 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLtri-LLM: Streaming Long Context Inference for LLMs with Training-Free Dynamic Triangular Attention Pattern
Dec 06, 2024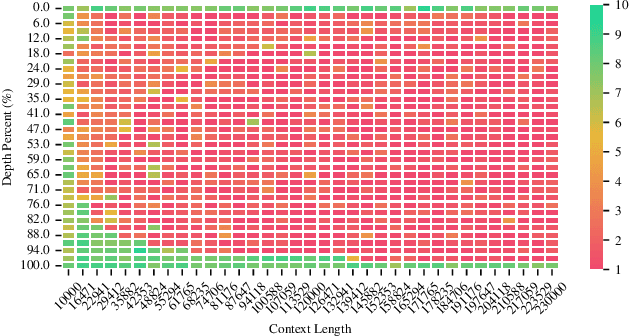

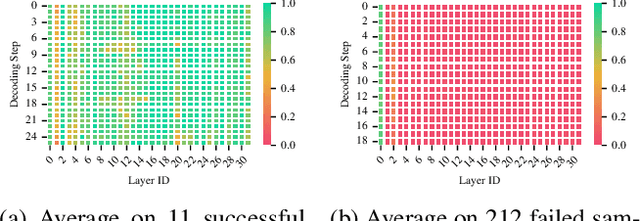

The quadratic computational complexity of the attention mechanism in current Large Language Models (LLMs) renders inference with long contexts prohibitively expensive. To address this challenge, various approaches aim to retain critical portions of the context to optimally approximate Full Attention (FA) through Key-Value (KV) compression or Sparse Attention (SA), enabling the processing of virtually unlimited text lengths in a streaming manner. However, these methods struggle to achieve performance levels comparable to FA, particularly in retrieval tasks. In this paper, our analysis of attention head patterns reveals that LLMs' attention distributions show strong local correlations, naturally reflecting a chunking mechanism for input context. We propose Ltri-LLM framework, which divides KVs into spans, stores them in an offline index, and retrieves the relevant KVs into memory for various queries. Experimental results on popular long text benchmarks show that Ltri-LLM can achieve performance close to FA while maintaining efficient, streaming-based inference.
NPSA: Nonorthogonal Principal Skewness Analysis
Jul 23, 2019

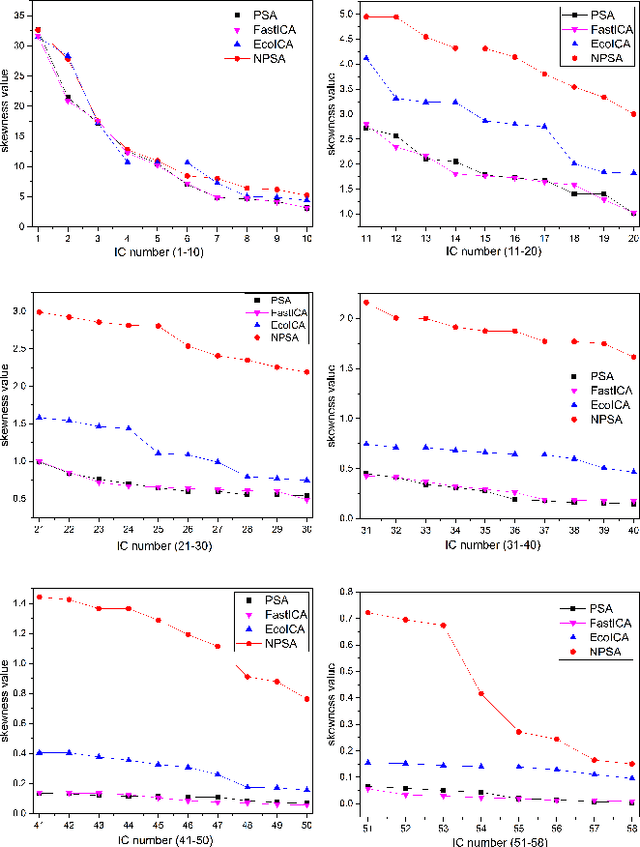
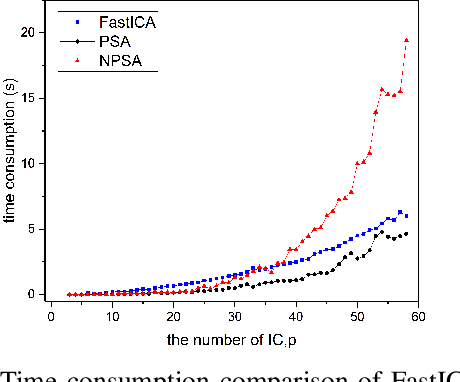
Principal skewness analysis (PSA) has been introduced for feature extraction in hyperspectral imagery. As a third-order generalization of principal component analysis (PCA), its solution of searching for the locally maximum skewness direction is transformed into the problem of calculating the eigenpairs (the eigenvalues and the corresponding eigenvectors) of a coskewness tensor. By combining a fixed-point method with an orthogonal constraint, it can prevent the new eigenpairs from converging to the same maxima that has been determined before. However, the eigenvectors of the supersymmetric tensor are not inherently orthogonal in general, which implies that the results obtained by the search strategy used in PSA may unavoidably deviate from the actual eigenpairs. In this paper, we propose a new nonorthogonal search strategy to solve this problem and the new algorithm is named nonorthogonal principal skewness analysis (NPSA). The