 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Closer Look into LLMs for Table Understanding
Mar 16, 2026Despite the success of Large Language Models (LLMs) in table understanding, their internal mechanisms remain unclear. In this paper, we conduct an empirical study on 16 LLMs, covering general LLMs, specialist tabular LLMs, and Mixture-of-Experts (MoE) models, to explore how LLMs understand tabular data and perform downstream tasks. Our analysis focus on 4 dimensions including the attention dynamics, the effective layer depth, the expert activation, and the impacts of input designs. Key findings include: (1) LLMs follow a three-phase attention pattern -- early layers scan the table broadly, middle layers localize relevant cells, and late layers amplify their contributions; (2) tabular tasks require deeper layers than math reasoning to reach stable predictions; (3) MoE models activate table-specific experts in middle layers, with early and late layers sharing general-purpose experts; (4) Chain-of-Thought prompting increases table attention, further enhanced by table-tuning. We hope these findings and insights can facilitate interpretability and future research on table-related tasks.
PodBench: A Comprehensive Benchmark for Instruction-Aware Audio-Oriented Podcast Script Generation
Jan 21, 2026Podcast script generation requires LLMs to synthesize structured, context-grounded dialogue from diverse inputs, yet systematic evaluation resources for this task remain limited. To bridge this gap, we introduce PodBench, a benchmark comprising 800 samples with inputs up to 21K tokens and complex multi-speaker instructions. We propose a multifaceted evaluation framework that integrates quantitative constraints with LLM-based quality assessment. Extensive experiments reveal that while proprietary models generally excel, open-source models equipped with explicit reasoning demonstrate superior robustness in handling long contexts and multi-speaker coordination compared to standard baselines. However, our analysis uncovers a persistent divergence where high instruction following does not guarantee high content substance. PodBench offers a reproducible testbed to address these challenges in long-form, audio-centric generation.
Weights-Rotated Preference Optimization for Large Language Models
Aug 25, 2025Despite the efficacy of Direct Preference Optimization (DPO) in aligning Large Language Models (LLMs), reward hacking remains a pivotal challenge. This issue emerges when LLMs excessively reduce the probability of rejected completions to achieve high rewards, without genuinely meeting their intended goals. As a result, this leads to overly lengthy generation lacking diversity, as well as catastrophic forgetting of knowledge. We investigate the underlying reason behind this issue, which is representation redundancy caused by neuron collapse in the parameter space. Hence, we propose a novel Weights-Rotated Preference Optimization (RoPO) algorithm, which implicitly constrains the output layer logits with the KL divergence inherited from DPO and explicitly constrains the intermediate hidden states by fine-tuning on a multi-granularity orthogonal matrix. This design prevents the policy model from deviating too far from the reference model, thereby retaining the knowledge and expressive capabilities acquired during pre-training and SFT stages. Our RoPO achieves up to a 3.27-point improvement on AlpacaEval 2, and surpasses the best baseline by 6.2 to 7.5 points on MT-Bench with merely 0.015% of the trainable parameters, demonstrating its effectiveness in alleviating the reward hacking problem of DPO.
TableDreamer: Progressive and Weakness-guided Data Synthesis from Scratch for Table Instruction Tuning
Jun 10, 2025Despite the commendable progress of recent LLM-based data synthesis methods, they face two limitations in generating table instruction tuning data. First, they can not thoroughly explore the vast input space of table understanding tasks, leading to limited data diversity. Second, they ignore the weaknesses in table understanding ability of the target LLM and blindly pursue the increase of data quantity, resulting in suboptimal data efficiency. In this paper, we introduce a progressive and weakness-guided data synthesis framework tailored for table instruction tuning, named TableDreamer, to mitigate the above issues. Specifically, we first synthesize diverse tables and related instructions as seed data, and then perform an iterative exploration of the input space under the guidance of the newly identified weakness data, which eventually serve as the final training data for fine-tuning the target LLM. Extensive experiments on 10 tabular benchmarks demonstrate the effectiveness of the proposed framework, which boosts the average accuracy of Llama3.1-8B-instruct by 11.62% (49.07% to 60.69%) with 27K GPT-4o synthetic data and outperforms state-of-the-art data synthesis baselines which use more training data. The code and data is available at https://github.com/SpursGoZmy/TableDreamer
NeedleInATable: Exploring Long-Context Capability of Large Language Models towards Long-Structured Tables
Apr 09, 2025Processing structured tabular data, particularly lengthy tables, constitutes a fundamental yet challenging task for large language models (LLMs). However, existing long-context benchmarks primarily focus on unstructured text, neglecting the challenges of long and complex structured tables. To address this gap, we introduce NeedleInATable (NIAT), a novel task that treats each table cell as a "needle" and requires the model to extract the target cell under different queries. Evaluation results of mainstream LLMs on this benchmark show they lack robust long-table comprehension, often relying on superficial correlations or shortcuts for complex table understanding tasks, revealing significant limitations in processing intricate tabular data. To this end, we propose a data synthesis method to enhance models' long-table comprehension capabilities. Experimental results show that our synthesized training data significantly enhances LLMs' performance on the NIAT task, outperforming both long-context LLMs and long-table agent methods. This work advances the evaluation of LLMs' genuine long-structured table comprehension capabilities and paves the way for progress in long-context and table understanding applications.
