 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrder-sensitive Shapley Values for Evaluating Conceptual Soundness of NLP Models
Paper and Code
Jun 01, 2022

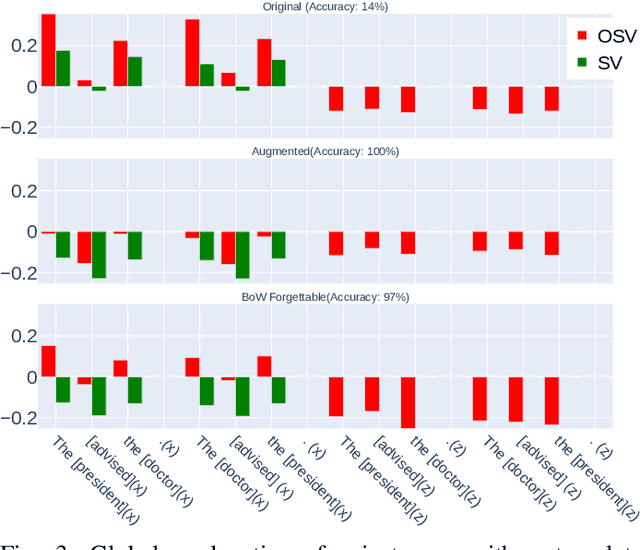
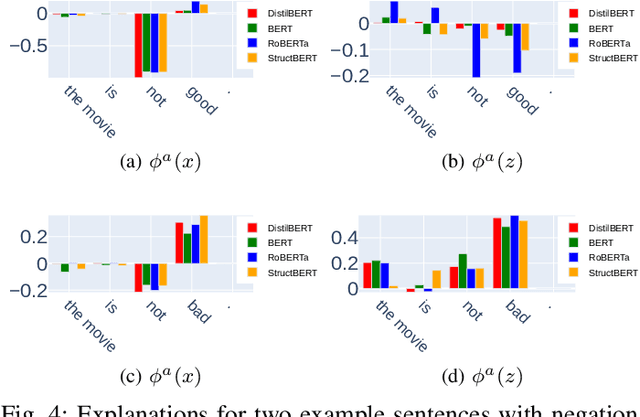
Previous works show that deep NLP models are not always conceptually sound: they do not always learn the correct linguistic concepts. Specifically, they can be insensitive to word order. In order to systematically evaluate models for their conceptual soundness with respect to word order, we introduce a new explanation method for sequential data: Order-sensitive Shapley Values (OSV). We conduct an extensive empirical evaluation to validate the method and surface how well various deep NLP models learn word order. Using synthetic data, we first show that OSV is more faithful in explaining model behavior than gradient-based methods. Second, applying to the HANS dataset, we discover that the BERT-based NLI model uses only the word occurrences without word orders. Although simple data augmentation improves accuracy on HANS, OSV shows that the augmented model does not fundamentally improve the model's learning of order. Third, we discover that not all sentiment analysis models learn negation properly: some fail to capture the correct syntax of the negation construct. Finally, we show that pretrained language models such as BERT may rely on the absolute positions of subject words to learn long-range Subject-Verb Agreement. With each NLP task, we also demonstrate how OSV can be leveraged to generate adversarial examples.