 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature-Wise Bias Amplification
Dec 21, 2018
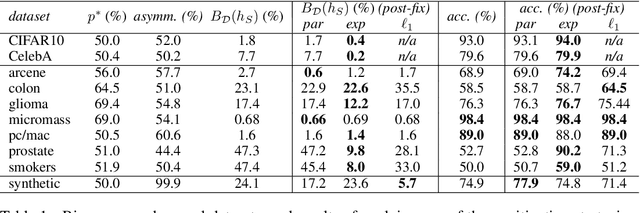
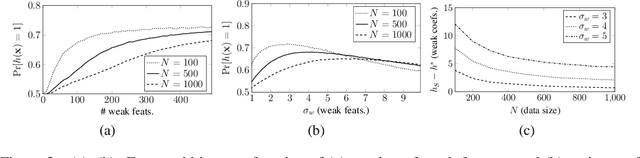
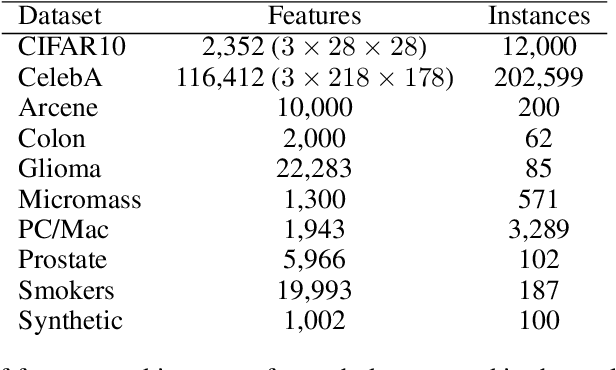
We study the phenomenon of bias amplification in classifiers, wherein a machine learning model learns to predict classes with a greater disparity than the underlying ground truth. We demonstrate that bias amplification can arise via an inductive bias in gradient descent methods that results in the overestimation of the importance of moderately-predictive "weak" features if insufficient training data is available. This overestimation gives rise to feature-wise bias amplification -- a previously unreported form of bias that can be traced back to the features of a trained model. Through analysis and experiments, we show that while some bias cannot be mitigated without sacrificing accuracy, feature-wise bias amplification can be mitigated through targeted feature selection. We present two new feature selection algorithms for mitigating bias amplification in linear models, and show how they can be adapted to convolutional neural networks efficiently. Our experiments on synthetic and real data demonstrate that these algorithms consistently lead to reduced bias without harming accuracy, in some cases eliminating predictive bias altogether while providing modest gains in accuracy.
Supervising Feature Influence
Apr 07, 2018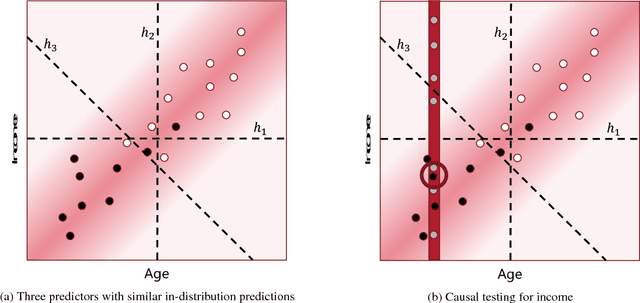
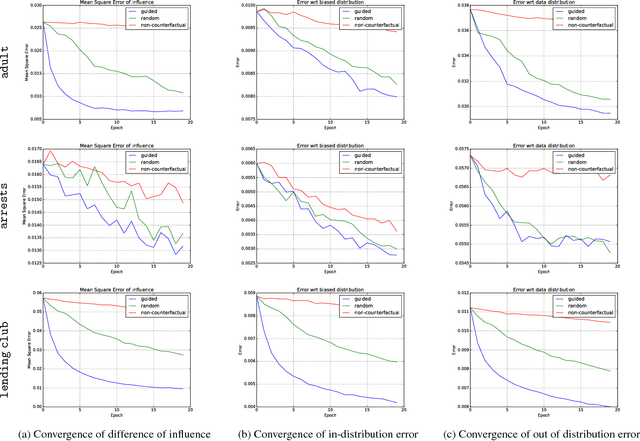
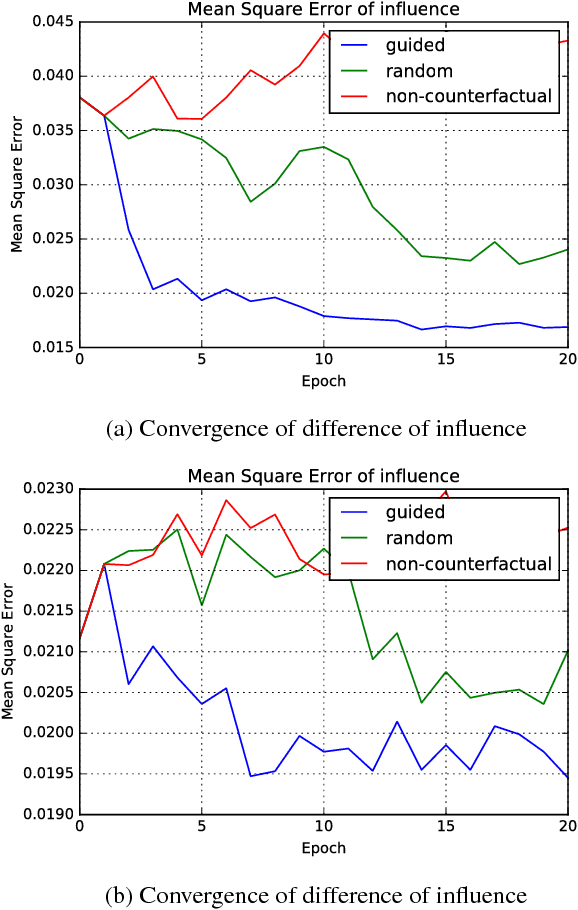
Causal influence measures for machine learnt classifiers shed light on the reasons behind classification, and aid in identifying influential input features and revealing their biases. However, such analyses involve evaluating the classifier using datapoints that may be atypical of its training distribution. Standard methods for training classifiers that minimize empirical risk do not constrain the behavior