 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Modulo Theories
Jan 26, 2023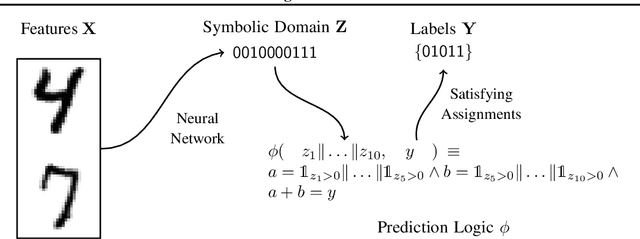
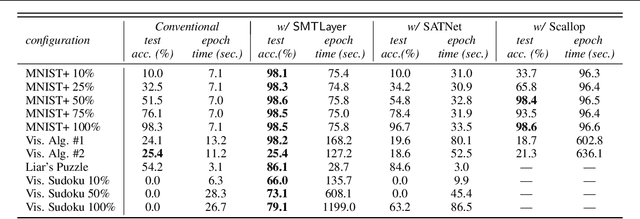
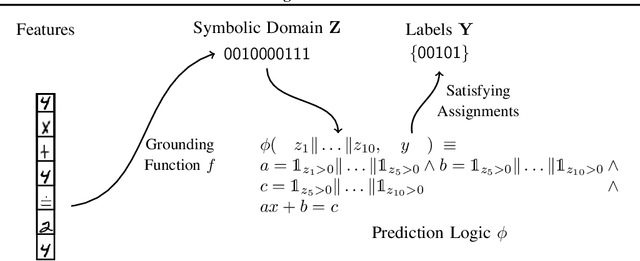
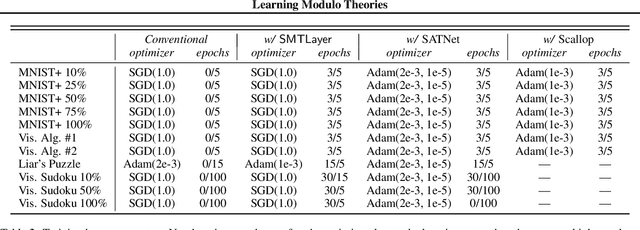
Recent techniques that integrate \emph{solver layers} into Deep Neural Networks (DNNs) have shown promise in bridging a long-standing gap between inductive learning and symbolic reasoning techniques. In this paper we present a set of techniques for integrating \emph{Satisfiability Modulo Theories} (SMT) solvers into the forward and backward passes of a deep network layer, called SMTLayer. Using this approach, one can encode rich domain knowledge into the network in the form of mathematical formulas. In the forward pass, the solver uses symbols produced by prior layers, along with these formulas, to construct inferences; in the backward pass, the solver informs updates to the network, driving it towards representations that are compatible with the solver's theory. Notably, the solver need not be differentiable. We implement \layername as a Pytorch module, and our empirical results show that it leads to models that \emph{1)} require fewer training samples than conventional models, \emph{2)} that are robust to certain types of covariate shift, and \emph{3)} that ultimately learn representations that are consistent with symbolic knowledge, and thus naturally interpretable.
