 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeiFlyBot-VLM Technical Report
Nov 07, 2025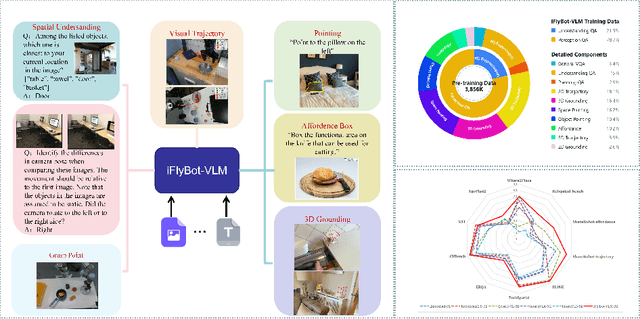

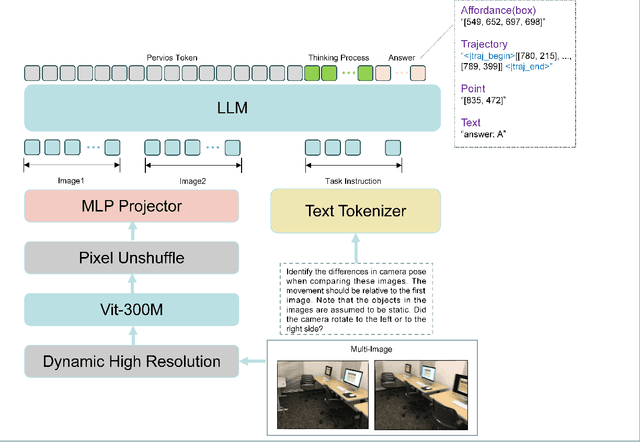
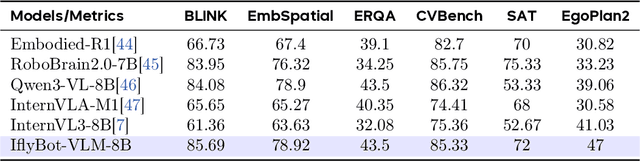
We introduce iFlyBot-VLM, a general-purpose Vision-Language Model (VLM) used to improve the domain of Embodied Intelligence. The central objective of iFlyBot-VLM is to bridge the cross-modal semantic gap between high-dimensional environmental perception and low-level robotic motion control. To this end, the model abstracts complex visual and spatial information into a body-agnostic and transferable Operational Language, thereby enabling seamless perception-action closed-loop coordination across diverse robotic platforms. The architecture of iFlyBot-VLM is systematically designed to realize four key functional capabilities essential for embodied intelligence: 1) Spatial Understanding and Metric Reasoning; 2) Interactive Target Grounding; 3) Action Abstraction and Control Parameter Generation; 4) Task Planning and Skill Sequencing. We envision iFlyBot-VLM as a scalable and generalizable foundation model for embodied AI, facilitating the progression from specialized task-oriented systems toward generalist, cognitively capable agents. We conducted evaluations on 10 current mainstream embodied intelligence-related VLM benchmark datasets, such as Blink and Where2Place, and achieved optimal performance while preserving the model's general capabilities. We will publicly release both the training data and model weights to foster further research and development in the field of Embodied Intelligence.
CloneShield: A Framework for Universal Perturbation Against Zero-Shot Voice Cloning
May 25, 2025Recent breakthroughs in text-to-speech (TTS) voice cloning have raised serious privacy concerns, allowing highly accurate vocal identity replication from just a few seconds of reference audio, while retaining the speaker's vocal authenticity. In this paper, we introduce CloneShield, a universal time-domain adversarial perturbation framework specifically designed to defend against zero-shot voice cloning. Our method provides protection that is robust across speakers and utterances, without requiring any prior knowledge of the synthesized text. We formulate perturbation generation as a multi-objective optimization problem, and propose Multi-Gradient Descent Algorithm (MGDA) to ensure the robust protection across diverse utterances. To preserve natural auditory perception for users, we decompose the adversarial perturbation via Mel-spectrogram representations and fine-tune it for each sample. This design ensures imperceptibility while maintaining strong degradation effects on zero-shot cloned outputs. Experiments on three state-of-the-art zero-shot TTS systems, five benchmark datasets and evaluations from 60 human listeners demonstrate that our method preserves near-original audio quality in protected inputs (PESQ = 3.90, SRS = 0.93) while substantially degrading both speaker similarity and speech quality in cloned samples (PESQ = 1.07, SRS = 0.08).
