 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
TableDreamer: Progressive and Weakness-guided Data Synthesis from Scratch for Table Instruction Tuning
Jun 10, 2025Despite the commendable progress of recent LLM-based data synthesis methods, they face two limitations in generating table instruction tuning data. First, they can not thoroughly explore the vast input space of table understanding tasks, leading to limited data diversity. Second, they ignore the weaknesses in table understanding ability of the target LLM and blindly pursue the increase of data quantity, resulting in suboptimal data efficiency. In this paper, we introduce a progressive and weakness-guided data synthesis framework tailored for table instruction tuning, named TableDreamer, to mitigate the above issues. Specifically, we first synthesize diverse tables and related instructions as seed data, and then perform an iterative exploration of the input space under the guidance of the newly identified weakness data, which eventually serve as the final training data for fine-tuning the target LLM. Extensive experiments on 10 tabular benchmarks demonstrate the effectiveness of the proposed framework, which boosts the average accuracy of Llama3.1-8B-instruct by 11.62% (49.07% to 60.69%) with 27K GPT-4o synthetic data and outperforms state-of-the-art data synthesis baselines which use more training data. The code and data is available at https://github.com/SpursGoZmy/TableDreamer
Improving Video Retrieval by Adaptive Margin
Mar 09, 2023Video retrieval is becoming increasingly important owing to the rapid emergence of videos on the Internet. The dominant paradigm for video retrieval learns video-text representations by pushing the distance between the similarity of positive pairs and that of negative pairs apart from a fixed margin. However, negative pairs used for training are sampled randomly, which indicates that the semantics between negative pairs may be related or even equivalent, while most methods still enforce dissimilar representations to decrease their similarity. This phenomenon leads to inaccurate supervision and poor performance in learning video-text representations. While most video retrieval methods overlook that phenomenon, we propose an adaptive margin changed with the distance between positive and negative pairs to solve the aforementioned issue. First, we design the calculation framework of the adaptive margin, including the method of distance measurement and the function between the distance and the margin. Then, we explore a novel implementation called "Cross-Modal Generalized Self-Distillation" (CMGSD), which can be built on the top of most video retrieval models with few modifications. Notably, CMGSD adds few computational overheads at train time and adds no computational overhead at test time. Experimental results on three widely used datasets demonstrate that the proposed method can yield significantly better performance than the corresponding backbone model, and it outperforms state-of-the-art methods by a large margin.
CLOP: Video-and-Language Pre-Training with Knowledge Regularizations
Nov 07, 2022Video-and-language pre-training has shown promising results for learning generalizable representations. Most existing approaches usually model video and text in an implicit manner, without considering explicit structural representations of the multi-modal content. We denote such form of representations as structural knowledge, which express rich semantics of multiple granularities. There are related works that propose object-aware approaches to inject similar knowledge as inputs. However, the existing methods usually fail to effectively utilize such knowledge as regularizations to shape a superior cross-modal representation space. To this end, we propose a Cross-modaL knOwledge-enhanced Pre-training (CLOP) method with Knowledge Regularizations. There are two key designs of ours: 1) a simple yet effective Structural Knowledge Prediction (SKP) task to pull together the latent representations of similar videos; and 2) a novel Knowledge-guided sampling approach for Contrastive Learning (KCL) to push apart cross-modal hard negative samples. We evaluate our method on four text-video retrieval tasks and one multi-choice QA task. The experiments show clear improvements, outperforming prior works by a substantial margin. Besides, we provide ablations and insights of how our methods affect the latent representation space, demonstrating the value of incorporating knowledge regularizations into video-and-language pre-training.