contribution of NPSA lies in the finding that the search space of the eigenvector to be determined can be enlarged by using the orthogonal complement of the Kronecker product of the previous one, instead of its orthogonal complement space. We give a detailed theoretical proof to illustrate why the new strategy can result in the more accurate eigenpairs. In addition, after some algebraic derivations, the complexity of the presented algorithm is also greatly reduced. Experiments with both simulated data and real multi/hyperspectral imagery demonstrate its validity in feature extraction.
Probabilistic graphical model based approach for water mapping using GaoFen-2 (GF-2) high resolution imagery and Landsat 8 time series
Dec 22, 2016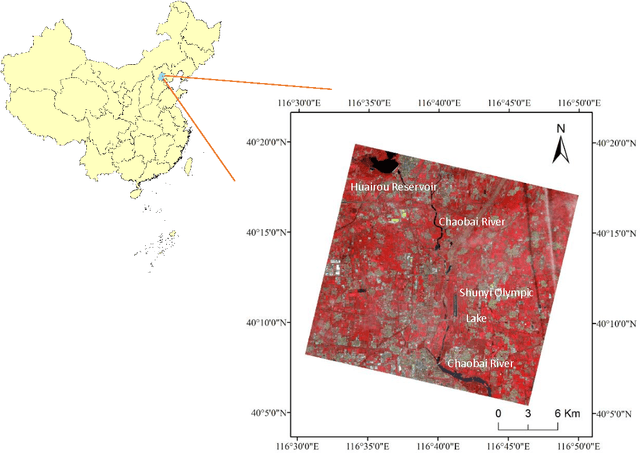


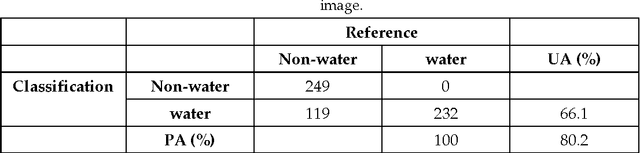
The objective of this paper is to evaluate the potential of Gaofen-2 (GF-2) high resolution multispectral sensor (MS) and panchromatic (PAN) imagery on water mapping. Difficulties of water mapping on high resolution data includes: 1) misclassification between water and shadows or other low-reflectance ground objects, which is mostly caused by the spectral similarity within the given band range; 2) small water bodies with size smaller than the spatial resolution of MS image. To solve the confusion between water and low-reflectance objects, the Landsat 8 time series with two shortwave infrared (SWIR) bands is added because water has extremely strong absorption in SWIR. In order to integrate the three multi-sensor, multi-resolution data sets, the probabilistic graphical model (PGM) is utilized here with conditional probability distribution defined mainly based on the size of each object. For comparison, results from the SVM classifier on the PCA fused and MS data, thresholding method on the PAN image, and water index method on the Landsat data are computed. The confusion matrices are calculated for all the methods. The results demonstrate that the PGM method can achieve the best performance with the highest overall accuracy. Moreover, small rivers can also be extracted by adding weight on the PAN result in PGM. Finally, the post-classification procedure is applied on the PGM result to further exclude misclassification in shadow and water-land boundary regions. Accordingly, the producer's, user's and overall accuracy are all increased, indicating the effectiveness of our method.
