 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfluence-Directed Explanations for Deep Convolutional Networks
Paper and Code

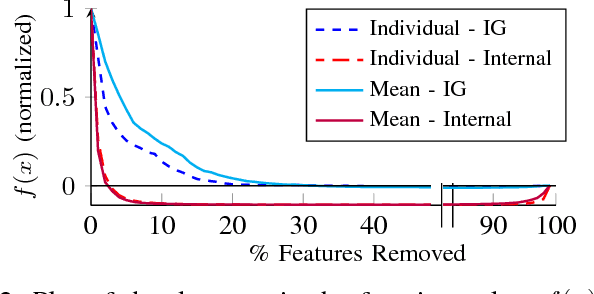


We study the problem of explaining a rich class of behavioral properties of deep neural networks. Distinctively, our influence-directed explanations approach this problem by peering inside the net- work to identify neurons with high influence on the property and distribution of interest using an axiomatically justified influence measure, and then providing an interpretation for the concepts these neurons represent. We evaluate our approach by training convolutional neural net- works on MNIST, ImageNet, Pubfig, and Diabetic Retinopathy datasets. Our evaluation demonstrates that influence-directed explanations (1) identify influential concepts that generalize across instances, (2) help extract the essence of what the network learned about a class, (3) isolate individual features the network uses to make decisions and distinguish related instances, and (4) assist in understanding misclassifications.