UPainting: Unified Text-to-Image Diffusion Generation with Cross-modal Guidance
Nov 03, 2022



Diffusion generative models have recently greatly improved the power of text-conditioned image generation. Existing image generation models mainly include text conditional diffusion model and cross-modal guided diffusion model, which are good at small scene image generation and complex scene image generation respectively. In this work, we propose a simple yet effective approach, namely UPainting, to unify simple and complex scene image generation, as shown in Figure 1. Based on architecture improvements and diverse guidance schedules, UPainting effectively integrates cross-modal guidance from a pretrained image-text matching model into a text conditional diffusion model that utilizes a pretrained Transformer language model as the text encoder. Our key findings is that combining the power of large-scale Transformer language model in understanding language and image-text matching model in capturing cross-modal semantics and style, is effective to improve sample fidelity and image-text alignment of image generation. In this way, UPainting has a more general image generation capability, which can generate images of both simple and complex scenes more effectively. To comprehensively compare text-to-image models, we further create a more general benchmark, UniBench, with well-written Chinese and English prompts in both simple and complex scenes. We compare UPainting with recent models and find that UPainting greatly outperforms other models in terms of caption similarity and image fidelity in both simple and complex scenes. UPainting project page \url{https://upainting.github.io/}.
A CLIP-Enhanced Method for Video-Language Understanding
Oct 14, 2021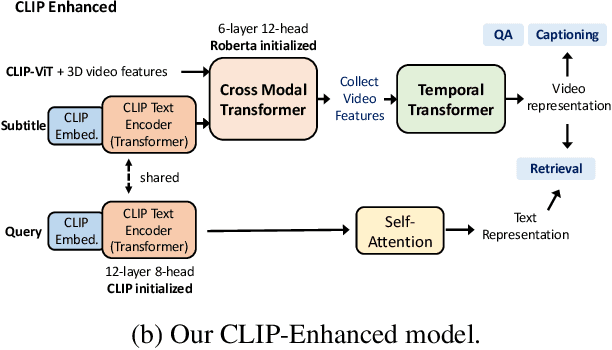
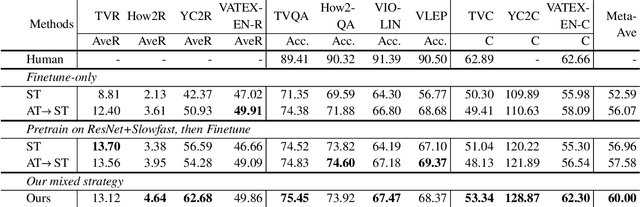
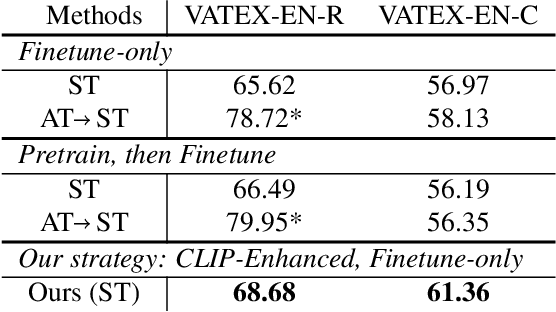
This technical report summarizes our method for the Video-And-Language Understanding Evaluation (VALUE) challenge (https://value-benchmark.github.io/challenge\_2021.html). We propose a CLIP-Enhanced method to incorporate the image-text pretrained knowledge into downstream video-text tasks. Combined with several other improved designs, our method outperforms the state-of-the-art by $2.4\%$ ($57.58$ to $60.00$) Meta-Ave score on VALUE benchmark.
Overview of the CCKS 2019 Knowledge Graph Evaluation Track: Entity, Relation, Event and QA
Mar 09, 2020Knowledge graph models world knowledge as concepts, entities, and the relationships between them, which has been widely used in many real-world tasks. CCKS 2019 held an evaluation track with 6 tasks and attracted more than 1,600 teams. In this paper, we give an overview of the knowledge graph evaluation tract at CCKS 2019. By reviewing the task definition, successful methods, useful resources, good strategies and research challenges associated with each task in CCKS 2019, this paper can provide a helpful reference for developing knowledge graph applications and conducting future knowledge graph researches.