 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClustering by connection center evolution
Paper and Code
Oct 19, 2016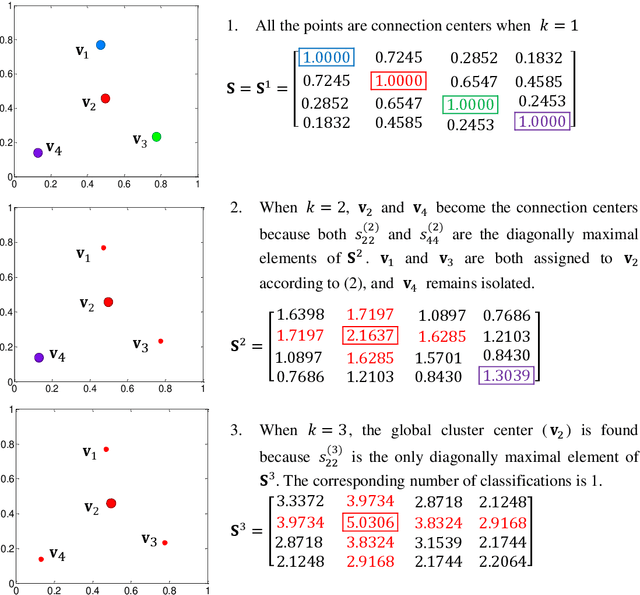
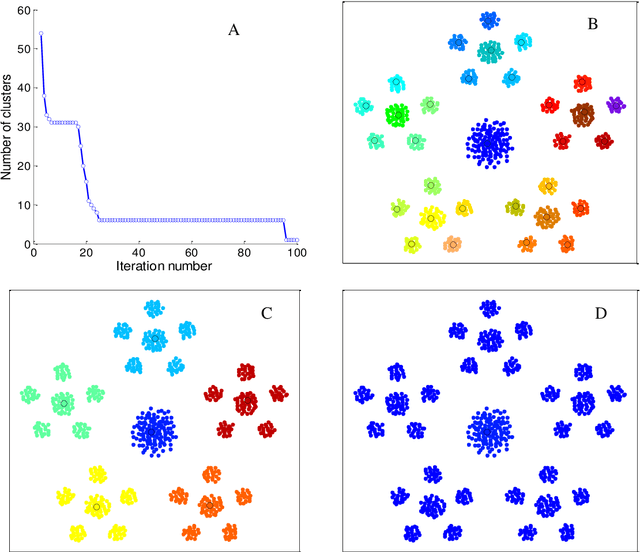
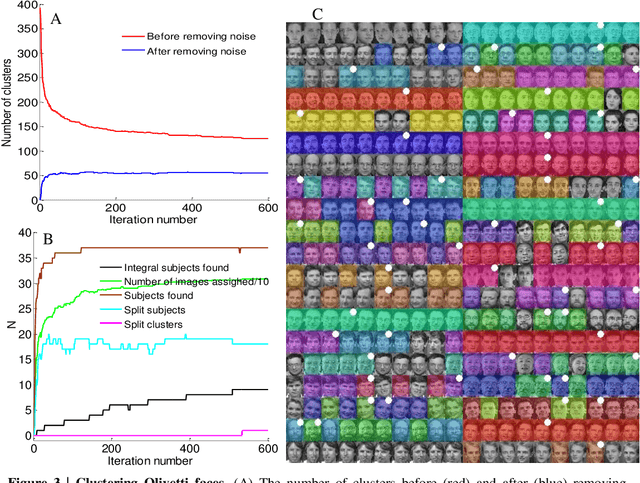
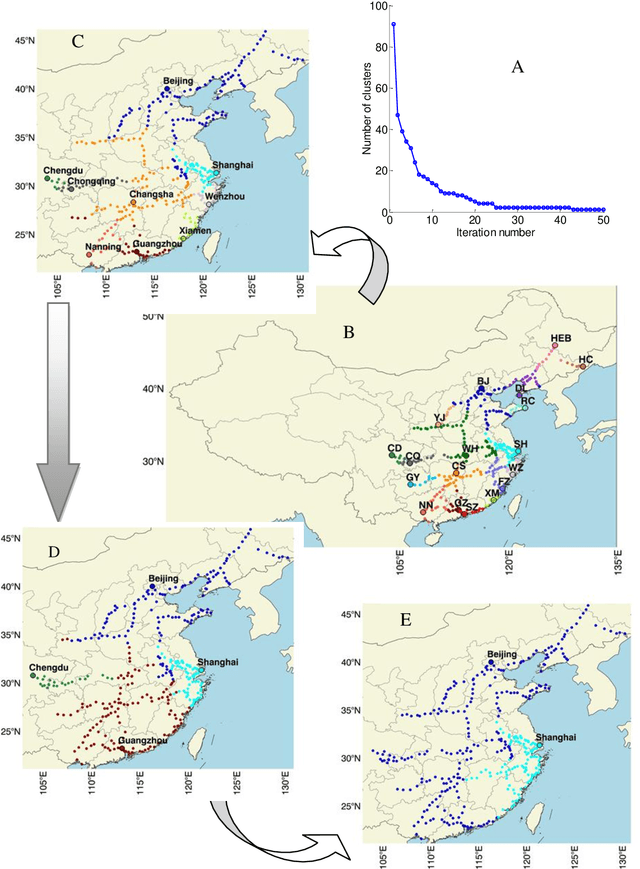
The determination of cluster centers generally depends on the scale that we use to analyze the data to be clustered. Inappropriate scale usually leads to unreasonable cluster centers and thus unreasonable results. In this study, we first consider the similarity of elements in the data as the connectivity of nodes in an undirected graph, then present the concept of a connection center and regard it as the cluster center of the data. Based on this definition, the determination of cluster centers and the assignment of class are very simple, natural and effective. One more crucial finding is that the cluster centers of different scales can be obtained easily by the different powers of a similarity matrix and the change of power from small to large leads to the dynamic evolution of cluster centers from local (microscopic) to global (microscopic). Further, in this process of evolution, the number of categories changes discontinuously, which means that the presented method can automatically skip the unreasonable number of clusters, suggest appropriate observation scales and provide corresponding cluster results.