 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixLoRA: Enhancing Large Language Models Fine-Tuning with LoRA based Mixture of Experts
Paper and Code
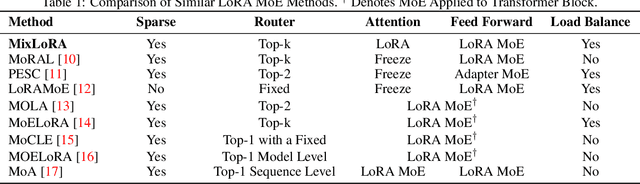
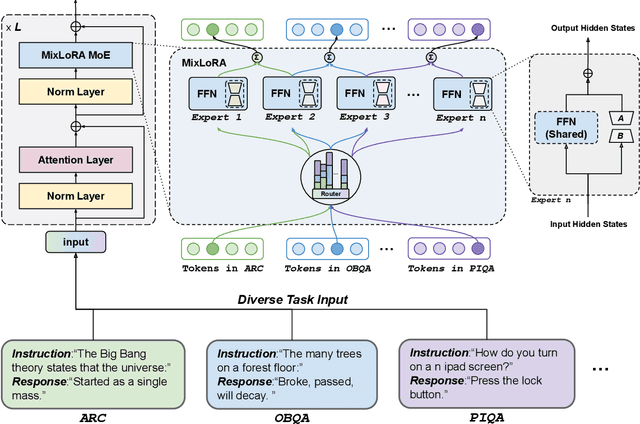


Large Language Models (LLMs) have showcased exceptional performance across a wide array of Natural Language Processing (NLP) tasks. Fine-tuning techniques are commonly utilized to tailor pre-trained models to specific applications. While methods like LoRA have effectively tackled GPU memory constraints during fine-tuning, their applicability is often restricted to limited performance, especially on multi-task. On the other hand, Mix-of-Expert (MoE) models, such as Mixtral 8x7B, demonstrate remarkable performance across multiple NLP tasks while maintaining a reduced parameter count. However, the resource requirements of these MoEs still challenging, particularly for consumer-grade GPUs only have limited VRAM. To address these challenge, we propose MixLoRA, an innovative approach aimed at constructing a resource-efficient sparse MoE model based on LoRA. MixLoRA inserts multiple LoRA-based experts within the feed-forward network block of a frozen pre-trained dense model through fine-tuning, employing a commonly used top-k router. Unlike other LoRA based MoE methods, MixLoRA enhances model performance by utilizing independently configurable attention-layer LoRA adapters, supporting the use of LoRA and its variants for the construction of experts, and applying auxiliary load balance loss to address the imbalance problem of the router. In experiments, MixLoRA achieves commendable performance across all evaluation metrics in both single-task and multi-task learning scenarios. Implemented within the m-LoRA framework, MixLoRA enables parallel fine-tuning of multiple mixture-of-experts models on a single 24GB consumer-grade GPU without quantization, thereby reducing GPU memory consumption by 41\% and latency during the training process by 17\%.