DIGIMON: Diagnosis and Mitigation of Sampling Skew for Reinforcement Learning based Meta-Planner in Robot Navigation
Sep 17, 2024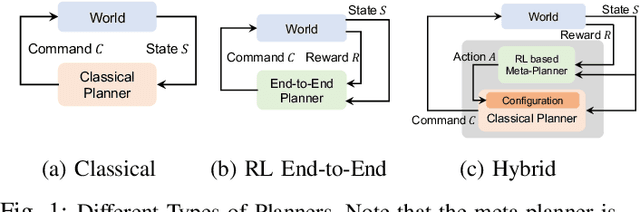



Robot navigation is increasingly crucial across applications like delivery services and warehouse management. The integration of Reinforcement Learning (RL) with classical planning has given rise to meta-planners that combine the adaptability of RL with the explainable decision-making of classical planners. However, the exploration capabilities of RL-based meta-planners during training are often constrained by the capabilities of the underlying classical planners. This constraint can result in limited exploration, thereby leading to sampling skew issues. To address these issues, our paper introduces a novel framework, DIGIMON, which begins with behavior-guided diagnosis for exploration bottlenecks within the meta-planner and follows up with a mitigation strategy that conducts up-sampling from diagnosed bottleneck data. Our evaluation shows 13.5%+ improvement in navigation performance, greater robustness in out-of-distribution environments, and a 4x boost in training efficiency. DIGIMON is designed as a versatile, plug-and-play solution, allowing seamless integration into various RL-based meta-planners.
ROCAS: Root Cause Analysis of Autonomous Driving Accidents via Cyber-Physical Co-mutation
Sep 12, 2024



As Autonomous driving systems (ADS) have transformed our daily life, safety of ADS is of growing significance. While various testing approaches have emerged to enhance the ADS reliability, a crucial gap remains in understanding the accidents causes. Such post-accident analysis is paramount and beneficial for enhancing ADS safety and reliability. Existing cyber-physical system (CPS) root cause analysis techniques are mainly designed for drones and cannot handle the unique challenges introduced by more complex physical environments and deep learning models deployed in ADS. In this paper, we address the gap by offering a formal definition of ADS root cause analysis problem and introducing ROCAS, a novel ADS root cause analysis framework featuring cyber-physical co-mutation. Our technique uniquely leverages both physical and cyber mutation that can precisely identify the accident-trigger entity and pinpoint the misconfiguration of the target ADS responsible for an accident. We further design a differential analysis to identify the responsible module to reduce search space for the misconfiguration. We study 12 categories of ADS accidents and demonstrate the effectiveness and efficiency of ROCAS in narrowing down search space and pinpointing the misconfiguration. We also show detailed case studies on how the identified misconfiguration helps understand rationale behind accidents.
Self-supervised Adversarial Training of Monocular Depth Estimation against Physical-World Attacks
Jun 09, 2024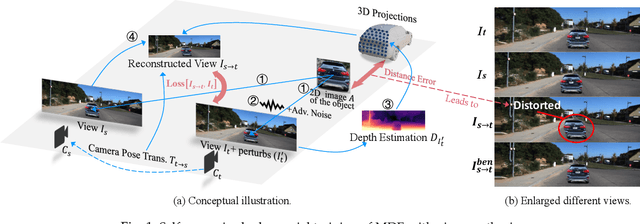

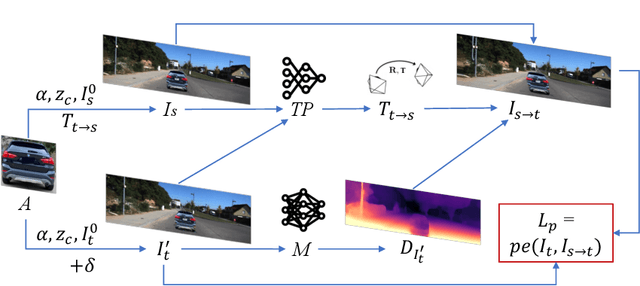
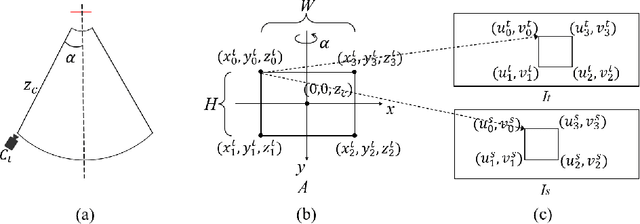
Monocular Depth Estimation (MDE) plays a vital role in applications such as autonomous driving. However, various attacks target MDE models, with physical attacks posing significant threats to system security. Traditional adversarial training methods, which require ground-truth labels, are not directly applicable to MDE models that lack ground-truth depth. Some self-supervised model hardening techniques (e.g., contrastive learning) overlook the domain knowledge of MDE, resulting in suboptimal performance. In this work, we introduce a novel self-supervised adversarial training approach for MDE models, leveraging view synthesis without the need for ground-truth depth. We enhance adversarial robustness against real-world attacks by incorporating L_0-norm-bounded perturbation during training. We evaluate our method against supervised learning-based and contrastive learning-based approaches specifically designed for MDE. Our experiments with two representative MDE networks demonstrate improved robustness against various adversarial attacks, with minimal impact on benign performance.