Order-sensitive Shapley Values for Evaluating Conceptual Soundness of NLP Models
Jun 01, 2022

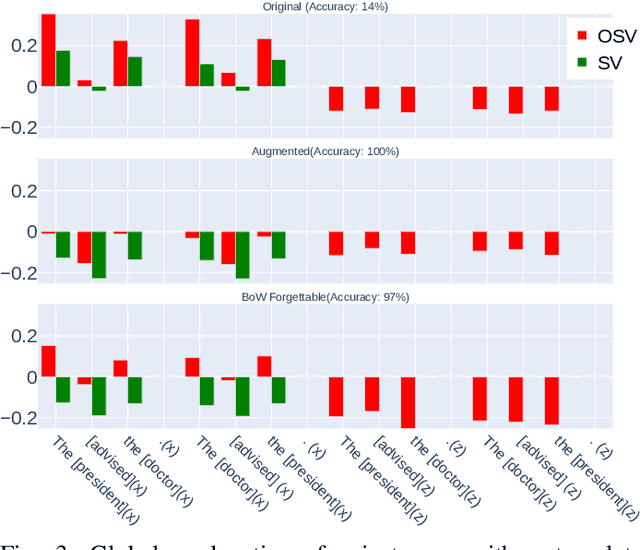
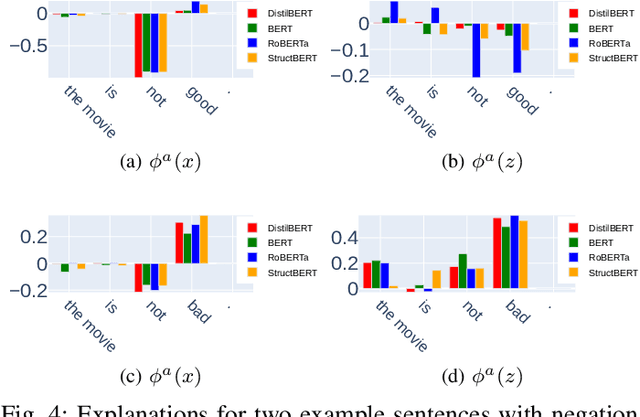
Previous works show that deep NLP models are not always conceptually sound: they do not always learn the correct linguistic concepts. Specifically, they can be insensitive to word order. In order to systematically evaluate models for their conceptual soundness with respect to word order, we introduce a new explanation method for sequential data: Order-sensitive Shapley Values (OSV). We conduct an extensive empirical evaluation to validate the method and surface how well various deep NLP models learn word order. Using synthetic data, we first show that OSV is more faithful in explaining model behavior than gradient-based methods. Second, applying to the HANS dataset, we discover that the BERT-based NLI model uses only the word occurrences without word orders. Although simple data augmentation improves accuracy on HANS, OSV shows that the augmented model does not fundamentally improve the model's learning of order. Third, we discover that not all sentiment analysis models learn negation properly: some fail to capture the correct syntax of the negation construct. Finally, we show that pretrained language models such as BERT may rely on the absolute positions of subject words to learn long-range Subject-Verb Agreement. With each NLP task, we also demonstrate how OSV can be leveraged to generate adversarial examples.
Abstracting Influence Paths for Explaining (Contextualization of) BERT Models
Nov 02, 2020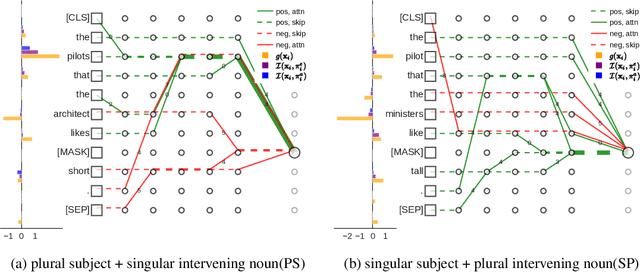
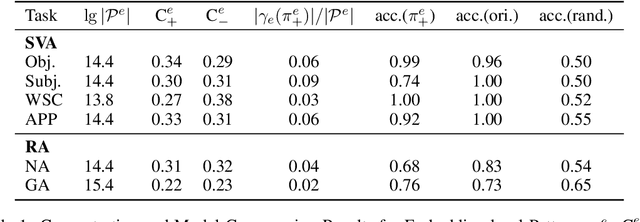
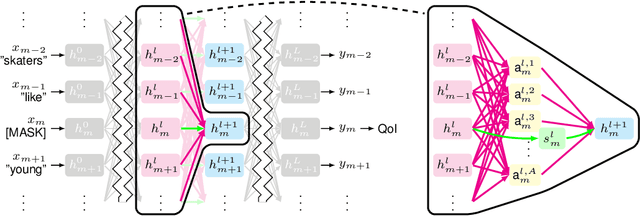
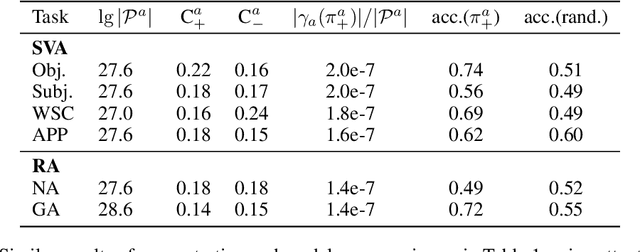
