 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDebugging Machine Learning Tasks
Mar 23, 2016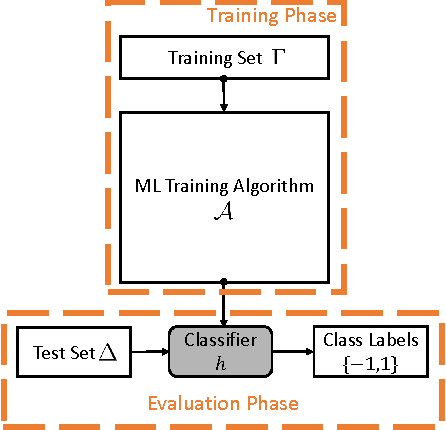
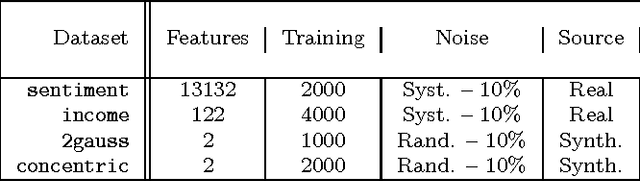
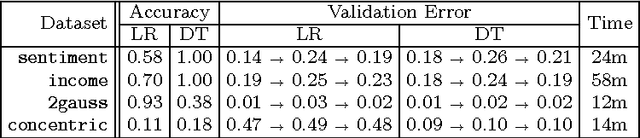
Unlike traditional programs (such as operating systems or word processors) which have large amounts of code, machine learning tasks use programs with relatively small amounts of code (written in machine learning libraries), but voluminous amounts of data. Just like developers of traditional programs debug errors in their code, developers of machine learning tasks debug and fix errors in their data. However, algorithms and tools for debugging and fixing errors in data are less common, when compared to their counterparts for detecting and fixing errors in code. In this paper, we consider classification tasks where errors in training data lead to misclassifications in test points, and propose an automated method to find the root causes of such misclassifications. Our root cause analysis is based on Pearl's theory of causation, and uses Pearl's PS (Probability of Sufficiency) as a scoring metric. Our implementation, Psi, encodes the computation of PS as a probabilistic program, and uses recent work on probabilistic programs and transformations on probabilistic programs (along with gray-box models of machine learning algorithms) to efficiently compute PS. Psi is able to identify root causes of data errors in interesting data sets.