MixLoRA: Enhancing Large Language Models Fine-Tuning with LoRA based Mixture of Experts
Apr 22, 2024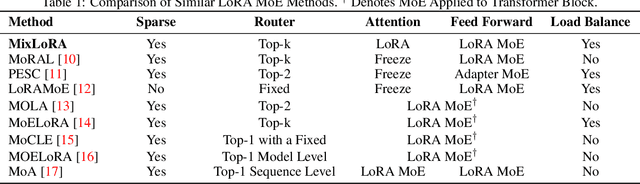
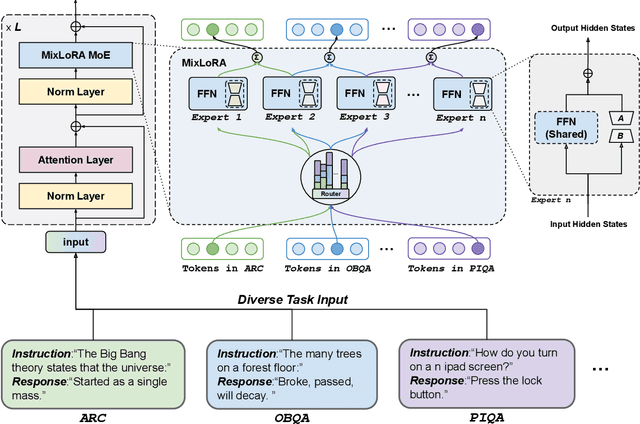


Large Language Models (LLMs) have showcased exceptional performance across a wide array of Natural Language Processing (NLP) tasks. Fine-tuning techniques are commonly utilized to tailor pre-trained models to specific applications. While methods like LoRA have effectively tackled GPU memory constraints during fine-tuning, their applicability is often restricted to limited performance, especially on multi-task. On the other hand, Mix-of-Expert (MoE) models, such as Mixtral 8x7B, demonstrate remarkable performance across multiple NLP tasks while maintaining a reduced parameter count. However, the resource requirements of these MoEs still challenging, particularly for consumer-grade GPUs only have limited VRAM. To address these challenge, we propose MixLoRA, an innovative approach aimed at constructing a resource-efficient sparse MoE model based on LoRA. MixLoRA inserts multiple LoRA-based experts within the feed-forward network block of a frozen pre-trained dense model through fine-tuning, employing a commonly used top-k router. Unlike other LoRA based MoE methods, MixLoRA enhances model performance by utilizing independently configurable attention-layer LoRA adapters, supporting the use of LoRA and its variants for the construction of experts, and applying auxiliary load balance loss to address the imbalance problem of the router. In experiments, MixLoRA achieves commendable performance across all evaluation metrics in both single-task and multi-task learning scenarios. Implemented within the m-LoRA framework, MixLoRA enables parallel fine-tuning of multiple mixture-of-experts models on a single 24GB consumer-grade GPU without quantization, thereby reducing GPU memory consumption by 41\% and latency during the training process by 17\%.
