Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA CLIP-Enhanced Method for Video-Language Understanding
Paper and Code
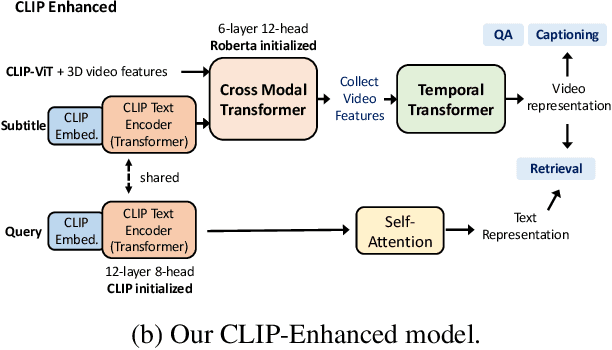
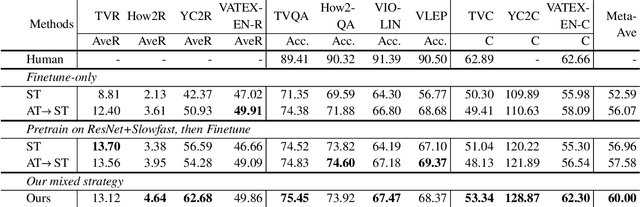
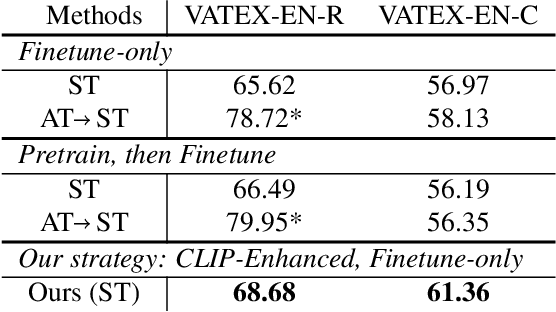
This technical report summarizes our method for the Video-And-Language Understanding Evaluation (VALUE) challenge (https://value-benchmark.github.io/challenge\_2021.html). We propose a CLIP-Enhanced method to incorporate the image-text pretrained knowledge into downstream video-text tasks. Combined with several other improved designs, our method outperforms the state-of-the-art by $2.4\%$ ($57.58$ to $60.00$) Meta-Ave score on VALUE benchmark.
* 3 pages, 1 figure, 2 tables. Technical report
View paper on