 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervising Feature Influence
Apr 07, 2018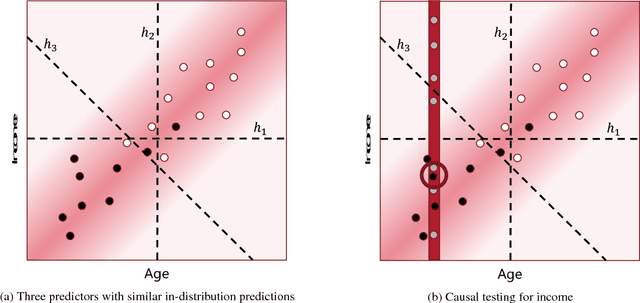
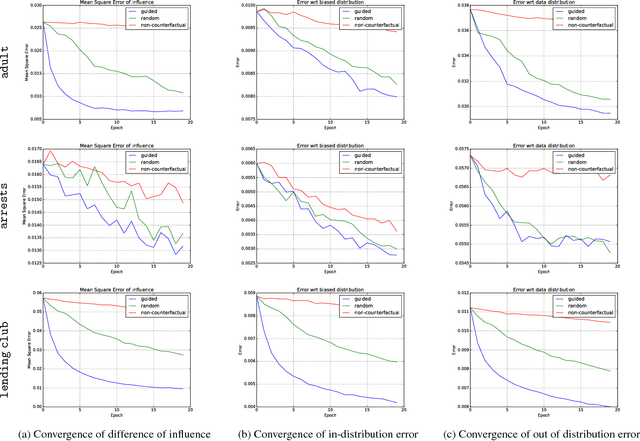
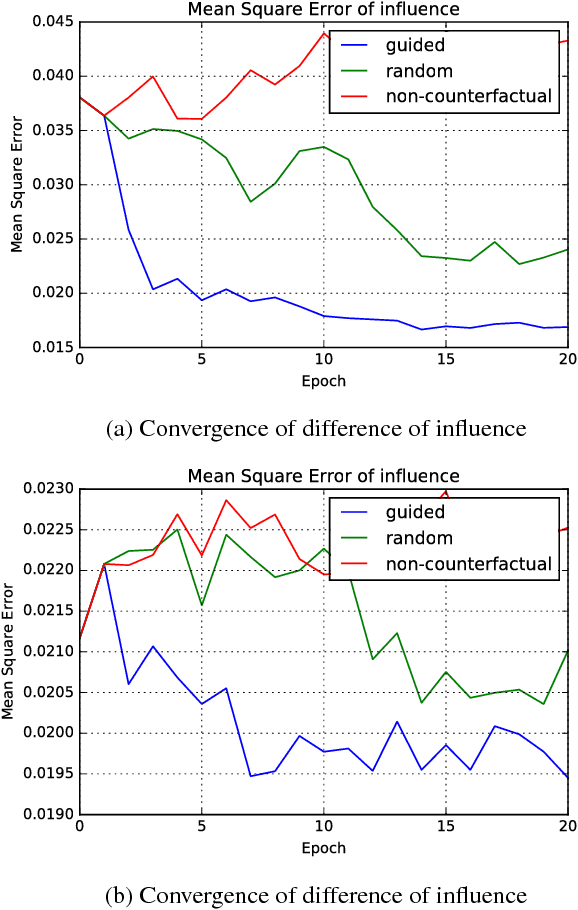
Causal influence measures for machine learnt classifiers shed light on the reasons behind classification, and aid in identifying influential input features and revealing their biases. However, such analyses involve evaluating the classifier using datapoints that may be atypical of its training distribution. Standard methods for training classifiers that minimize empirical risk do not constrain the behavior of the classifier on such datapoints. As a result, training to minimize empirical risk does not distinguish among classifiers that agree on predictions in the training distribution but have wildly different causal influences. We term this problem covariate shift in causal testing and formally characterize conditions under which it arises. As a solution to this problem, we propose a novel active learning algorithm that constrains the influence measures of the trained model. We prove that any two predictors whose errors are close on both the original training distribution and the distribution of atypical points are guaranteed to have causal influences that are also close. Further, we empirically demonstrate with synthetic labelers that our algorithm trains models that (i) have similar causal influences as the labeler's model, and (ii) generalize better to out-of-distribution points while (iii) retaining their accuracy on in-distribution points.