BadPart: Unified Black-box Adversarial Patch Attacks against Pixel-wise Regression Tasks
Apr 01, 2024
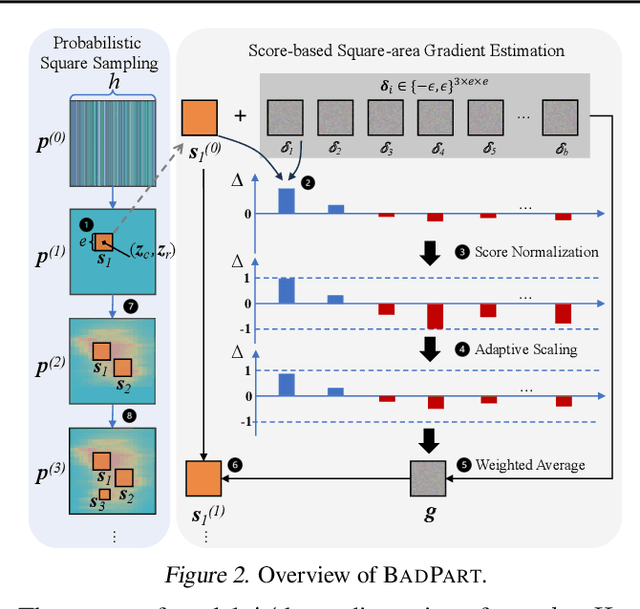

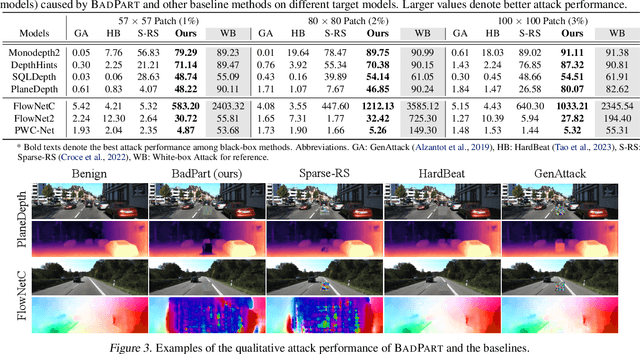
Pixel-wise regression tasks (e.g., monocular depth estimation (MDE) and optical flow estimation (OFE)) have been widely involved in our daily life in applications like autonomous driving, augmented reality and video composition. Although certain applications are security-critical or bear societal significance, the adversarial robustness of such models are not sufficiently studied, especially in the black-box scenario. In this work, we introduce the first unified black-box adversarial patch attack framework against pixel-wise regression tasks, aiming to identify the vulnerabilities of these models under query-based black-box attacks. We propose a novel square-based adversarial patch optimization framework and employ probabilistic square sampling and score-based gradient estimation techniques to generate the patch effectively and efficiently, overcoming the scalability problem of previous black-box patch attacks. Our attack prototype, named BadPart, is evaluated on both MDE and OFE tasks, utilizing a total of 7 models. BadPart surpasses 3 baseline methods in terms of both attack performance and efficiency. We also apply BadPart on the Google online service for portrait depth estimation, causing 43.5% relative distance error with 50K queries. State-of-the-art (SOTA) countermeasures cannot defend our attack effectively.
Fusion is Not Enough: Single-Modal Attacks to Compromise Fusion Models in Autonomous Driving
Apr 28, 2023
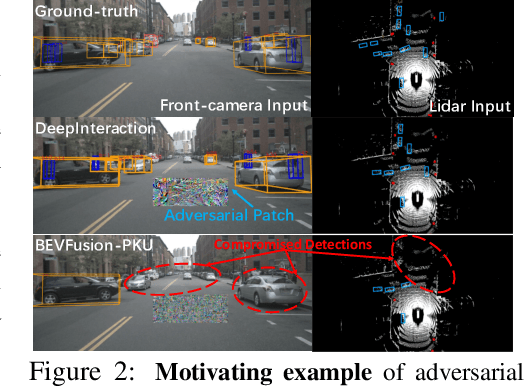

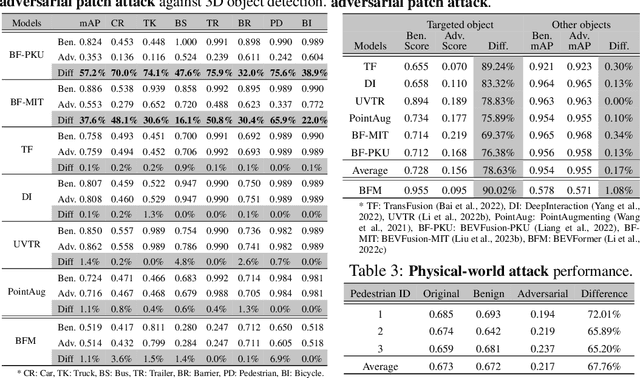
Multi-sensor fusion (MSF) is widely adopted for perception in autonomous vehicles (AVs), particularly for the task of 3D object detection with camera and LiDAR sensors. The rationale behind fusion is to capitalize on the strengths of each modality while mitigating their limitations. The exceptional and leading performance of fusion models has been demonstrated by advanced deep neural network (DNN)-based fusion techniques. Fusion models are also perceived as more robust to attacks compared to single-modal ones due to the redundant information in multiple modalities. In this work, we challenge this perspective with single-modal attacks that targets the camera modality, which is considered less significant in fusion but more affordable for attackers. We argue that the weakest link of fusion models depends on their most vulnerable modality, and propose an attack framework that targets advanced camera-LiDAR fusion models with adversarial patches. Our approach employs a two-stage optimization-based strategy that first comprehensively assesses vulnerable image areas under adversarial attacks, and then applies customized attack strategies to different fusion models, generating deployable patches. Evaluations with five state-of-the-art camera-LiDAR fusion models on a real-world dataset show that our attacks successfully compromise all models. Our approach can either reduce the mean average precision (mAP) of detection performance from 0.824 to 0.353 or degrade the detection score of the target object from 0.727 to 0.151 on average, demonstrating the effectiveness and practicality of our proposed attack framework.
