 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHy-MT2: A Family of Fast, Efficient and Powerful Multilingual Translation Models in the Wild
May 21, 2026Hy-MT2 is a family of fast-thinking multilingual translation models designed for complex real-world scenarios. It includes three model sizes: 1.8B, 7B, and 30B-A3B (MoE), all of which support translation among 33 languages and effectively follow translation instructions in multiple languages. For on-device deployment, with AngelSlim 1.25-bit extreme quantization, the 1.8B model requires only 440 MB of storage and improves inference speed by 1.5x. Multi-dimensional evaluations show that Hy-MT2 delivers outstanding performance across general, real-world business, domain-specific, and instruction-following translation tasks. The 7B and 30B models outperform open-source models such as DeepSeek-V4-Pro and Kimi K2.6 in fast-thinking mode, while the lightweight 1.8B model also surpasses mainstream commercial APIs from providers such as Microsoft and Doubao overall.
TableDreamer: Progressive and Weakness-guided Data Synthesis from Scratch for Table Instruction Tuning
Jun 10, 2025Despite the commendable progress of recent LLM-based data synthesis methods, they face two limitations in generating table instruction tuning data. First, they can not thoroughly explore the vast input space of table understanding tasks, leading to limited data diversity. Second, they ignore the weaknesses in table understanding ability of the target LLM and blindly pursue the increase of data quantity, resulting in suboptimal data efficiency. In this paper, we introduce a progressive and weakness-guided data synthesis framework tailored for table instruction tuning, named TableDreamer, to mitigate the above issues. Specifically, we first synthesize diverse tables and related instructions as seed data, and then perform an iterative exploration of the input space under the guidance of the newly identified weakness data, which eventually serve as the final training data for fine-tuning the target LLM. Extensive experiments on 10 tabular benchmarks demonstrate the effectiveness of the proposed framework, which boosts the average accuracy of Llama3.1-8B-instruct by 11.62% (49.07% to 60.69%) with 27K GPT-4o synthetic data and outperforms state-of-the-art data synthesis baselines which use more training data. The code and data is available at https://github.com/SpursGoZmy/TableDreamer
NeedleInATable: Exploring Long-Context Capability of Large Language Models towards Long-Structured Tables
Apr 09, 2025Processing structured tabular data, particularly lengthy tables, constitutes a fundamental yet challenging task for large language models (LLMs). However, existing long-context benchmarks primarily focus on unstructured text, neglecting the challenges of long and complex structured tables. To address this gap, we introduce NeedleInATable (NIAT), a novel task that treats each table cell as a "needle" and requires the model to extract the target cell under different queries. Evaluation results of mainstream LLMs on this benchmark show they lack robust long-table comprehension, often relying on superficial correlations or shortcuts for complex table understanding tasks, revealing significant limitations in processing intricate tabular data. To this end, we propose a data synthesis method to enhance models' long-table comprehension capabilities. Experimental results show that our synthesized training data significantly enhances LLMs' performance on the NIAT task, outperforming both long-context LLMs and long-table agent methods. This work advances the evaluation of LLMs' genuine long-structured table comprehension capabilities and paves the way for progress in long-context and table understanding applications.
Ltri-LLM: Streaming Long Context Inference for LLMs with Training-Free Dynamic Triangular Attention Pattern
Dec 06, 2024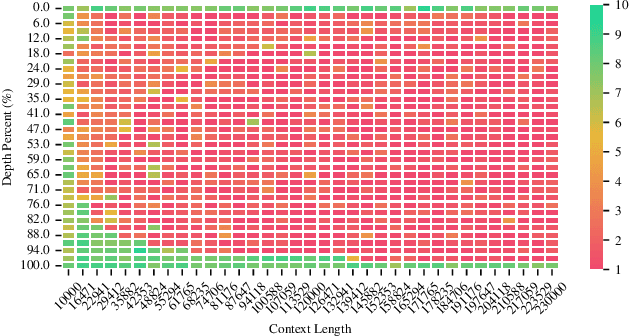

