 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusion is Not Enough: Single-Modal Attacks to Compromise Fusion Models in Autonomous Driving
Paper and Code
Apr 28, 2023
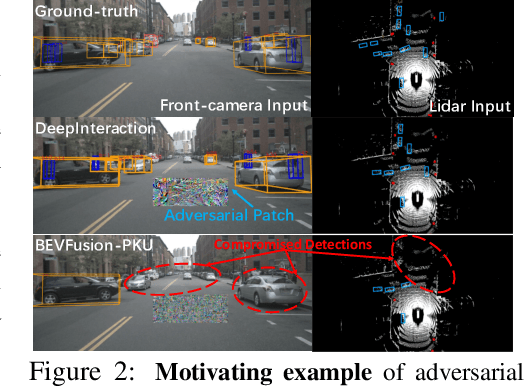

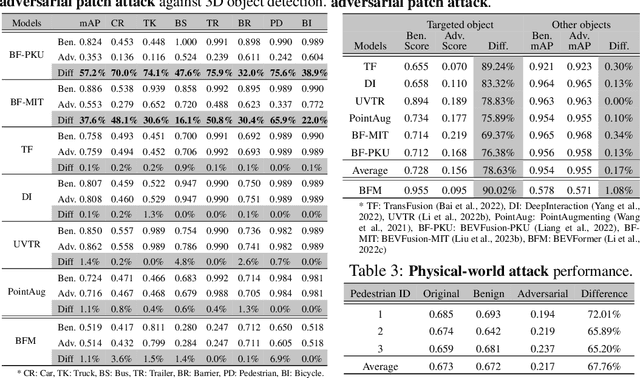
Multi-sensor fusion (MSF) is widely adopted for perception in autonomous vehicles (AVs), particularly for the task of 3D object detection with camera and LiDAR sensors. The rationale behind fusion is to capitalize on the strengths of each modality while mitigating their limitations. The exceptional and leading performance of fusion models has been demonstrated by advanced deep neural network (DNN)-based fusion techniques. Fusion models are also perceived as more robust to attacks compared to single-modal ones due to the redundant information in multiple modalities. In this work, we challenge this perspective with single-modal attacks that targets the camera modality, which is considered less significant in fusion but more affordable for attackers. We argue that the weakest link of fusion models depends on their most vulnerable modality, and propose an attack framework that targets advanced camera-LiDAR fusion models with adversarial patches. Our approach employs a two-stage optimization-based strategy that first comprehensively assesses vulnerable image areas under adversarial attacks, and then applies customized attack strategies to different fusion models, generating deployable patches. Evaluations with five state-of-the-art camera-LiDAR fusion models on a real-world dataset show that our attacks successfully compromise all models. Our approach can either reduce the mean average precision (mAP) of detection performance from 0.824 to 0.353 or degrade the detection score of the target object from 0.727 to 0.151 on average, demonstrating the effectiveness and practicality of our proposed attack framework.