Adversarial Training of Self-supervised Monocular Depth Estimation against Physical-World Attacks
Feb 08, 2023Monocular Depth Estimation (MDE) is a critical component in applications such as autonomous driving. There are various attacks against MDE networks. These attacks, especially the physical ones, pose a great threat to the security of such systems. Traditional adversarial training method requires ground-truth labels hence cannot be directly applied to self-supervised MDE that does not have ground-truth depth. Some self-supervised model hardening techniques (e.g., contrastive learning) ignore the domain knowledge of MDE and can hardly achieve optimal performance. In this work, we propose a novel adversarial training method for self-supervised MDE models based on view synthesis without using ground-truth depth. We improve adversarial robustness against physical-world attacks using L0-norm-bounded perturbation in training. We compare our method with supervised learning based and contrastive learning based methods that are tailored for MDE. Results on two representative MDE networks show that we achieve better robustness against various adversarial attacks with nearly no benign performance degradation.
Physical Attack on Monocular Depth Estimation with Optimal Adversarial Patches
Jul 11, 2022

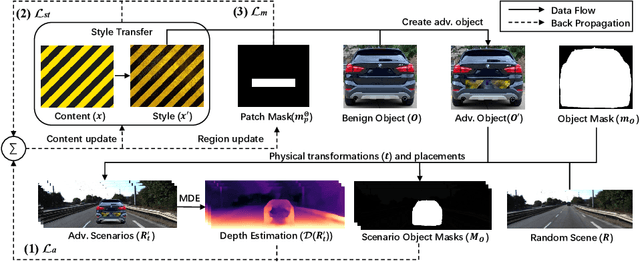
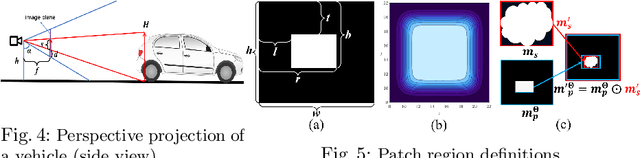
Deep learning has substantially boosted the performance of Monocular Depth Estimation (MDE), a critical component in fully vision-based autonomous driving (AD) systems (e.g., Tesla and Toyota). In this work, we develop an attack against learning-based MDE. In particular, we use an optimization-based method to systematically generate stealthy physical-object-oriented adversarial patches to attack depth estimation. We balance the stealth and effectiveness of our attack with object-oriented adversarial design, sensitive region localization, and natural style camouflage. Using real-world driving scenarios, we evaluate our attack on concurrent MDE models and a representative downstream task for AD (i.e., 3D object detection). Experimental results show that our method can generate stealthy, effective, and robust adversarial patches for different target objects and models and achieves more than 6 meters mean depth estimation error and 93% attack success rate (ASR) in object detection with a patch of 1/9 of the vehicle's rear area. Field tests on three different driving routes with a real vehicle indicate that we cause over 6 meters mean depth estimation error and reduce the object detection rate from 90.70% to 5.16% in continuous video frames.