Multimodal Table Understanding
Jun 12, 2024



Although great progress has been made by previous table understanding methods including recent approaches based on large language models (LLMs), they rely heavily on the premise that given tables must be converted into a certain text sequence (such as Markdown or HTML) to serve as model input. However, it is difficult to access such high-quality textual table representations in some real-world scenarios, and table images are much more accessible. Therefore, how to directly understand tables using intuitive visual information is a crucial and urgent challenge for developing more practical applications. In this paper, we propose a new problem, multimodal table understanding, where the model needs to generate correct responses to various table-related requests based on the given table image. To facilitate both the model training and evaluation, we construct a large-scale dataset named MMTab, which covers a wide spectrum of table images, instructions and tasks. On this basis, we develop Table-LLaVA, a generalist tabular multimodal large language model (MLLM), which significantly outperforms recent open-source MLLM baselines on 23 benchmarks under held-in and held-out settings. The code and data is available at this https://github.com/SpursGoZmy/Table-LLaVA
Language Prior Is Not the Only Shortcut: A Benchmark for Shortcut Learning in VQA
Oct 10, 2022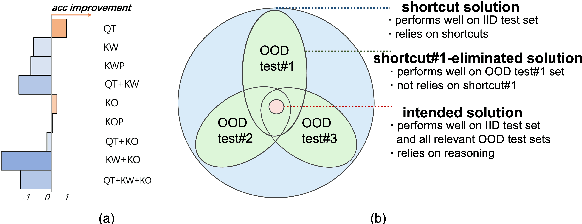
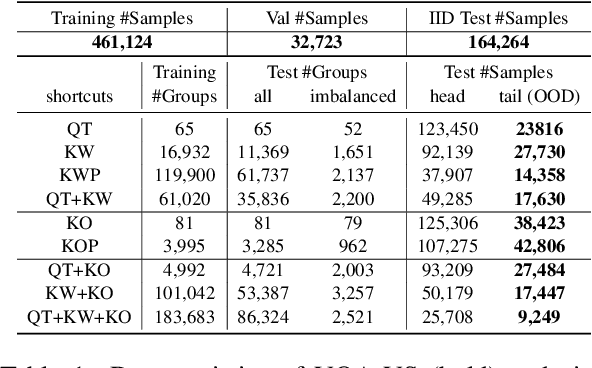
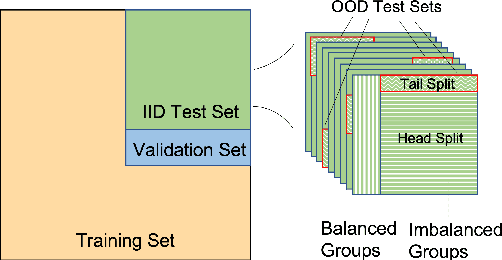
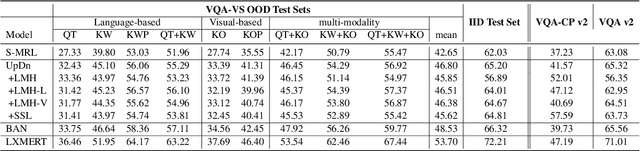
Visual Question Answering (VQA) models are prone to learn the shortcut solution formed by dataset biases rather than the intended solution. To evaluate the VQA models' reasoning ability beyond shortcut learning, the VQA-CP v2 dataset introduces a distribution shift between the training and test set given a question type. In this way, the model cannot use the training set shortcut (from question type to answer) to perform well on the test set. However, VQA-CP v2 only considers one type of shortcut and thus still cannot guarantee that the model relies on the intended solution rather than a solution specific to this shortcut. To overcome this limitation, we propose a new dataset that considers varying types of shortcuts by constructing different distribution shifts in multiple OOD test sets. In addition, we overcome the three troubling practices in the use of VQA-CP v2, e.g., selecting models using OOD test sets, and further standardize OOD evaluation procedure. Our benchmark provides a more rigorous and comprehensive testbed for shortcut learning in VQA. We benchmark recent methods and find that methods specifically designed for particular shortcuts fail to simultaneously generalize to our varying OOD test sets. We also systematically study the varying shortcuts and provide several valuable findings, which may promote the exploration of shortcut learning in VQA.
Check It Again: Progressive Visual Question Answering via Visual Entailment
Jun 08, 2021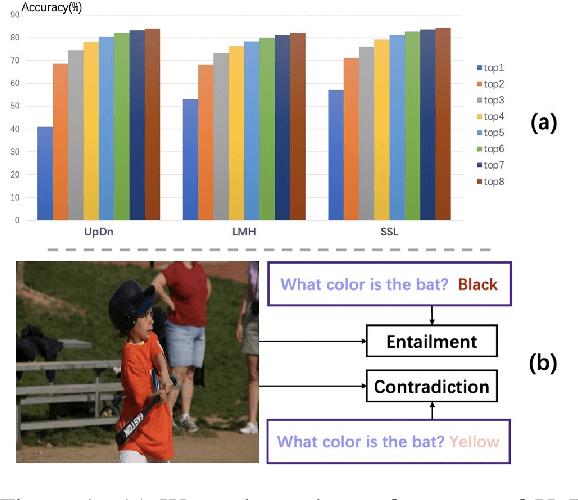



While sophisticated Visual Question Answering models have achieved remarkable success, they tend to answer questions only according to superficial correlations between question and answer. Several recent approaches have been developed to address this language priors problem. However, most of them predict the correct answer according to one best output without checking the authenticity of answers. Besides, they only explore the interaction between image and question, ignoring the semantics of candidate answers. In this paper, we propose a select-and-rerank (SAR) progressive framework based on Visual Entailment. Specifically, we first select the candidate answers relevant to the question or the image, then we rerank the candidate answers by a visual entailment task, which verifies whether the image semantically entails the synthetic statement of the question and each candidate answer. Experimental results show the effectiveness of our proposed framework, which establishes a new state-of-the-art accuracy on VQA-CP v2 with a 7.55% improvement.