While "attention is all you need" may be proving true, we do not yet know why: attention-based models such as BERT are superior but how they contextualize information even for simple grammatical rules such as subject-verb number agreement (SVA) is uncertain. We introduce multi-partite patterns, abstractions of sets of paths through a neural network model. Patterns quantify and localize the effect of an input concept (e.g., a subject's number) on an output concept (e.g. corresponding verb's number) to paths passing through a sequence of model components, thus surfacing how BERT contextualizes information. We describe guided pattern refinement, an efficient search procedure for finding patterns representative of concept-critical paths. We discover that patterns generate succinct and meaningful explanations for BERT, highlighted by "copy" and "transfer" operations implemented by skip connections and attention heads, respectively. We also show how pattern visualizations help us understand how BERT contextualizes various grammatical concepts, such as SVA across clauses, and why it makes errors in some cases while succeeding in others.
Influence Paths for Characterizing Subject-Verb Number Agreement in LSTM Language Models
May 03, 2020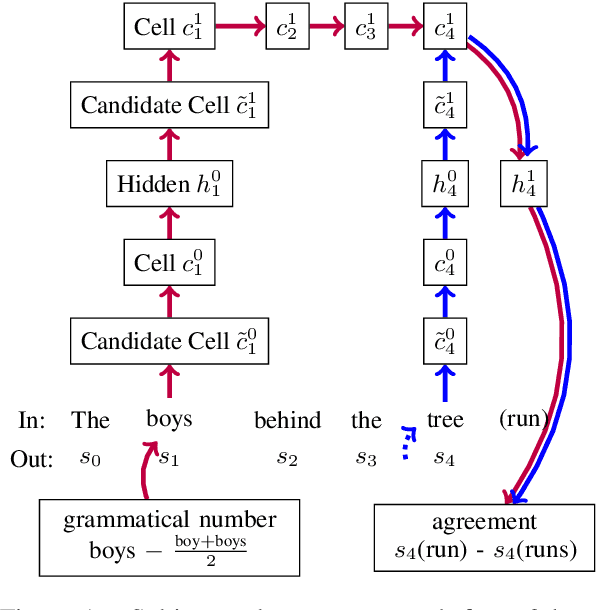
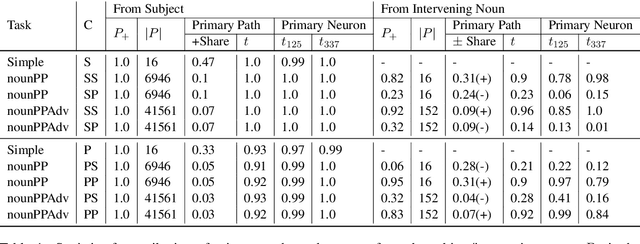
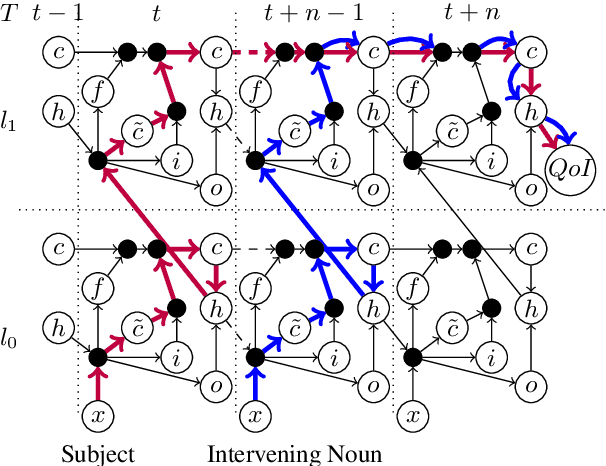
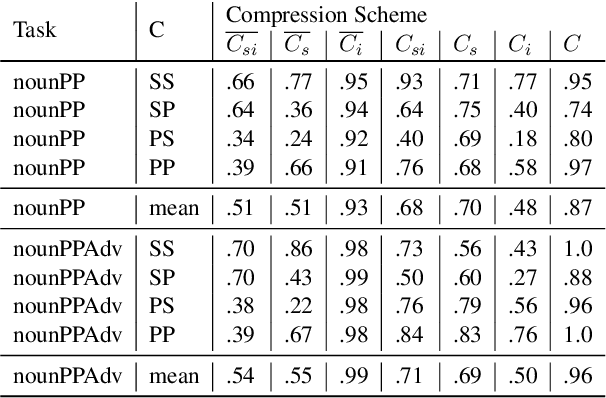
LSTM-based recurrent neural networks are the state-of-the-art for many natural language processing (NLP) tasks. Despite their performance, it is unclear whether, or how, LSTMs learn structural features of natural languages such as subject-verb number agreement in English. Lacking this understanding, the generality of LSTM performance on this task and their suitability for related tasks remains uncertain. Further, errors cannot be properly attributed to a lack of structural capability, training data omissions, or other exceptional faults. We introduce *influence paths*, a causal account of structural properties as carried by paths across gates and neurons of a recurrent neural network. The approach refines the