Clustering by connection center evolution
Oct 19, 2016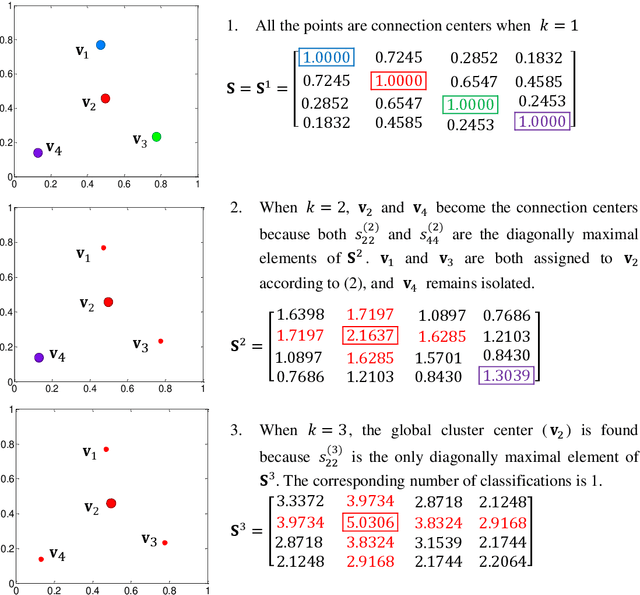
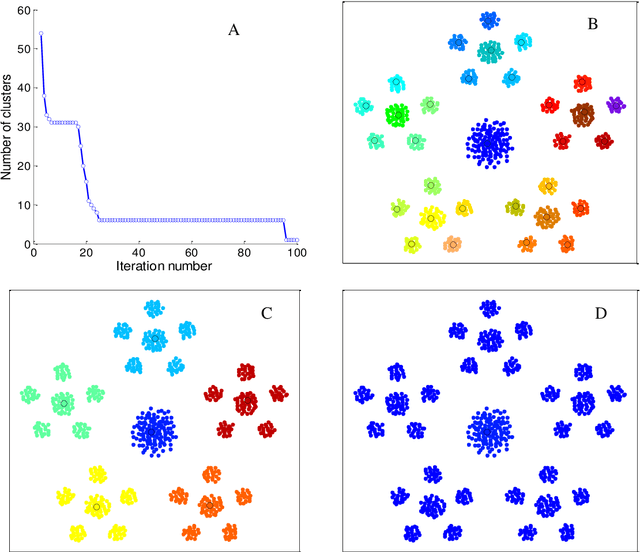
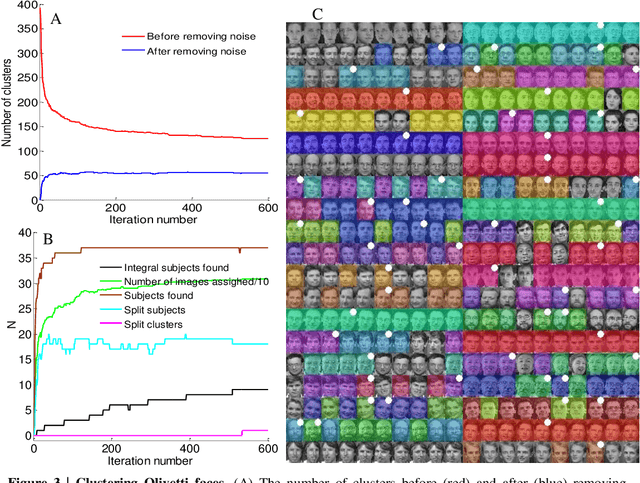
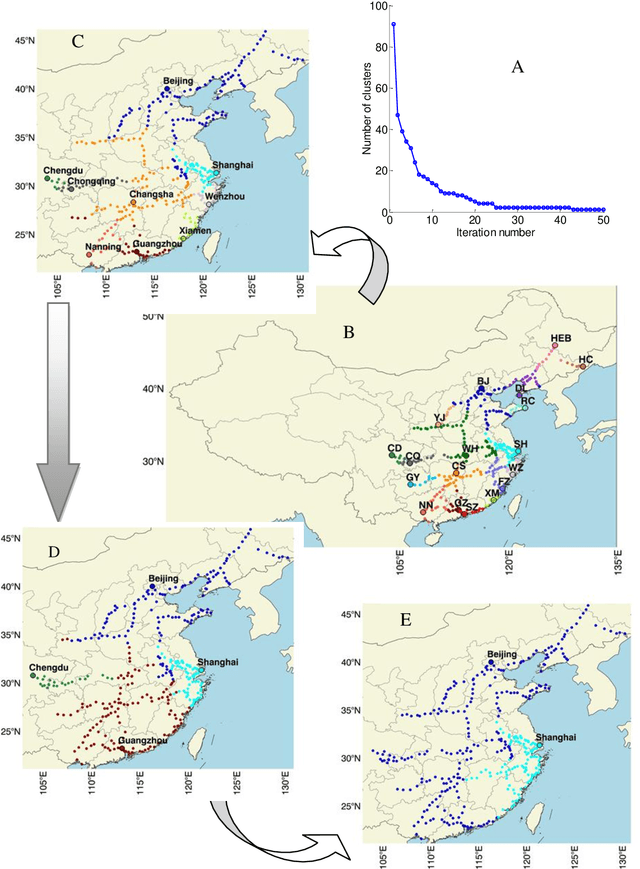
The determination of cluster centers generally depends on the scale that we use to analyze the data to be clustered. Inappropriate scale usually leads to unreasonable cluster centers and thus unreasonable results. In this study, we first consider the similarity of elements in the data as the connectivity of nodes in an undirected graph, then present the concept of a connection center and regard it as the cluster center of the data. Based on this definition, the determination of cluster centers and the assignment of class are very simple, natural and effective. One more crucial finding is that the cluster centers of different scales can be obtained easily by the different powers of a similarity matrix and the change of power from small to large leads to the dynamic evolution of cluster centers from local (microscopic) to global (microscopic). Further, in this process of evolution, the number of categories changes discontinuously, which means that the presented method can automatically skip the unreasonable number of clusters, suggest appropriate observation scales and provide corresponding cluster results.
An automatic bad band preremoval algorithm for hyperspectral imagery