of the classifier on such datapoints. As a result, training to minimize empirical risk does not distinguish among classifiers that agree on predictions in the training distribution but have wildly different causal influences. We term this problem covariate shift in causal testing and formally characterize conditions under which it arises. As a solution to this problem, we propose a novel active learning algorithm that constrains the influence measures of the trained model. We prove that any two predictors whose errors are close on both the original training distribution and the distribution of atypical points are guaranteed to have causal influences that are also close. Further, we empirically demonstrate with synthetic labelers that our algorithm trains models that (i) have similar causal influences as the labeler's model, and (ii) generalize better to out-of-distribution points while (iii) retaining their accuracy on in-distribution points.
Influence-Directed Explanations for Deep Convolutional Networks
Feb 11, 2018
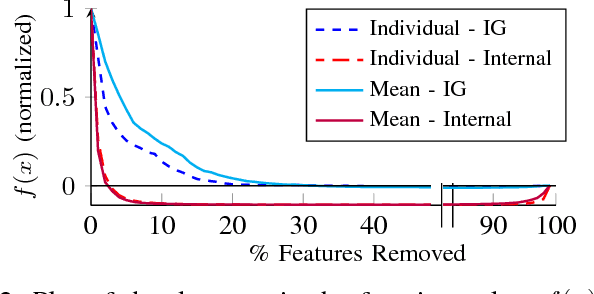


We study the problem of explaining a rich class of behavioral properties of deep neural networks. Distinctively, our influence-directed explanations approach this problem by peering inside the net- work to identify neurons with high influence on the property and distribution of interest using an axiomatically justified influence measure, and then providing an interpretation for the concepts these neurons represent. We evaluate our approach by training convolutional neural net- works on MNIST, ImageNet, Pubfig, and Diabetic Retinopathy datasets. Our evaluation demonstrates that influence-directed explanations (1) identify influential concepts that generalize across instances, (2) help extract the essence of what the network learned about a class, (3) isolate individual features the network uses to make decisions and distinguish related instances, and (4) assist in understanding misclassifications.