Use Privacy in Data-Driven Systems: Theory and Experiments with Machine Learnt Programs
Sep 07, 2017
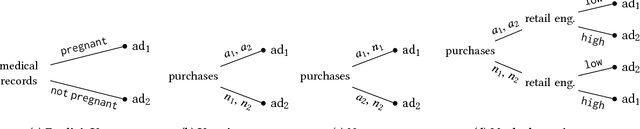


This paper presents an approach to formalizing and enforcing a class of use privacy properties in data-driven systems. In contrast to prior work, we focus on use restrictions on proxies (i.e. strong predictors) of protected information types. Our definition relates proxy use to intermediate computations that occur in a program, and identify two essential properties that characterize this behavior: 1) its result is strongly associated with the protected information type in question, and 2) it is likely to causally affect the final output of the program. For a specific instantiation of this definition, we present a program analysis technique that detects instances of proxy use in a model, and provides a witness that identifies which parts of the corresponding program exhibit the behavior. Recognizing that not all instances of proxy use of a protected information type are inappropriate, we make use of a normative judgment oracle that makes this inappropriateness determination for a given witness. Our repair algorithm uses the witness of an inappropriate proxy use to transform the model into one that provably does not exhibit proxy use, while avoiding changes that unduly affect classification accuracy. Using a corpus of social datasets, our evaluation shows that these algorithms are able to detect proxy use instances that would be difficult to find using existing techniques, and subsequently remove them while maintaining acceptable classification performance.
Revisiting Differentially Private Regression: Lessons From Learning Theory and their Consequences
Dec 20, 2015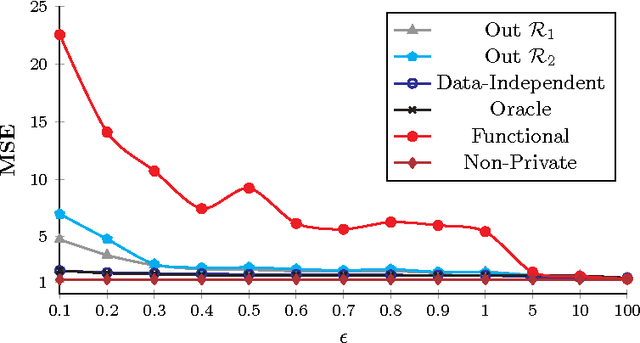
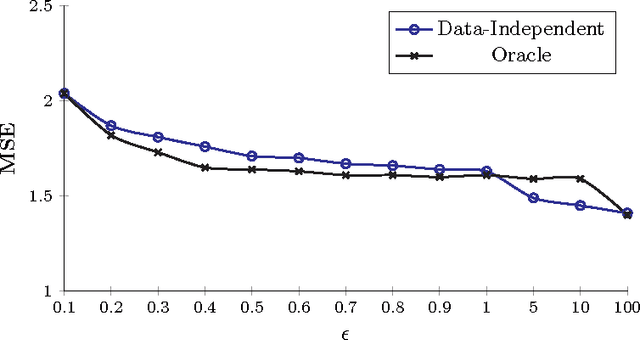


Private regression has received attention from both database and security communities. Recent work by Fredrikson et al. (USENIX Security 2014) analyzed the functional mechanism (Zhang et al. VLDB 2012) for training linear regression models over medical data. Unfortunately, they found that model accuracy is already unacceptable with differential privacy when $\varepsilon = 5$. We address this issue, presenting an explicit connection between differential privacy and stable learning theory through which a substantially better privacy/utility tradeoff can be obtained. Perhaps more importantly, our theory reveals that the most basic mechanism in differential privacy, output perturbation, can be used to obtain a better tradeoff for all convex-Lipschitz-bounded learning tasks. Since output perturbation is simple to implement, it means that our approach is potentially widely applicable in practice. We go on to apply it on the same medical data as used by Fredrikson et al. Encouragingly, we achieve accurate models even for $\varepsilon = 0.1$. In the last part of this paper, we study the impact of our improved differentially private mechanisms on model inversion attacks, a privacy attack introduced by Fredrikson et al. We observe that the improved tradeoff makes the resulting differentially private model more susceptible to inversion attacks. We analyze this phenomenon formally.