 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Differentially Private Regression: Lessons From Learning Theory and their Consequences
Paper and Code
Dec 20, 2015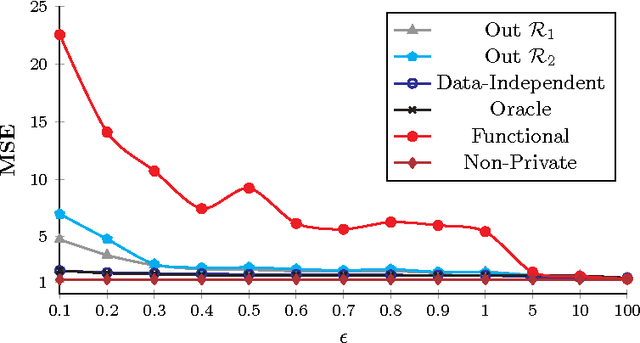
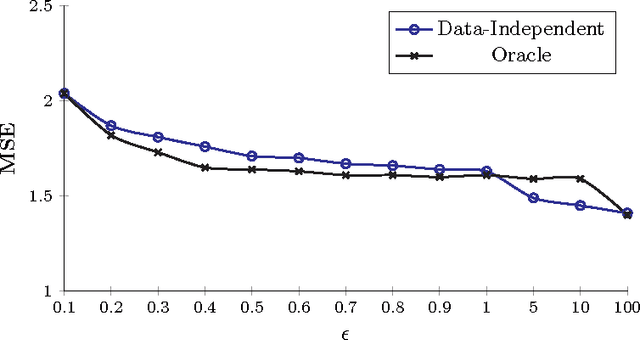


Private regression has received attention from both database and security communities. Recent work by Fredrikson et al. (USENIX Security 2014) analyzed the functional mechanism (Zhang et al. VLDB 2012) for training linear regression models over medical data. Unfortunately, they found that model accuracy is already unacceptable with differential privacy when $\varepsilon = 5$. We address this issue, presenting an explicit connection between differential privacy and stable learning theory through which a substantially better privacy/utility tradeoff can be obtained. Perhaps more importantly, our theory reveals that the most basic mechanism in differential privacy, output perturbation, can be used to obtain a better tradeoff for all convex-Lipschitz-bounded learning tasks. Since output perturbation is simple to implement, it means that our approach is potentially widely applicable in practice. We go on to apply it on the same medical data as used by Fredrikson et al. Encouragingly, we achieve accurate models even for $\varepsilon = 0.1$. In the last part of this paper, we study the impact of our improved differentially private mechanisms on model inversion attacks, a privacy attack introduced by Fredrikson et al. We observe that the improved tradeoff makes the resulting differentially private model more susceptible to inversion attacks. We analyze this phenomenon formally.