Case Study: Explaining Diabetic Retinopathy Detection Deep CNNs via Integrated Gradients
Oct 18, 2017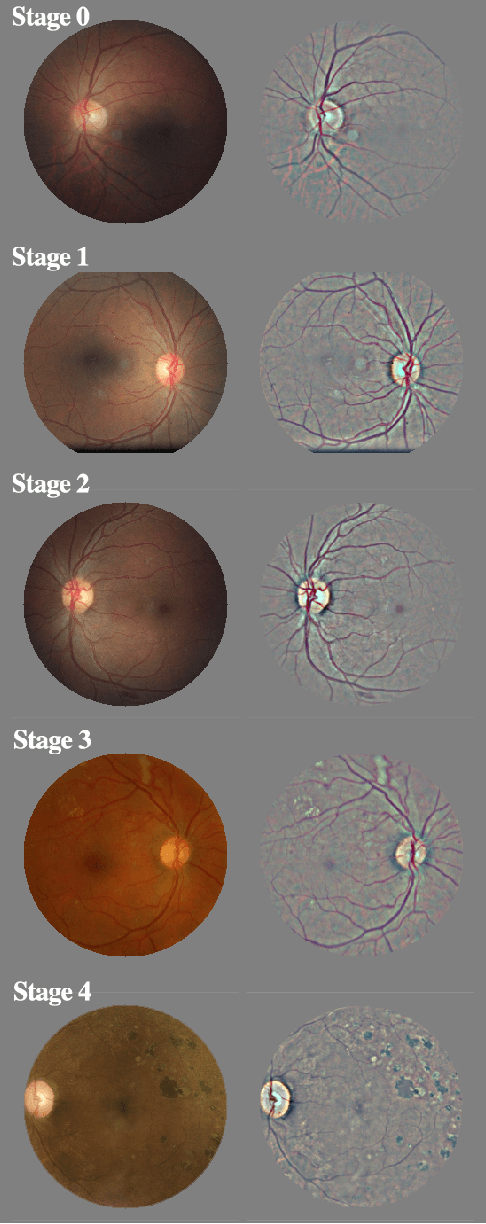
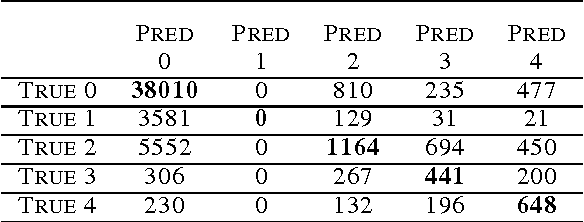
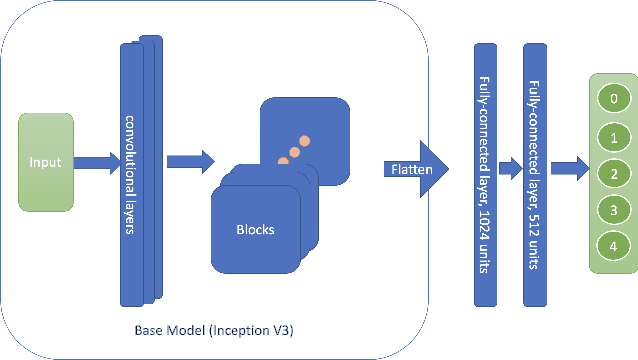
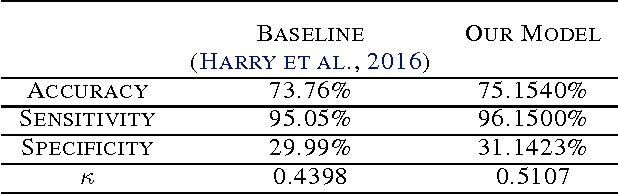
In this report, we applied integrated gradients to explaining a neural network for diabetic retinopathy detection. The integrated gradient is an attribution method which measures the contributions of input to the quantity of interest. We explored some new ways for applying this method such as explaining intermediate layers, filtering out unimportant units by their attribution value and generating contrary samples. Moreover, the visualization results extend the use of diabetic retinopathy detection model from merely predicting to assisting finding potential lesions.