notion of influence (the subject's grammatical number has influence on the grammatical number of the subsequent verb) into a set of gate or neuron-level paths. The set localizes and segments the concept (e.g., subject-verb agreement), its constituent elements (e.g., the subject), and related or interfering elements (e.g., attractors). We exemplify the methodology on a widely-studied multi-layer LSTM language model, demonstrating its accounting for subject-verb number agreement. The results offer both a finer and a more complete view of an LSTM's handling of this structural aspect of the English language than prior results based on diagnostic classifiers and ablation.
Gender Bias in Neural Natural Language Processing
Jul 31, 2018

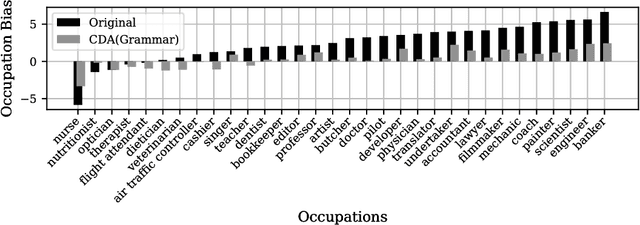
We examine whether neural natural language processing (NLP) systems reflect historical biases in training data. We define a general benchmark to quantify gender bias in a variety of neural NLP tasks. Our empirical evaluation with state-of-the-art neural coreference resolution and textbook RNN-based language models trained on benchmark datasets finds significant gender bias in how models view occupations. We then mitigate bias with CDA: a generic methodology for corpus augmentation via causal interventions that breaks associations between gendered and gender-neutral words. We empirically show that CDA effectively decreases gender bias while preserving accuracy. We also explore the space of mitigation strategies with CDA, a prior approach to word embedding debiasing (WED), and their compositions. We show that CDA outperforms WED, drastically so when word embeddings are trained. For pre-trained embeddings, the two methods can be effectively composed. We also find that as training proceeds on the original data set with gradient descent the gender bias grows as the loss reduces, indicating that the optimization encourages bias; CDA mitigates this behavior.