Oct 19, 2016

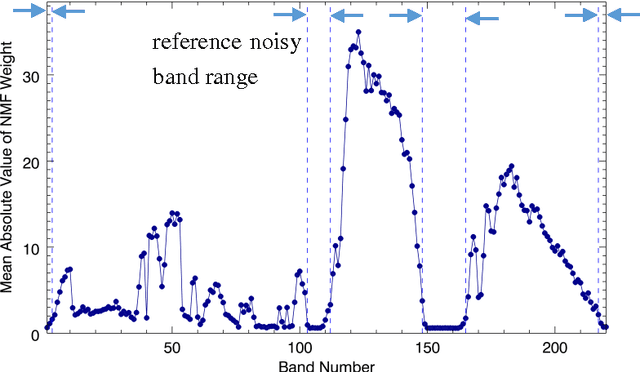

For most hyperspectral remote sensing applications, removing bad bands, such as water absorption bands, is a required preprocessing step. Currently, the commonly applied method is by visual inspection, which is very time-consuming and it is easy to overlook some noisy bands. In this study, we find an inherent connection between target detection algorithms and the corrupted band removal. As an example, for the matched filter (MF), which is the most widely used target detection method for hyperspectral data, we present an automatic MF-based algorithm for bad band identification. The MF detector is a filter vector, and the resulting filter output is the sum of all bands weighted by the MF coefficients. Therefore, we can identify bad bands only by using the MF filter vector itself, the absolute value of whose entry accounts for the importance of each band for the target detection. For a specific target of interest, the bands with small MF weights correspond to the noisy or bad ones. Based on this fact, we develop an automatic bad band preremoval algorithm by utilizing the average absolute value of MF weights for multiple targets within a scene. Experiments with three well known hyperspectral datasets show that our method can always identify the water absorption and other low signal-to-noise (SNR) bands that are usually chosen as bad bands manually.