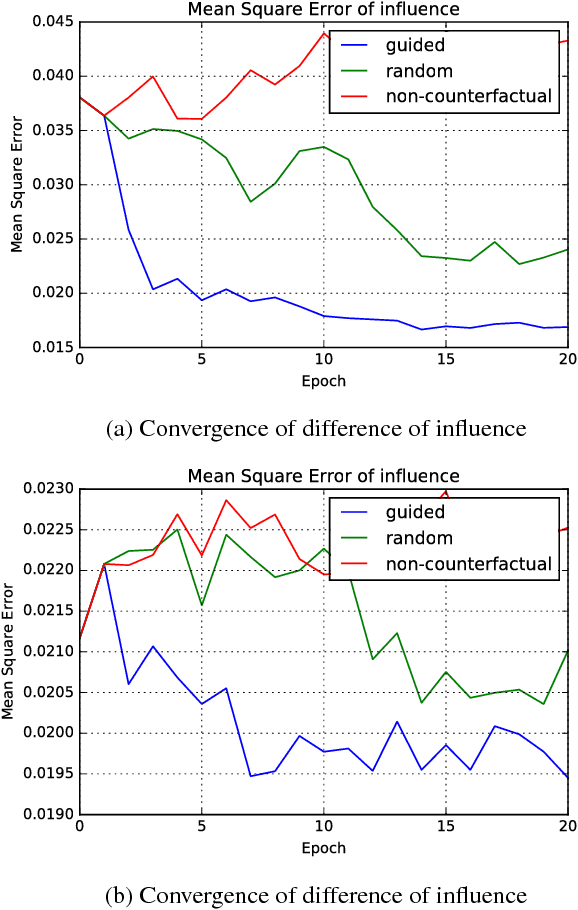
Causal influence measures for machine learnt classifiers shed light on the reasons behind classification, and aid in identifying influential input features and revealing their biases. However, such analyses involve evaluating the classifier using datapoints that may be atypical of its training distribution. Standard methods for training classifiers that minimize empirical risk do not constrain the behavior of the classifier on such datapoints. As a result, training to minimize empirical risk does not distinguish among classifiers that agree on predictions in the training distribution but have wildly different causal influences. We term this problem covariate shift in causal testing and formally characterize conditions under which it arises. As a solution to this problem, we propose a novel active learning algorithm that constrains the influence measures of the trained model. We prove that any two predictors whose errors are close on both the original training distribution and the distribution of atypical points are guaranteed to have causal influences that are also close. Further, we empirically demonstrate with synthetic labelers that our algorithm trains models that (i) have similar causal influences as the labeler's model, and (ii) generalize better to out-of-distribution points while (iii) retaining their accuracy on in-distribution points.
Use Privacy in Data-Driven Systems: Theory and Experiments with Machine Learnt Programs
Sep 07, 2017
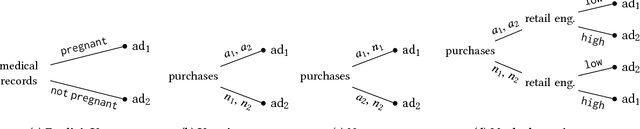


This paper presents an approach to formalizing and enforcing a class of use privacy properties in data-driven systems. In contrast to prior work, we focus on use restrictions on proxies (i.e. strong predictors) of protected information types. Our definition relates proxy use to intermediate computations that occur in a program, and identify two essential properties that characterize this behavior: 1) its result is strongly associated with the protected information type in question, and 2) it is likely to causally affect the final output of the program. For a specific instantiation of this definition, we present a program analysis technique that detects instances of proxy use in a model, and provides a witness that identifies which parts of the corresponding program exhibit the behavior. Recognizing that not all instances of proxy use of a protected information type are inappropriate, we make use of a normative judgment oracle that makes this inappropriateness determination for a given witness. Our repair algorithm uses the witness of an inappropriate proxy use to transform the model into one that provably does not exhibit proxy use, while avoiding changes that unduly affect classification accuracy. Using a corpus of social datasets, our evaluation shows that these algorithms are able to detect proxy use instances that would be difficult to find using existing techniques, and subsequently remove them while maintaining acceptable classification performance.
Proxy Non-Discrimination in Data-Driven Systems
Jul 25, 2017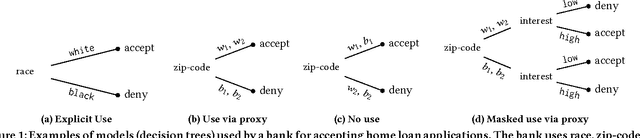

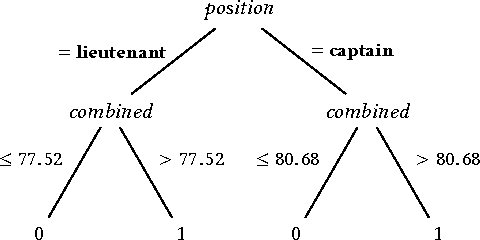
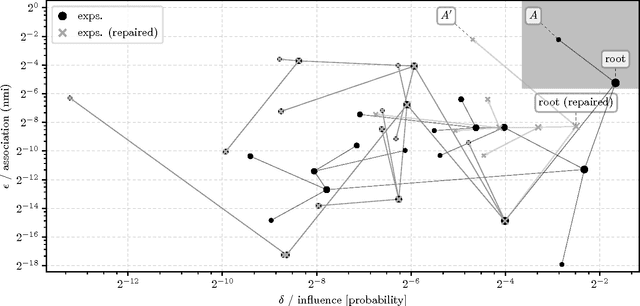
Machine learnt systems inherit biases against protected classes, historically disparaged groups, from training data. Usually, these biases are not explicit, they rely on subtle correlations discovered by training algorithms, and are therefore difficult to detect. We formalize proxy discrimination in data-driven systems, a class of properties indicative of bias, as the presence of protected class correlates that have causal influence on the system's output. We evaluate an implementation on a corpus of social datasets, demonstrating how to validate systems against these properties and to repair violations where they occur.