Use Privacy in Data-Driven Systems: Theory and Experiments with Machine Learnt Programs
Sep 07, 2017
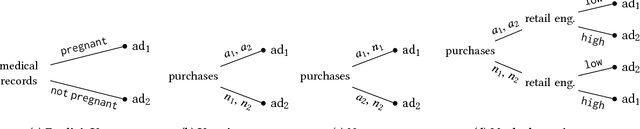


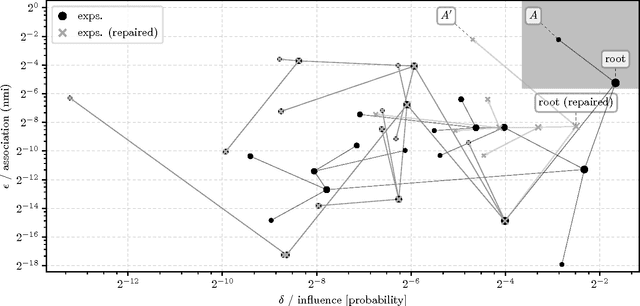
This paper presents an approach to formalizing and enforcing a class of use privacy properties in data-driven systems. In contrast to prior work, we focus on use restrictions on proxies (i.e. strong predictors) of protected information types. Our definition relates proxy use to intermediate computations that occur in a program, and identify two essential properties that characterize this behavior: 1) its result is strongly associated with the protected information type in question, and 2) it is likely to causally affect the final output of the program. For a specific instantiation of this definition, we present a program analysis technique that detects instances of proxy use in a model, and provides a witness that identifies which parts of the corresponding program exhibit the behavior. Recognizing that not all instances of proxy use of a protected information type are inappropriate, we make use of a normative judgment oracle that makes this inappropriateness determination for a given witness. Our repair algorithm uses the witness of an inappropriate proxy use to transform the model into one that provably does not exhibit proxy use, while avoiding changes that unduly affect classification accuracy. Using a corpus of social datasets, our evaluation shows that these algorithms are able to detect proxy use instances that would be difficult to find using existing techniques, and subsequently remove them while maintaining acceptable classification performance.
Proxy Non-Discrimination in Data-Driven Systems
Jul 25, 2017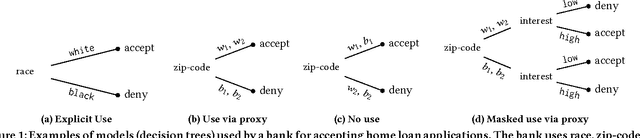

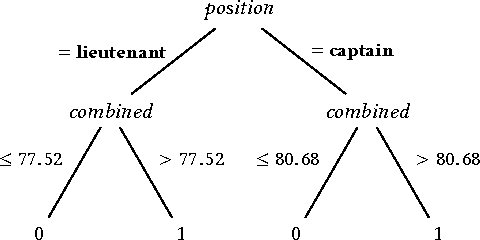
Machine learnt systems inherit biases against protected classes, historically disparaged groups, from training data. Usually, these biases are not explicit, they rely on subtle correlations discovered by training algorithms, and are therefore difficult to detect. We formalize proxy discrimination in data-driven systems, a class of properties indicative of bias, as the presence of protected class correlates that have causal influence on the system's output. We evaluate an implementation on a corpus of social datasets, demonstrating how to validate systems against these properties and to repair violations where they occur.
Debugging Machine Learning Tasks
Mar 23, 2016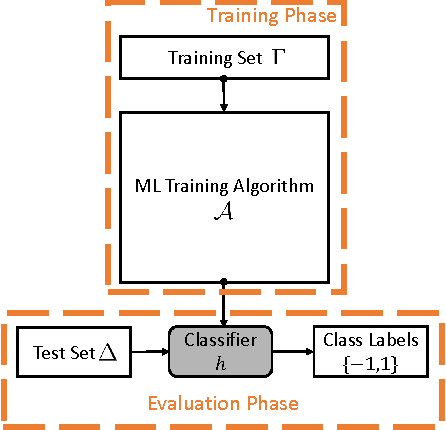
Unlike traditional programs (such as operating systems or word processors) which have large amounts of code, machine learning tasks use programs with relatively small amounts of code (written in machine learning libraries), but voluminous amounts of data. Just like developers of traditional programs debug errors in their code, developers of machine learning tasks debug and fix errors in their data. However, algorithms and tools for debugging and fixing errors in data are less common, when compared to their counterparts for detecting and fixing errors in code. In this paper, we consider classification tasks where errors in training data lead to misclassifications in test points, and propose an automated method to find the root causes of such misclassifications. Our root cause analysis is based on Pearl's theory of causation, and uses Pearl's PS (Probability of Sufficiency) as a scoring metric. Our implementation, Psi, encodes the computation of PS as a probabilistic program, and uses recent work on probabilistic programs and transformations on probabilistic programs (along with gray-box models of machine learning algorithms) to efficiently compute PS. Psi is able to identify root causes of data errors in interesting data sets.