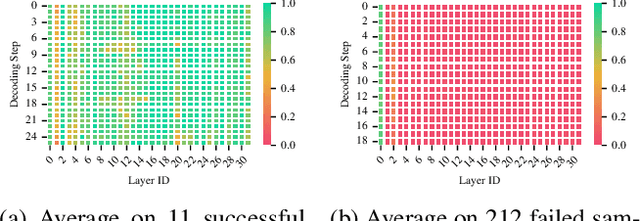

The quadratic computational complexity of the attention mechanism in current Large Language Models (LLMs) renders inference with long contexts prohibitively expensive. To address this challenge, various approaches aim to retain critical portions of the context to optimally approximate Full Attention (FA) through Key-Value (KV) compression or Sparse Attention (SA), enabling the processing of virtually unlimited text lengths in a streaming manner. However, these methods struggle to achieve performance levels comparable to FA, particularly in retrieval tasks. In this paper, our analysis of attention head patterns reveals that LLMs' attention distributions show strong local correlations, naturally reflecting a chunking mechanism for input context. We propose Ltri-LLM framework, which divides KVs into spans, stores them in an offline index, and retrieves the relevant KVs into memory for various queries. Experimental results on popular long text benchmarks show that Ltri-LLM can achieve performance close to FA while maintaining efficient, streaming-based inference.
A Factuality and Diversity Reconciled Decoding Method for Knowledge-Grounded Dialogue Generation
Jul 08, 2024Grounding external knowledge can enhance the factuality of responses in dialogue generation. However, excessive emphasis on it might result in the lack of engaging and diverse expressions. Through the introduction of randomness in sampling, current approaches can increase the diversity. Nevertheless, such sampling method could undermine the factuality in dialogue generation. In this study, to discover a solution for advancing creativity without relying on questionable randomness and to subtly reconcile the factuality and diversity within the source-grounded paradigm, a novel method named DoGe is proposed. DoGe can dynamically alternate between the utilization of internal parameter knowledge and external source knowledge based on the model's factual confidence. Extensive experiments on three widely-used datasets show that DoGe can not only enhance response diversity but also maintain factuality, and it significantly surpasses other various decoding strategy baselines.
Think out Loud: Emotion Deducing Explanation in Dialogues
Jun 07, 2024



Humans convey emotions through daily dialogues, making emotion understanding a crucial step of affective intelligence. To understand emotions in dialogues, machines are asked to recognize the emotion for an utterance (Emotion Recognition in Dialogues, ERD); based on the emotion, then find causal utterances for the emotion (Emotion Cause Extraction in Dialogues, ECED). The setting of the two tasks requires first ERD and then ECED, ignoring the mutual complement between emotion and cause. To fix this, some new tasks are proposed to extract them simultaneously. Although the current research on these tasks has excellent achievements, simply identifying emotion-related factors by classification modeling lacks realizing the specific thinking process of causes stimulating the emotion in an explainable way. This thinking process especially reflected in the reasoning ability of Large Language Models (LLMs) is under-explored. To this end, we propose a new task "Emotion Deducing Explanation in Dialogues" (EDEN). EDEN recognizes emotion and causes in an explicitly thinking way. That is, models need to generate an explanation text, which first summarizes the causes; analyzes the inner activities of the speakers triggered by the causes using common sense; then guesses the emotion accordingly. To support the study of EDEN, based on the existing resources in ECED, we construct two EDEN datasets by human effort. We further evaluate different models on EDEN and find that LLMs are more competent than conventional PLMs. Besides, EDEN can help LLMs achieve better recognition of emotions and causes, which explores a new research direction of explainable emotion understanding in dialogues.
Enhancing Empathetic and Emotion Support Dialogue Generation with Prophetic Commonsense Inference
Nov 26, 2023



The interest in Empathetic and Emotional Support conversations among the public has significantly increased. To offer more sensitive and understanding responses, leveraging commonsense knowledge has become a common strategy to better understand psychological aspects and causality. However, such commonsense inferences can be out of context and unable to predict upcoming dialogue themes, resulting in responses that lack coherence and empathy. To remedy this issue, we present Prophetic Commonsense Inference, an innovative paradigm for inferring commonsense knowledge. By harnessing the capabilities of Large Language Models in understanding dialogue and making commonsense deductions, we train tunable models to bridge the gap between past and potential future dialogues. Extensive experiments conducted on EmpatheticDialogues and Emotion Support Conversation show that equipping dialogue agents with our proposed prophetic commonsense inference significantly enhances the quality of their responses.
Multi-level Adaptive Contrastive Learning for Knowledge Internalization in Dialogue Generation
Oct 17, 2023Knowledge-grounded dialogue generation aims to mitigate the issue of text degeneration by incorporating external knowledge to supplement the context. However, the model often fails to internalize this information into responses in a human-like manner. Instead, it simply inserts segments of the provided knowledge into generic responses. As a result, the generated responses tend to be tedious, incoherent, and in lack of interactivity which means the degeneration problem is still unsolved. In this work, we first find that such copying-style degeneration is primarily due to the weak likelihood objective, which allows the model to "cheat" the objective by merely duplicating knowledge segments in a superficial pattern matching based on overlap. To overcome this challenge, we then propose a Multi-level Adaptive Contrastive Learning (MACL) framework that dynamically samples negative examples and subsequently penalizes degeneration behaviors at both the token-level and sequence-level. Extensive experiments on the WoW dataset demonstrate the effectiveness of our approach across various pre-trained models.